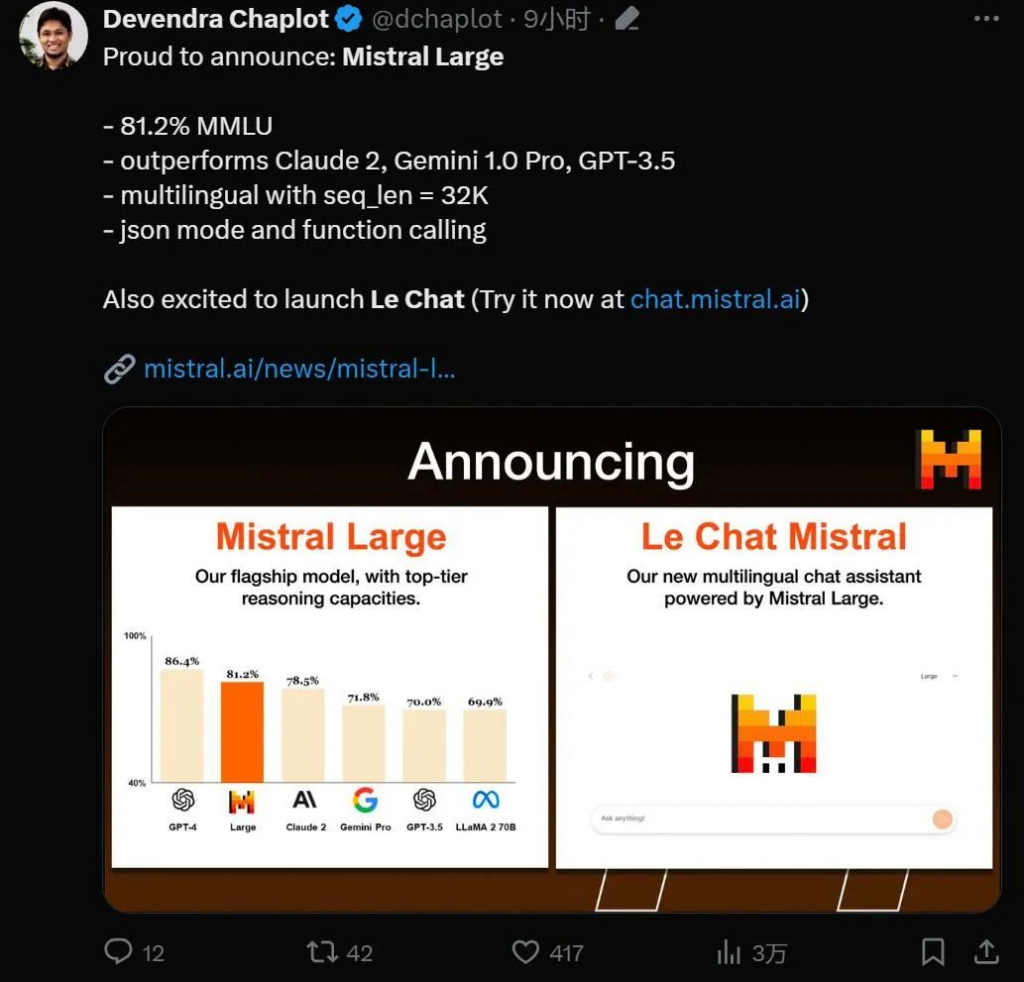
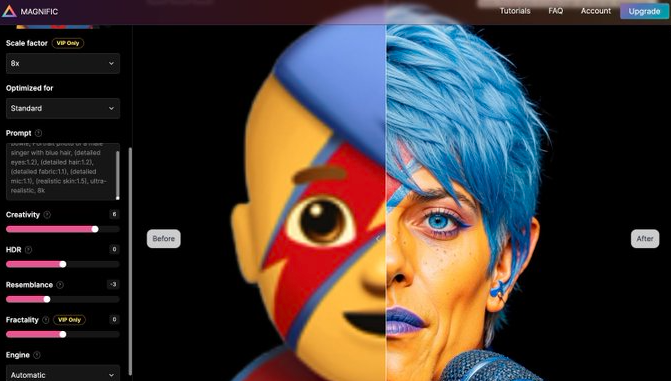
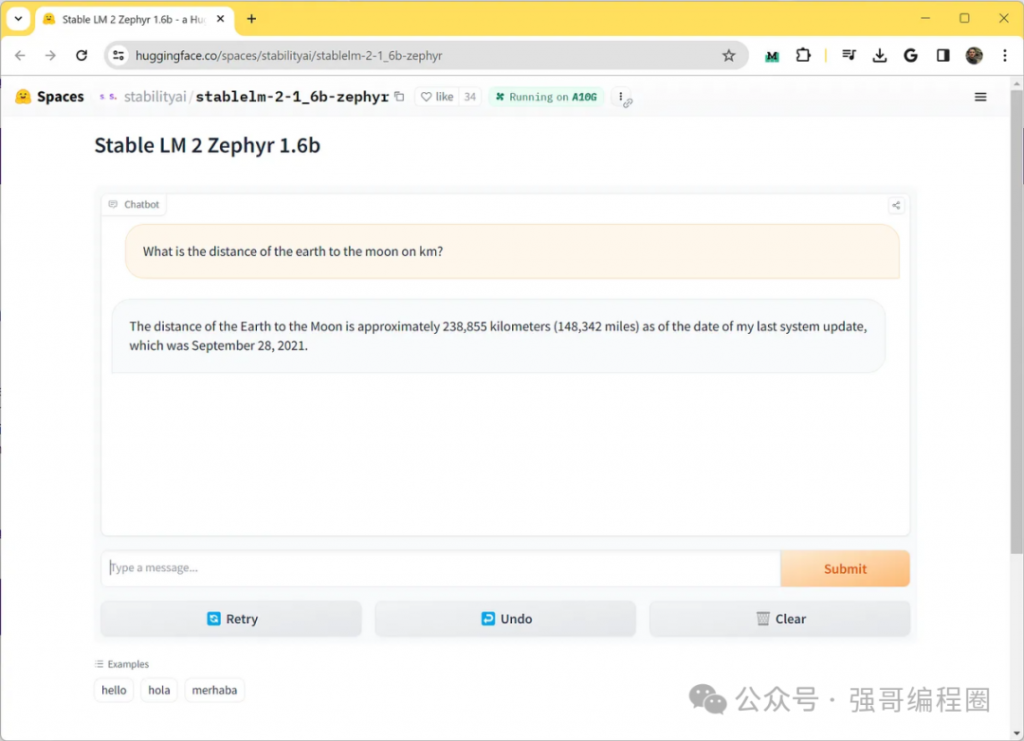
生成式 AI 领域,又有重量级产品出现。 周一晚间,Mistral AI 正式发布了「旗舰级」大模型 Mistral Large。与此前的一系列模型不同,这次 Mistral AI 发布的版本性能更强,体量更大,直接对标 OpenAI 的 GPT-4。而新模型的出现,也伴随着公司大方向的一次转型。 随着 Mistral Large 上线,Mistral AI 推出了名为 Le Chat 的聊天助手(对标 ChatGPT),任何人都可以试试效果。
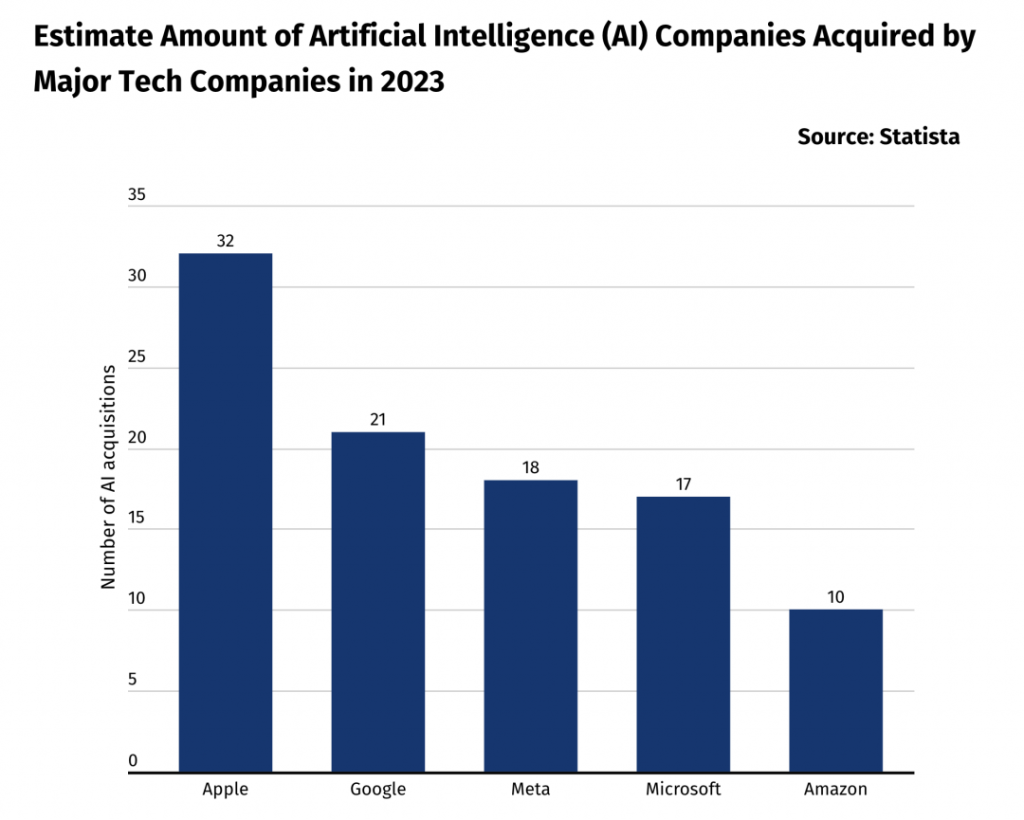
试用链接:https://chat.mistral.ai/ 此前,Mistral AI 提出的 Mistral-Medium 因为强大的性能、「意外」的开源而名噪一时,目前很多大模型初创企业都已不再对标 Llama 2,而是将 Mistral AI 旗下模型作为直接竞争对手。此次 Mistral Large 的出现,自然迅速吸引了众人关注。 人们首先关注的是性能,尽管在参数数量上不及 GPT-4,Mistral-Large 在关键性能方面却能与 GPT-4 媲美,可以说是当前业内的前三:
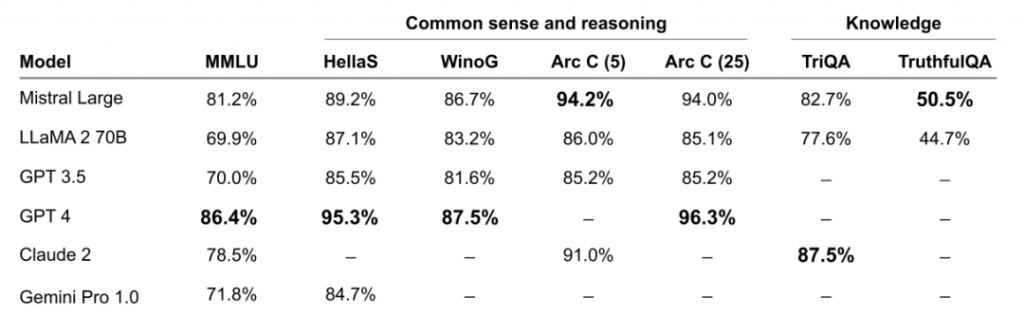
Mistral Large 的推理准确性优于 Claude 2、Gemini 1.0 Pro、GPT-3.5,支持 32k token 的上下文窗口,支持精确指令,自带函数调用能力。 人们也发现 Mistral Large 的推理速度超过了 GPT-4 和 Gemini Pro。然而优点到此为止。 模型除了增加体量,也需要有相应的数据。在模型发布后,人们发现它生成的文本有一种 ChatGPT 的既视感。
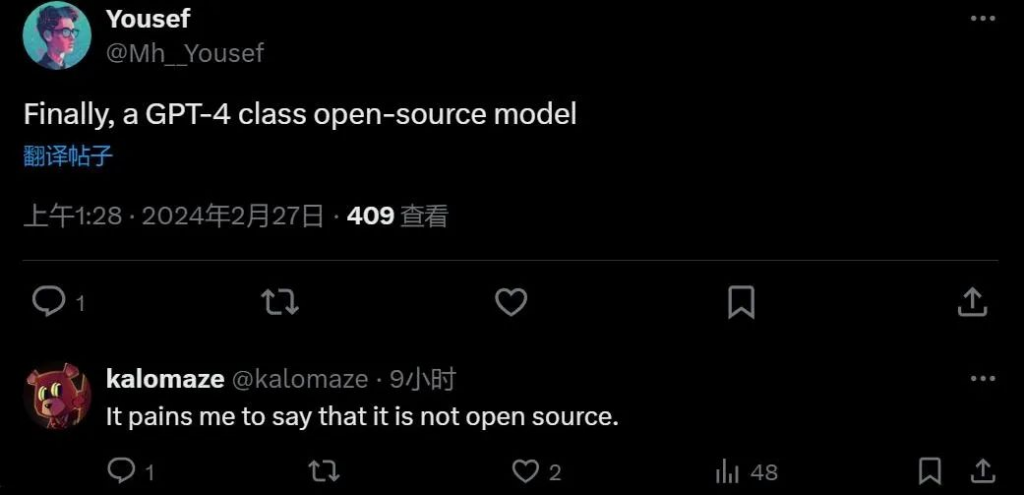
如果说为了能赶上业内最先进的 GPT-4,使用 AI 生成的内容进行训练或许并不是什么大问题。但 Mistral Large 的出现也给 AI 社区的人们带来了危机感:它并不是一个开源大模型。
这次发布的大模型有跑分,有 API 和应用,就是不像往常一样有 GitHub 或是下载链接。 有网友发现,新模型发布后,Mistral AI 官网还悄悄把所有有关开源社区义务的内容全部撤掉了:
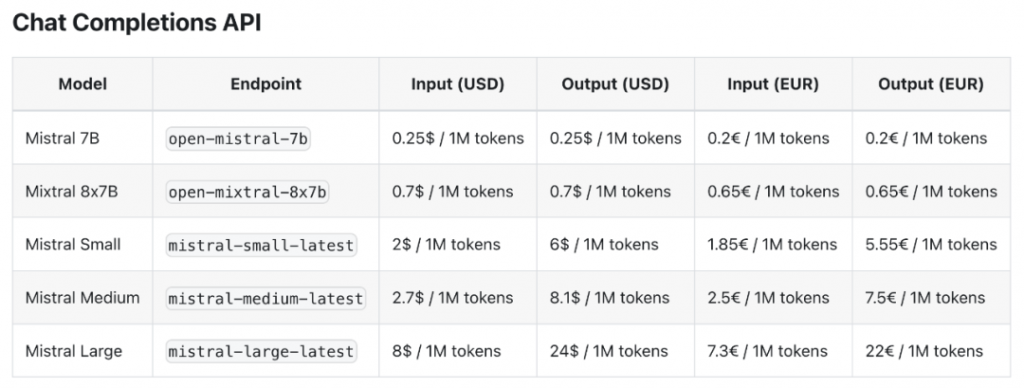
