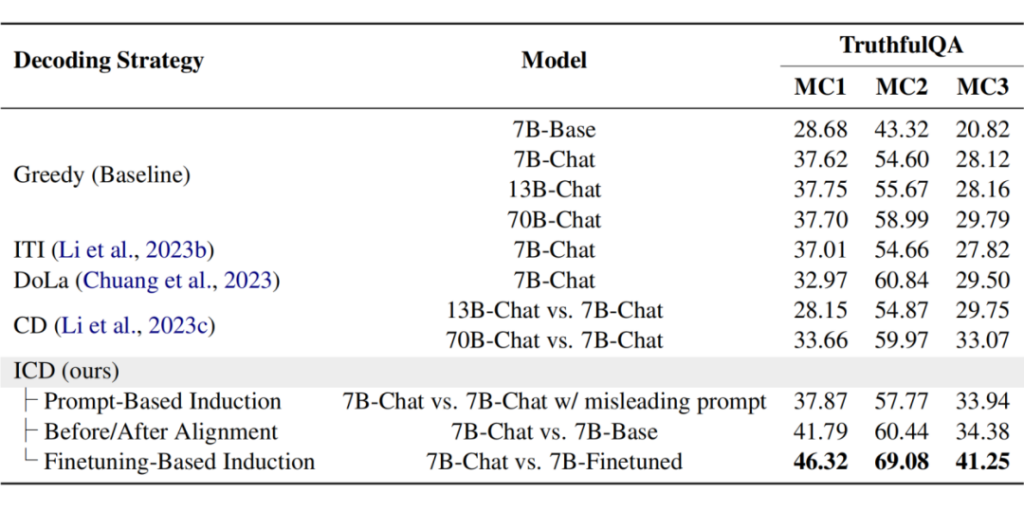
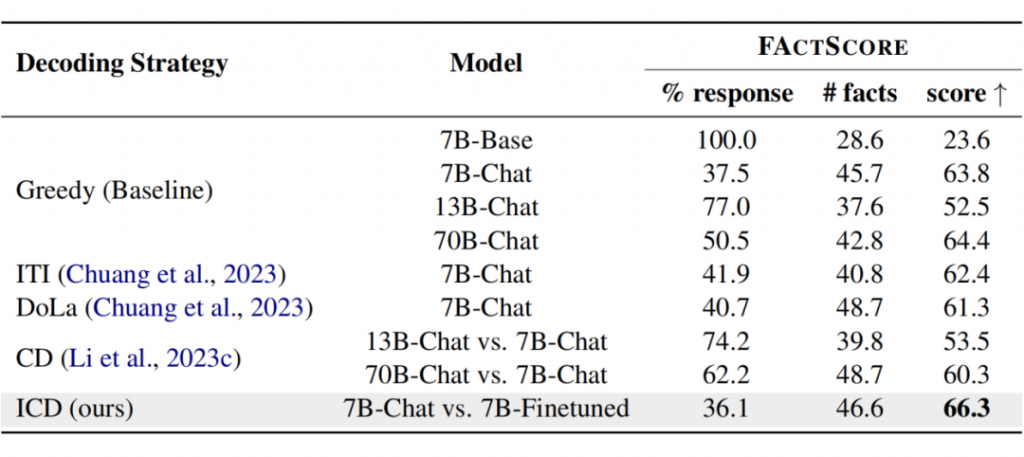
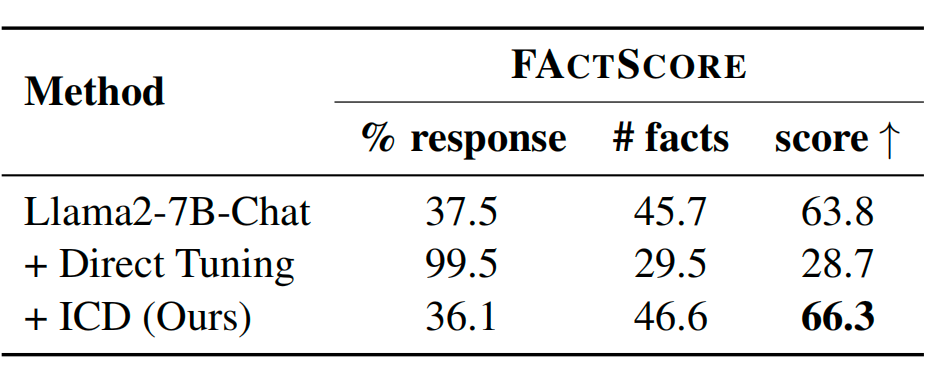
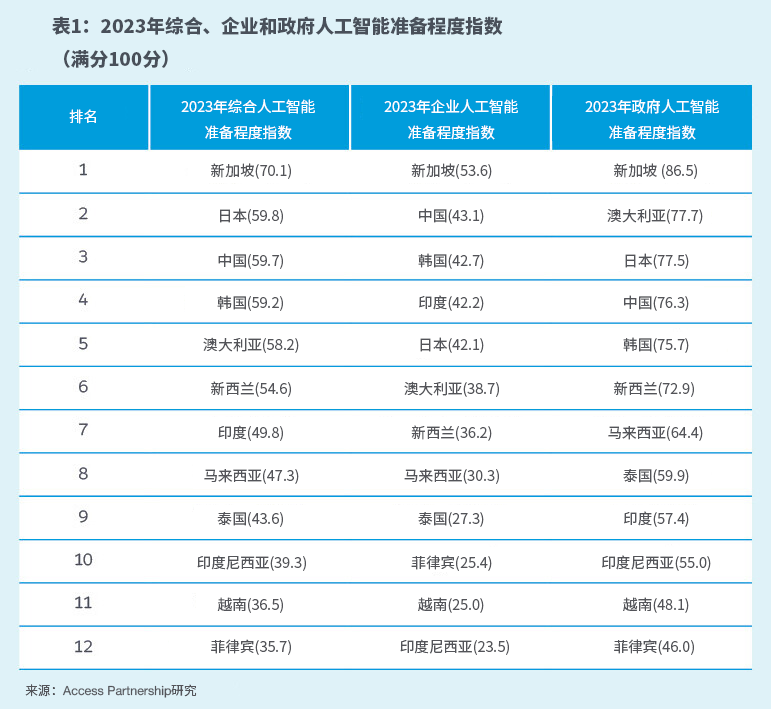
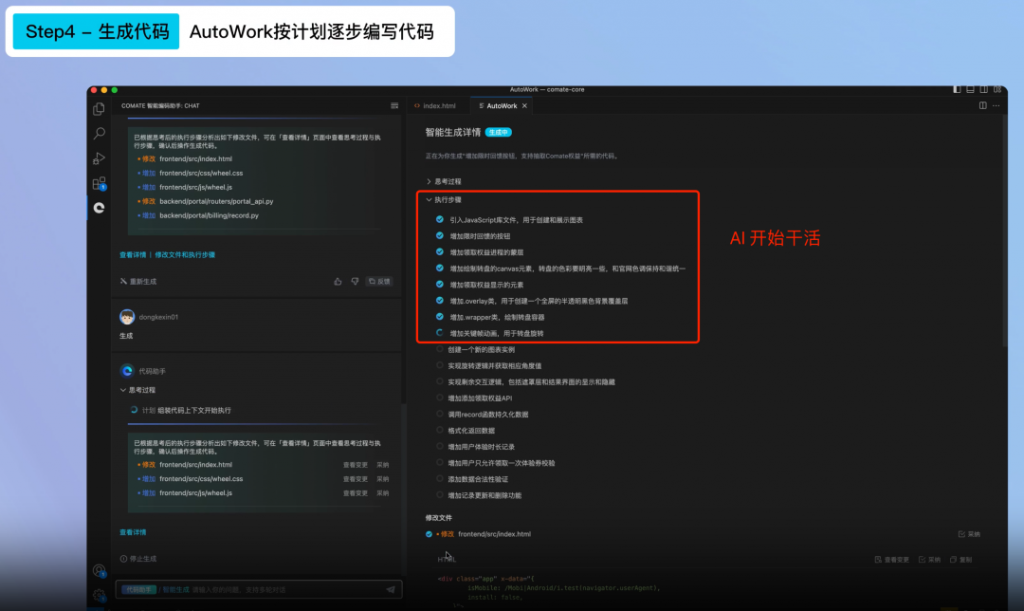
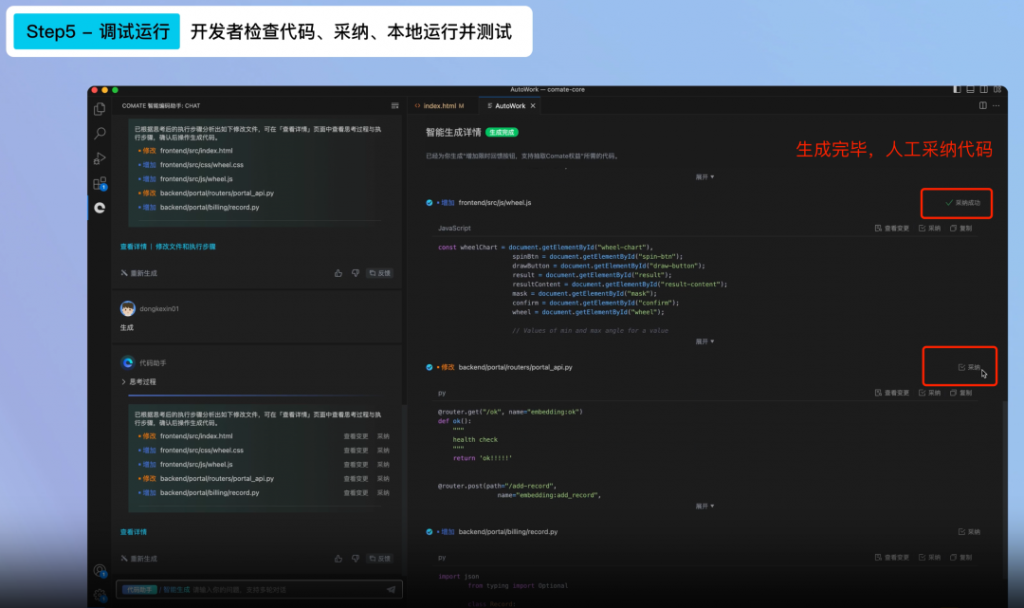
AI发展十大趋势:
一、大模型无处不在,成为数字系统的标配。
二、开源大模型将会爆发。
三、小模型会涌现,运行在更多终端。
四、大模型企业级市场崛起,向产业化、垂直化方向发展。
五、Agent智能体激发大模型智能,成为超级生产力工具。
六、2024年成为大模型应用场景之年,ToC出现杀手级应用。
七、2024年多模态会成为大模型标配。
八、文生图、文生视频等AIGC功能实现突破性增长。
九、具身智能赋能人形机器人产业蓬勃发展。
十、大模型将推动基础科学取得突破。
近日,360创始人周鸿祎在主题为“挺住才有出路“的一场演讲中,分享了以上对人工智能大模型的十大趋势判断和相关看法。
周鸿祎是中国互联网安全企业360集团创始人兼CEO,知名投资人、知名创业导师。其创立的360是最早布局大模型的国产厂商之一,“360智脑”也是国内首个原生安全大模型。
以下是整理的精华内容,分享给大家:
