
星辰AI大模型TeleChat-7B评测
0x0. 前言
受中电信 AI 科技有限公司的邀请,为他们近期开源的TeleChat-7B大模型做一个评测。

TeleChat-7B是由中电信 AI 科技有限公司发的第一个千亿级别大模型,基于transformer decoder架构和清洗后的1TB高质量数据训练而成,取得了相同参数量级别的SOTA性能,并且将推理代码和清洗后的训练数据都进行了开源。开源地址见:https://github.com/Tele-AI/Telechat 。此外,在开源仓库中也提供了基于DeepSpeed的LoRA微调方案以及国产化适配的训练和推理方案。本篇文章主要来体验一下这个模型,测试一下笔者比较关心的文学创作以及代码生成方面的效果。
0x1. TeleChat-7B开源亮点
TeleChat-7B最大的亮点在于其开源的全面性。首先,该项目不仅开源了1TB训练预料,而且还在仓库里开源了基于LoRA的详细微调方案,这为研究人员和开发者提供了极大的便利,让我们能够更好地理解和应用这个大模型模型。其次,TeleChat-7B展现了更好的硬件兼容性,提供了单卡、多卡以及多种低比特两湖呀的推理方案,这意味着它能够在不同的硬件配置下高效运行,满足不同用户的需求。
此外,TeleChat-7B在国产硬件适配方面也显示出了其开源诚意。特别是对国产芯片Atlas系列的支持,这不仅体现了技术上的包容性,也为国内的芯片技术提供了强有力的应用场景。
最后,我们可以从TeleChat-7B开源项目在文创方面展示的例子看到它具有不错的文创能力和一定的代码能力,可以作为开发者来使用的一个不错的基础大模型。如果想了解更多的技术细节可以阅读官方放出的技术报告:https://arxiv.org/abs/2401.03804 。
0x2. 环境配置
可以使用官方提供的Docker镜像,也可以自己按照 https://github.com/Tele-AI/Telechat/blob/master/requirements.txt 来配置。我这里是直接使用了官方的镜像,基本没踩什么坑,按照 https://github.com/Tele-AI/Telechat/blob/master/docs/tutorial.md 这个教程操作就可以。
0x3. 文学创作能力测试
为了更加真实的观察模型的文学创作能力,这里不使用TeleChat-7B官方开源仓库提供的例子,而是使用我们自己的一些prompt来进行测试。其中部分例子取自:https://github.com/SkyworkAI/Skywork#chat%E6%A8%A1%E5%9E%8B%E6%A0%B7%E4%BE%8B%E5%B1%95%E7%A4%BA 。
诗词创作
我也测试了一些其它的诗词创作的prompt,比如”尝试写一首五言绝句,描绘一只小猫在家中嬉戏的情景。’, ‘写一首简单的五言绝句,描绘一朵盛开的向日葵。”,模型的输出为:
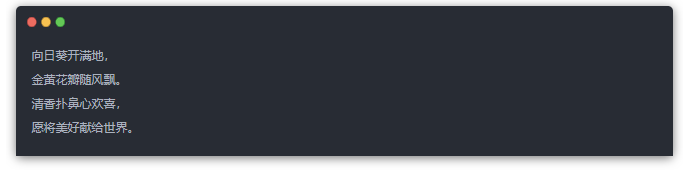
发现TeleChat-7B模型在诗词创作方面的能力有限,虽然可以生成一些和prompt描述相关的文字,但是对五言,七言等诗歌形式往往不能正常理解。
总的来说,TeleChat-7B具有一定的文创能力和代码能力,对于本次测试的大多数prompt可以生成较为合理的答案。但模型本身也存在大模型幻觉,指令跟随能力一般以及回答有概率重复的问题。但由于TeleChat模型的训练Token相比于主流模型已经比较少了,只有1.0T数据,所以相信上述问题通过更多高质量的数据以及PPO等训练可以进一步被缓解。此外,TeleChat-7B在开源方面是相当有诚意的,将清洗之后的训练数据进行开源是在之前的大模型开源中比较难见到的,如果想了解更多的数据清洗细节以及模型训练的细节可以阅读官方放出的技术报告:https://arxiv.org/abs/2401.03804。