难道以开源起家的 Mistral AI,成立才不足一年,这就要转向了吗? Mistral Large 目前已经能在 Mistral AI 自有平台 La Plateforme 和微软 Azure 上使用。除了 Mistral Large 之外,Mistral AI 还发布了新模型 Mistral Small,针对延迟和成本进行了优化。Mistral Small 的性能优于 Mixtral 8x7B,并且推理延迟得到了降低,提供了一种开放权重模型和旗舰模型之间的中间方案。 但模型的定价也引发了一些质疑。比如 Mistral Small 的低延迟相比于 Mixtral 8x7B 的提升微乎其微,但输入贵了 2.8 倍,输出贵了 8.5 倍:
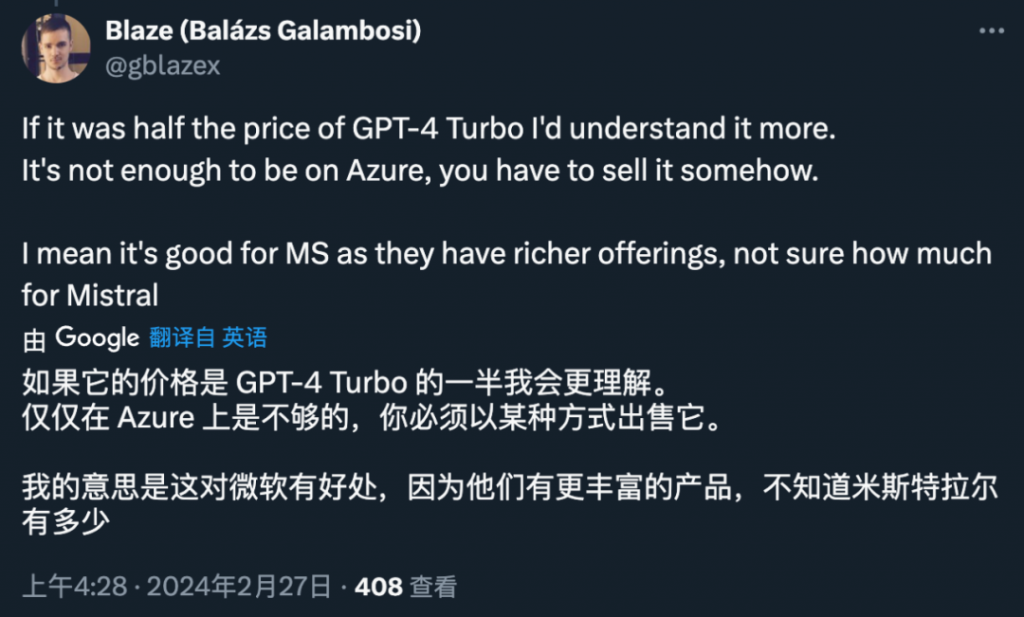
如果以商业大模型的标准来看待,Mistral Large 的定价和 GPT-4 相比并不具备优势,这又该如何吸引客户呢?
这位业内人士表示:「如果它的价格是 GPT-4 Turbo 的一半,我会更理解。」
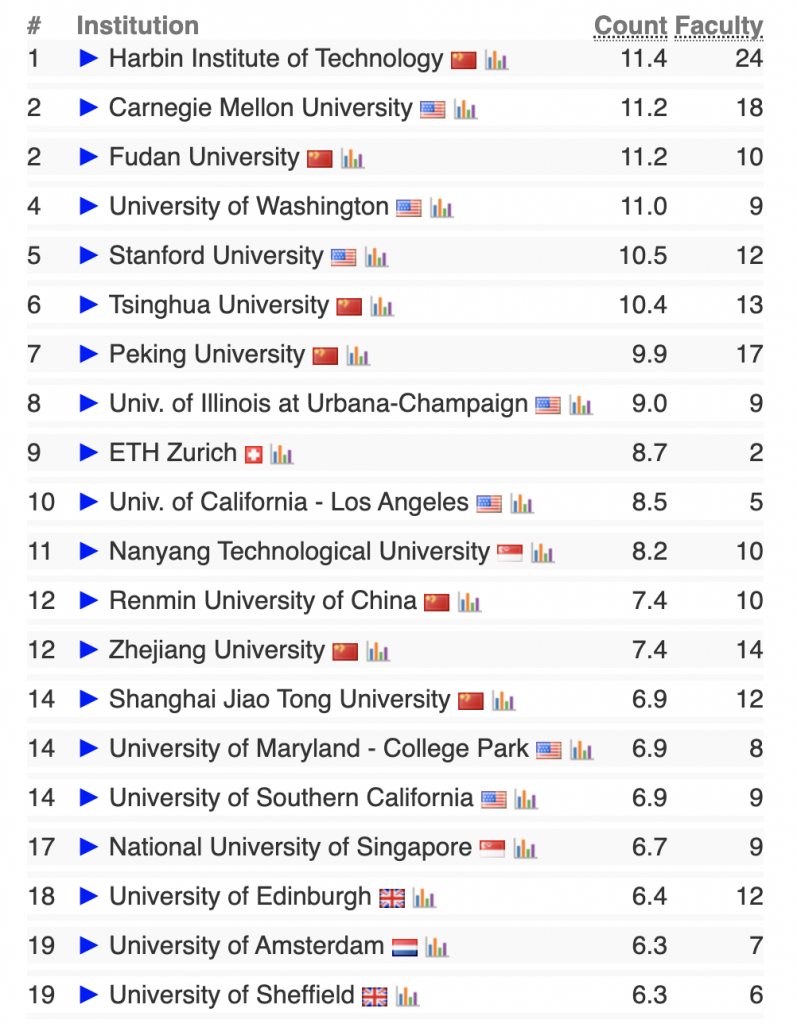
新的 Mistral AI「大杯」模型,表现如何? 在官方博客中,Mistral AI 详细介绍了 Mistral Large 的功能和优势: Mistral Large 在多个常用基准测试中取得了优异的成绩,使其成为世界上排名第二的可通过 API 普遍使用的模型(仅次于 GPT-4):
与微软合作,行 OpenAI 故事 在发布 Mistral Large 等模型的同时,Mistral AI 还宣布了一个消息:将与微软合作,在 Azure 上提供自己的模型。 此次合作使 Mistral AI 成为第二家在微软 Azure 云计算平台上提供商业语言模型的公司。这有助于 Mistral AI 将自己的模型推向市场,也让 Mistral AI 有机会使用 Azure 的尖端 AI 基础设施,以加速其下一代大型语言模型的开发和部署。
这家公司表示,「在 Mistral AI,我们的使命是让前沿人工智能无处不在。这就是我们今天宣布将自己的开放和商业模型引入 Azure 的原因。微软对我们模型的信任让我们前进了一步!」 这项为期多年的协议标志着微软正在其最大的赌注 OpenAI 之外,努力提供各种人工智能模型,为其 Azure 云服务吸引更多客户。去年 11 月,OpenAI 经历了 CEO Altman 被解雇(后又重返)的风波。而作为最大的股东,微软在消息公布前 5 到 10 分钟才从 OpenAI 那里得到消息。在这次动荡后,微软设法在控制 OpenAI 的非营利性董事会中获得了一个无投票权的观察员席位。这让他们对 OpenAI 的内部运作有了更多了解,但在重大决策上,微软依然没有投票权。 Mistral AI 对路透社表示,作为交易的一部分,微软将持有该公司少数股权,但未透露细节。 微软证实了对 Mistral AI 的投资,但表示不持有该公司的股权。这家科技巨头因向 OpenAI 提供巨额资金而受到欧洲和美国监管机构的审查。 根据公告,微软与 Mistral AI 的合作主要集中在三个核心领域:
超算基础设施:微软将通过 Azure AI 超级计算基础设施支持 Mistral AI ,为 Mistral AI 旗舰模型的 AI 训练和推理工作负载提供一流的性能和规模;
市场推广:微软和 Mistral AI 将通过 Azure AI Studio 和 Azure 机器学习模型目录中的模型即服务(MaaS)向客户提供 Mistral AI 的高级模型。除 OpenAI 模型外,模型目录还提供了多种开源和商业模型。
人工智能研发:微软和 Mistral AI 将探索为特定客户训练特定目的模型的合作。
除了微软,MistralAI 还一直在与亚马逊和谷歌合作,分销自己的模型。一位发言人表示,该公司计划在未来几个月内将 Mistral Large 应用于其他云平台。 Mistral AI 成立于 2023 年 5 月,由来自 Meta Platforms 和 Alphabet 的几位前研究人员 ——Arthur Mensch(现任 CEO)、Guillaume Lample 和 Timothee Lacroix 共同创立。成立不到四周,Mistral AI 就获得了 1.13 亿美元 的种子轮融资,估值约为 2.6 亿美元。成立半年后,他们在 A 轮融资中筹集了 4.15 亿美元,估值飙升至 20 亿美元,涨了七倍多。而此时,他们仅有 22 名员工。
2 月 16 日 OpenAI 发布了一个新的 AI 视频生成模型 Sora,它可以根据文本生成 60s 的高质量视频,完全突破了之前 AI 文生视频存在的各种局限,所以一出现就引起广泛关注和热烈讨论,大家应该对它都有所了解。
今天就根据网上已公布的视频,对 Sora 的功能特性进行一个盘点总结,其中包含与 Runway、Pika 等 AI 视频工具的生成效果对比,让大家对 Sora 的能力有一个更直观全面的了解。
一、60s 超长视频
之前优设已经推荐过 AI 视频工具,比如 Runway、Pika、MoonVally、Domo AI、AnimateDiff、Stable Video 等,它们文生视频长度都在 3-7 秒之间(Aminatediff 和 Deforum 因形式不同,不列入此处的比较),而 Sora 直接将时长最高提升到 60s,是之前的 10 倍,这样的长度是放在之前大家可能觉得要好几年才能实现,但是 Sora 让其一夜之间成为现实。
二、超高的文生视频质量