美国投资界把人工智能大模型看成是80年的PC,1995年的互联网,看成是工业革命的机会。而且他们还觉得,一旦美国在人工智能上形成了优势,对其他国家和全球竞争来说就属于降维打击。日本有失去的30年的原因在于,明确错过了电脑和互联网两大机会。而美国在电脑和互联网上成功实现了自己的升级。不管是创业者还是普通人,人工智能都能我们能碰到的最大机会。工业革命让所有行业都实现了洗牌,比如互联网对汽车工业的洗牌,特斯拉的出现改变了人们对于买车的想法。
人工智能会带来洗牌的机会
人工智能不仅是规模最大,也是速度最快的工业革命。如果这个世界亘古不变,那确实对大家来说没有什么机会。所以我觉得人工智能会带来洗牌的机会。
希望大家关注人工智能在2023年最大的突破,就是大语言模型实现了真正的人工智能,来到通用人工智能的拐点,而且在奔着强人工智能的方向,在飞快地一路狂奔,而且技术发展遥遥领先。大模型可能对我们国家,对我们的产业,对在座的各位来说,对创业者来说,可能都意味着不同的机会。
我讲一讲大模型的10个趋势。
趋势一:大模型无处不在,成为数字系统的标配。
我不认为大模型是操作系统。全世界的手机操作系统就鸿蒙、iOS、安卓三款,大模型更像当年的PC一样,未来会无处不在,成为整个企业数字化、政府数字化的标配。当年超级计算机的创造者说过一个断言,说计算机这东西,全世界就需要5台。
结果现实无情地打了他们的脸。今天有多少台电脑?在座的诸位家里至少摆着一台电脑,办公室一台笔记本,你们兜里还揣着一台电脑,因为你们的手机也是。所以大模型不会被垄断,不会说全中国人民、全世界人民都用一个公司的大模型。我认为大模型会无处不在。
趋势二:开源大模型将会爆发。
最早的大模型是闭源的,闭源刚出来的时候,我们一看OpenAI做的东西,感觉这就是「曼哈顿计划」,美国人把原子弹造出来了。后来发现,人家一开源,科技就进步,所以要感谢开源。现在国内也有很多开源的模型,就是基于国际开源的模型。所以开源大爆发之后,大模型就瞬间从原子弹变成白菜了。今年年初有人创业想搞原子弹,那到年尾,就发现自己做的是茶叶蛋的生意。