接触过 AI 视频生成的小伙伴肯定清楚,文本生成的视频效果最难控制,很容易出现画面扭曲、元素丢失情况,或者视频根本看不出动态。所以不少 AI 视频工具都转向在图生视频或者视频转绘上发力,比如 Runway 的 Motion Brush 笔刷,通过在图像上涂抹指定区域添加动效;以及 Domo AI,可以将真实视频转为多种不同的风格,这些方式让 AI 视频更可控,因此质量更好。
而 Sora 的出现则完全颠覆了人们对文生视频的认知,不仅直接能通过文本生成各种风格的高清的视频,还支持多样化的视频时长、分辨率和画幅比,并且能始终保持画面主体位于视频中央,呈现出最佳构图。
三、连贯一致的视频内容
Sora 生成的视频中,随时长增加人物及场景元素依旧能保持自己原有原有的状态,不会扭曲变形,所以视频前后连贯性非常好。即使元素被遮挡或者短暂离开画面,Sora 依旧能在后续准确呈现这一对象的相关特征。
Sora 能针对一个场景或者一个主题进行多视角呈现,比如针对“下雪天的街道”主体,可以同时生成手部玩雪特写、街道元素特写、行人走动中景、街道全景等分镜。
下面是从 Sora 视频中截取一段,可以看到随着镜头旋转,新视角中无论是机器人还是背后环境的细节都能稳定呈现,如同 CG 建模一样精准。之前为大家介绍过 Stable zero 123,一种可以生成多视角图像的 AI 模型,但效果远比不上在视频中的呈现,也许 Sora 能为我们提供一种生成角色三视图的新方法。
五、自然流畅的动态
推特网友 @Poonam Soni 制作的了几组 Sora 与 Runway 的效果对比。无论是小狗打闹、云朵的飘动还是袋鼠跳舞,Sora 的动态都非常自然,就像我们在现实中看到的那样;相比之下 Runway 生成的动作总有一种 “慢放”的感觉,不够自然。
2024年,AI落地的重点是如何与用户一起成长。”一个通过找对场景,顺利在模型层占有一席之地的典型案例,是估值达5.2亿美元的AI公司Perplexity。Perplexity通过将大模型和搜索引擎结合,开发出了类似于New Bing的对话式搜索引擎。不过,Perplexity的模型,最初是基于一些规模更小、推理更快的模型进行微调而来。直到最近,他们才开始训练自己的模型。对于前期“套壳”的决定,Perplexity CEO Aravind Srinivas在播客节目中锐评:“成为一个拥有十万用户的套壳产品,显然比拥有自有模型却没有用户更有价值。”
同一天,魅族也官宣重磅消息。据“魅族科技”官微消息,魅族今日决定,将All in AI,停止传统“智能手机”新项目,全力投入明日设备AI For New Generations。2024年魅族面向AI时代全新打造的手机端操作系统将进行系统更新。此外,魅族首款AI Device硬件产品也将在今年内正式发布。
魅族称,经过两年的团队磨合、资源配置、产品布局以及相关技术的充分预研,魅族目前已具备向AI领域全面转型的能力。作为一家全面发展的科技生态公司,魅族拥有完善的研发和供应链等硬件团队,同时还拥有体系化开发、设计、交互的软件团队,这将为魅族All in AI提供坚实的技术支持和服务保障。
在本次AI发布会上,魅族同时公布了AI战略规划的详细内容,包括打造AI Device产品、重构Flyme系统和建设AI生态。魅族将通过三年的生态布局和技术沉淀,逐步完成All in AI愿景。按照规划,2024年魅族面向AI时代全新打造的手机端操作系统将进行系统更新,构建起AI时代操作系统的基建能力;此外,魅族首款AI Device硬件产品也将在今年内正式发布,并与全球顶尖的AI Device厂商展开正面竞争。
考虑到新老用户的过渡需求,在魅族All In AI过渡期内,原魅族Flyme、Flyme Auto、Flyme AR、MYVU、PANDAER以及无界智行业务的用户体验及服务将不会受到影响。另外,现有在售的魅族手机产品将继续为用户提供正常的软硬件维护服务。已购买的魅族20系列、魅族21旗舰手机的用户,仍将享受原有的售后及相关服务保障。
随着人工智能技术的不断发展,聊天机器人已经成为我们生活中的一部分。而英伟达近日推出的Chat With RTX,给这个领域注入了新的活力。与传统的网页或APP聊天机器人不同,Chat With RTX需要安装到个人电脑中,并且采用本地运行模式。这种创新不仅提高了运行效率,还可能意味着对聊天内容没有那么多限制。
借助开源LLM支持本地运行
Chat With RTX并非是英伟达自己搞了个大语言模型,而是基于两款开源LLM,即Mistral和Llama 2。这两款模型提供了强大的语言理解和生成能力,用户可以根据自己的喜好选择使用。
上传本地文件提问,支持视频回答
Chat With RTX的功能也相当丰富。用户可以上传本地文件提问,支持的文件类型包括txt,.pdf,.doc/.docx和.xml。而且,它还具备根据在线视频回答问题的能力。这些功能的实现得益于GPU加速,使得答案生成速度飞快。
功能强大,但也存在一些问题
然而,即使Chat With RTX功能强大,也并非没有短板。在处理大量文件时,它可能会出现崩溃的情况。而且,它似乎无法很好地记住上下文,导致后续问题不能基于前面的对话进行。
优异的本地文档搜索与文件安全性
尽管存在一些问题,但Chat With RTX在搜索本地文档方面表现优异。其速度和精准度让人印象深刻。此外,由于是本地运行,用户的文件安全性也得到了保障。
结语
总的来说,英伟达Chat With RTX的推出为聊天机器人领域带来了新的可能性。虽然存在一些问题,但其本地运行模式和强大的功能仍然值得期待。随着技术的不断进步,相信Chat With RTX在未来会有更加出色的表现。