未来的矛盾不再是大模型本身怎么样,而是谁能够利用大模型结合自己的业务和场景,能够把它训练出自己所需的专属功能。
趋势三:小模型会涌现,运行在更多终端
有大必有小,阴阳是两个方面,一方面现在很多公司在思考,如何把模型进一步做大,从千亿的参数做到万亿的参数。但现在出来一个趋势:把模型做小,在十几亿、几十亿或者不超过100亿的模型上,效果也能差不多。
模型做小有两个前提,一个是模型做专业。模型什么都要会,那确实要很庞大,但如果这个模型就是写点东西,或者做点翻译,那专业的模型可以做小。做小还有一个好处,就是可以运行在更多的终端。像高通去年推的CPU,还有苹果推的CPU,都已经意味着在手机、Pad、电脑上,这种小参数的大模型已经可以跑起来。
2024年大模型一定会上车。因为车上有了大模型之后,车里那个对话助理才不会表现得像白痴一样,真正帮你解决很多问题。
趋势四:大模型企业级市场崛起,向产业化、垂直化方向发展。
大模型企业级市场在2024年会起来。虽然大家天天都在秀自己大模型的成绩,说你看我的会脑筋急转弯,我的会解小学奥数题,我的会写藏头诗,但玩多了发现跟业务毫无关系。2024年中国的toB业务,企业级市场会起来。大模型要走深度化、产业化、垂直化、深度定制的方向。
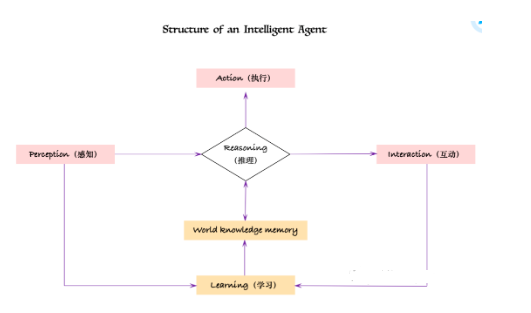
趋势五:Agent智能体激发大模型智能,成为超级生产力工具。
结合“智能体架构“,大模型长出手脚。第五个稍微偏点技术,OpenAI最近也在弥补,刚有了大模型的时候,大家觉得聊天机器人确实人机界面很简单,但做久了就发现,聊天机器人不太解决问题,仅仅是陪你聊天,最多就是一个PUA能手。
所以在2024年,一个新的概念叫「智能体架构」。英文叫Agent框架。大家要关注Agent,叫智能体概念。没有Agent框架,大语言模型几乎不能投入实用。
所以今年无论在做toC的业务,在做企业级的应用,大模型一定要结合智能体框架,才能真正让大模型长出手脚,让大模型真正跟你的业务系统,跟整个互联网充分打通。
趋势六:2024年成为大模型应用场景之年,ToC出现杀手级应用。
很多人都在问,在消费者端,大模型到底有啥杀手型的应用?中国会产生什么杀手级应用,我还不知道,但是2024年一定会出来。美国有三家公司很有意思,一家叫微软,一家叫Adobe,还有一家叫Salesforce,他们没有用大模型做任何新的东西,而都是把大模型跟已有的产品和场景做了一个充分的结合,就焕发了新生。
比如微软选择了Office、Bing和Edge浏览器;Adobe选择的是它擅长的图形编辑、视频编辑。所以我觉得大模型出来之后,在To C领域意味着,我们今天的搜索、浏览器、信息流、短视频、微博、问答,甚至我们的社交可能都会用大模型来重塑一遍。至于是战术性重塑还是战略性重塑,就看各家的做法,所以2024年一定会出来这种杀手级的应用。
趋势七:2024年多模态会成为大模型标配。
第七个预言,大模型在去年主要讲的是文字能力,写稿的能力。2024年,以Gemini和OpenAI的GPT-4V版本为代表,多模态会成为未来的标准。多模态不仅能听会说,关键是它能看得懂视频,能看得懂图片。
趋势八:文生图、文生视频等AIGC功能实现突破性增长。
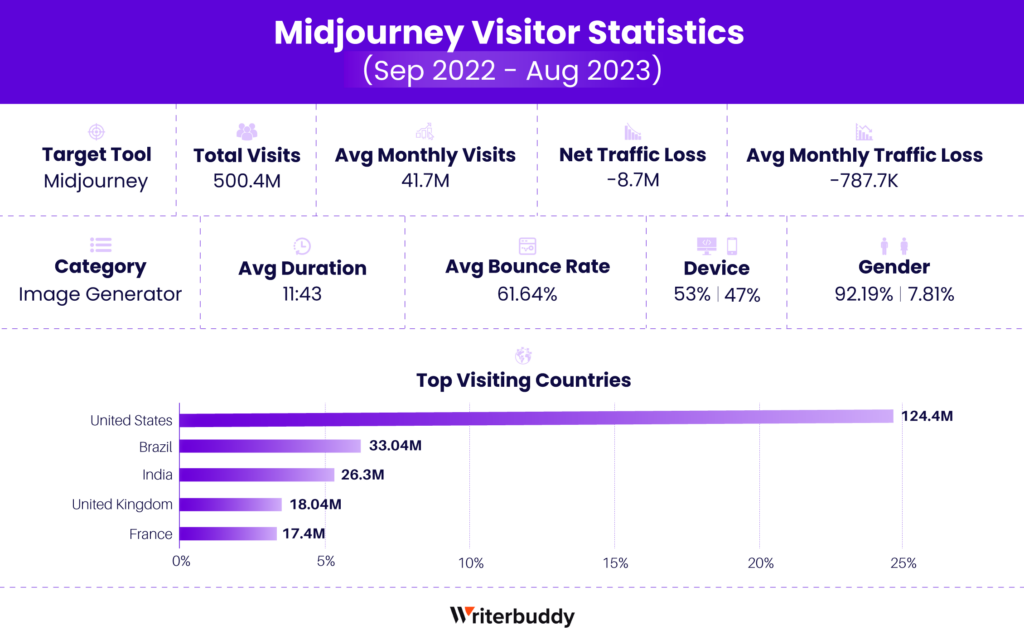
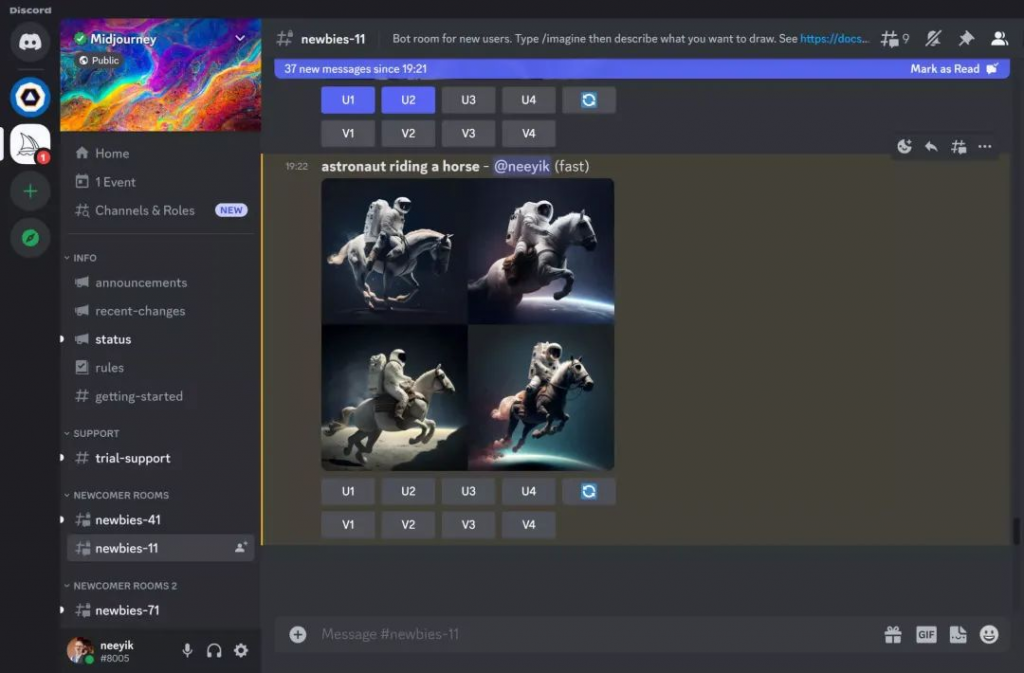