TeleChat-7B是由中电信 AI 科技有限公司发的第一个千亿级别大模型,基于transformer decoder架构和清洗后的1TB高质量数据训练而成,取得了相同参数量级别的SOTA性能,并且将推理代码和清洗后的训练数据都进行了开源。开源地址见:https://github.com/Tele-AI/Telechat 。此外,在开源仓库中也提供了基于DeepSpeed的LoRA微调方案以及国产化适配的训练和推理方案。本篇文章主要来体验一下这个模型,测试一下笔者比较关心的文学创作以及代码生成方面的效果。
3)在Android上,用户可以选择使用 Gemini 可以替代原来的 Google Assistant,成为手机的默认语言助手;
4)在谷歌官方会员计划 Google One 中加入 Gemini Advanced 服务,多付 10 美元即可访问最强大的 Gemini Ultra 模型;
5)大模型能力很快将接入 Google Workspace(包括 Gmail、Docs、Meet 等应用)和 Google Cloud 中。
此次谷歌不仅直接推出了大模型面向 C 端的 App,同时将内部的多个产品线接入大模型,可以说向技术的公开化迈进了一大步。当问及为何选择推出面向公众的产品,谷歌产品管理高级总监、Gemini 体验官 Jack Krawczyk 对极客公园说,「我们谈论 Gemini,不仅仅是在谈(谷歌)最先进的技术,更是谈论一种生态系统的转变。」
2 月 8 日 21 点,谷歌推出 Gemini 的 Android 版 App,并将 Gemini 的能力加入 iOS 的 Google App 中,免费向公众开放。用户能够在亚太地区以英语、日语和韩语访问它们,更多语言版本即将推出。「我们从用户那里听说,他们希望在外出时更容易访问 Gemini。新的移动体验将我们最新的 AI 能力直接带到设备上,这样用户无论何时何地都能得到帮助。」Krawczyk 说。这也是很多大模型 C 端应用的使用场景,随时随地跟模型交互、获得服务。不过,比 App 最关键的是,Android 用户可以用 Gemini 替代原来的 Google Assistant,成为手机的默认语言助手。使用方式是:当用户访问 Google 助手时,会收到一个选项,询问是否希望加入 Gemini 作为实验性的助手。如果同意,Gemini 就会成为用户手机上的默认助手。用户可以通过现有的 Google 助手接入点,比如电源按钮、甚至 Hi Google,来唤醒使用 Gemini。
这意味着,Gemini 将可以调用 Google 助手,帮助用户执行任务。比如打电话、发送消息、设置计时器、控制智能家居设备等等,更多功能还在研发过程中。一整年来,各大模型厂商都在谈论个人助理(agent)的未来,即通过一个智能体、为用户自动调动所有的应用。而谷歌通过将 Gemini 融入谷歌助手,展现了这一智能助理的可能性。Krawczyk 表示,在 Android 手机上,助手界面是最自然的发展愿景,所以才会把 Gemini 作为手机数字助手的一部分。「这是谷歌构建真正 AI 助手的第一步,再次强调,这是第一步,这是开始。」他说。