在大模型的支持下,AIGC会有突破性的增长。去年年初Midjourney画一张图,一看就是AI画的,经常把人画成6根手指。再到年底来看,计算机生图已经和摄影师的作品不相上下了。年初AI产生视频的能力,几乎都是动图、表情符号的能力,年底有的已经做得像好莱坞动画片了,所以这个进展特别快速。
趋势九:大模型拯救机器人行业。
大模型拯救了机器人行业。在大模型出来之前,传统的人形机器人是典型的智障产业——做得像人,但是能力极其低下,因为它不具备对这个世界知识的了解。但是有了大模型之后,机器人的产业获得了一个革命性的发展。这两天热炒的一个机器人,可以自动煎蛋,自动做家务,自动整理衣服,这完全有赖于大模型的加持。
趋势十:大模型将推动基础科学取得突破
为什么中国一定要做大模型?大模型不仅仅是语言工具,也不仅仅是聊天机器,大模型也不仅仅能在我们很多业务中发挥作用,其实大模型可能成为人类有史以来发明的最伟大的工具,成为很多科学家的工具。我们今天之所以能享受互联网,享受很多新能源,是因为前100年这个世界的物理学家取得了关键性的突破。
但在最近五六十年,人类在科技上已经很久没有突破,所以如果大模型能够成为科学家的工具,比如在美国,很多生物学家已经开始用大模型来帮助他们研究蛋白质的结构,研究分析基因。
所以我希望2024年,大模型能够推动基础科学取得突破,变成我们科技发展的利器。企业家要有AI信仰,抓住机会All in AI简单的建议是,你要有AI信仰,就是你要believe something,你要相信。
AI信仰怎么判断呢?很简单,我提了几个标准。
第一,在座的诸位可以回去扪心自问,你相不相信这次大模型是真的人工智能的拐点,还是不相信,认为是假的人工智能。
第二点,你相不相信它现在的发展速度会以指数级别发展;你相不相信它未来智力的发展速度会迅速超过我们人类;你相不相信它会是一场工业革命,在3-5年里,它会重塑我们每一位所在的行业,会重构我们的产品、业务链条和内部管理流程。
最后,除了重塑包括我们所有的产品和业务之外,还有你相不相信,你不会被大模型淘汰,但你会被那些用大模型的公司淘汰。
没有AI信仰的人看大模型,容易看不起,看不起是因为看不清,是因为心态的问题。因为看不起,所以也不愿意放下身段去琢磨,所以就看不懂,等到哪一天他们醒悟过来,已经看不见了,人家遥遥领先了。
第二个建议,就是要All in AI。什么叫All in AI呢?
真正的All in AI是你在公司里面,把信仰落实到行动中,在你的公司里让AI无孔不入。
比如说从上到下,组织里面从老板到你的中层干部,到你的员工,是否都在学习和使用AI?
还有我们有哪些业务流程可以被AI塑造?比如市场部是不是在用AI去做图?程序员是不是用AI编代码?HR是不是在用AI梳理简历?就是从小处着手,到公司内部。
还有要把产品重新思考一下,敢不敢做自我革命的事情,所谓”要想成功必先自宫”。你能不能把你的产品用AI去想,能够加持什么功能?
所以我觉得这是未来最大的一个机会。科技公司微软和Adobe,All in AI把已有产业用人工智能重做了一遍,都取得了很好的成绩。未来3-5年,如果不能用AI变成自己的武器,那么你的对手会对你造成降维打击。同样,AI虽然不会让你失业,但是会用AI的同事,会让不会用AI的同事失业。AI绝对是业务驱动的,只有在你公司从上到下、从内到外,让大家都对AI感兴趣,让业务专家都了解AI是怎么回事,我认为你才可能在未来这3-5年时间里,用AI来帮助你实现转型。
(来源:360创始人周鸿祎“挺住才有出路“的演讲)