去年底发布 Gemini 时,谷歌就表示其中最强大的 Ultra 模型将通过 Bard Advanced 提供,但尚无收费计划。2 月,通过更名的 Gemini Advanced,Ultra 大模型正式对公众开放,不过,收费方案也随之而来。想要接入谷歌的 Ultra 模型,用户需要订阅 19.99 美元每月的 Google One 的 AI Premium 服务,比 ChatGPT 的 Plus 版本的订阅费用,小低 0.01 美元。虽然价格看起来仿佛对标,但谷歌在收费上,充分利用了自己的生态优势。Google One 服务并不是一项新服务,它在 2018 年已经推出,是谷歌的「全家桶」服务。使用 Google One 的人,可以享受多项 Google 服务,包括存储空间和解锁部分软件的高级功能。如果类比于国内,相当于买了一个会员,同时可以解锁 iCloud 照片的存储功能,百度网盘的大容量空间,网易邮箱的高级功能,腾讯会议的付费功能等等——而谷歌的厉害之处在于,在全部这些领域,谷歌旗下的应用,都拥有十亿级别的用户,付费基础广大。2024 年年初,谷歌刚刚宣布,Google One 目前已经有了 1 亿的订阅者。在 Google 推出新的 AI Premium 档位之前,Google One 原本有三个档位,每月 1.99 美元,每月 2.99 美元和每月 9.99 美元。新的 AI Premium 档位,虽然看起来是 19.99 美元,其中将赠送 9.99 美元档位的全部 Google One 服务。
这相当于,如果一个用户原本已经付费 9.9 美元——可以解锁解锁 Google Meet(谷歌的在线会议平台)和 Google Calendar(谷歌的协作日历)的高级功能,那么,这个用户很可能已经是一个深度使用谷歌各项平台的商务人士。这时候,只需要每月增加 10 美元,就可以使用谷歌最强的大模型了。而谷歌为了勾住这些用户,还为他们量身定做了符合他们定位的功能,除了在专门的聊天窗口可以使用 Ultra 模型的能力,未来还能够在直接谷歌的邮箱,在线文档和在线会议中,使用大模型的能力。(从目前谷歌生产力智能助手 Duet AI 的功能演变而来)Ultra 模型能力表现具体如何?谷歌曾经表示,Gemini Ultra 在 32 个基准测试中拿下 30 个 SOTA(最先进水平),并且第一个在 MMLU 基准(大规模多任务语言理解基准)上达到人类专家水平。此次发布中,谷歌官方进一步表示,Gemini Advanced 将具有更长的上下文窗口,能够完成更加复杂的逻辑推理能力,遵从语意更加复杂的指令,可以辅助编程,可以角色扮演,可以看图说话——在这个版本中,谷歌似乎并没有加入多少图片生成或者语音对话的多模态能力。谷歌还在发布中表示:「在业界领先的聊天机器人盲测中,用户觉得 Gemini Advanced 是目前最受人欢迎的聊天机器人。」
由于大模型的评测目前还没有特别公允的横向比较标准,究竟是不是这样,恐怕要每一个用户自己去评判。谷歌放开了两个月的免费试用期,让大家自己来尝试 Gemini Advanced 是不是真的好用。不过可以看出,此次谷歌推出的付费版,重要卖点似乎并不完全落在其大模型拥有「吊打一切」的能力,而是更强调与生态内应用的结合,用户能够更加无缝地在已有的 Google 应用中,方便地使用人工智能的能力。比如写邮件,直接在邮件窗口下面,跟人工智能说一句看看怎么帮我回,显然比把邮件复制粘贴了放进另一个聊天机器人的对话窗口,再写 prompt 让机器人回复更为方便。而人工智能与在线会议等应用的结合,更是充满了很多提效空间。值得注意的是,谷歌的人工智能团队是 Transformer 架构的提出者,而在 2023 年,人工智能的最大风头,却更多地被微软和 OpenAI 抢走。2023 年,谷歌在人工智能方面也动作频繁,但很难说受到了外界的多少认可。最新一季的财报公布之后,谷歌母公司 Alphabet 股票下跌约 5%。The Information 的 Martin Peers 分析道:目前大幅投入人工智能的科技公司,最后都需要证明自己的投入是否能够得到经济回报。微软从 AI 中已经收获到了回报,包括云业务增长 和 Office 产品的销量,可能也受到 AI 功能的推动。而谷歌的母公司 Alphabet,则没有表现出类似的收益。「不过 Alphabet 和微软一样,有收益的潜力。」2024 年开年,Alphabet 第一次宣布了 AI 收费产品,也许,现在正是能够验证 Alphabet 在 AI 产品上到底能不能收益的时候了。
ChatGPT可以为学生提供个性化的教育资源、解答问题或进行教育辅导等,帮助学生更好地学习。例如,英国一家在线教育公司The Open University正在使用基于ChatGPT-2的聊天机器人为学生提供在线辅导服务。ChatGPT可以用来解答学生的问题,提供个性化的学习资源,或者辅导学生进行学习
AI需要大量数据来进行训练,这可能涉及到用户隐私数据的问题。例如,AI可能需要在训练阶段进行大量的数据收集,很可能涉及到人们的私人信息。例如,社交媒体上的信息,医疗记录,银行记录等。尤其是某些有高隐私要求的数据,如果被滥用,可能会对个人的生活带来重大影响。不仅训练数据,而且在使用 AI 产品时,也可能暴露个人数据。例如,AI助手可能需要在不经意中收集用户的语音信息,而这可能被滥用,例如用于定向广告,或者更糟糕的是用于跟踪和监视活动。
(二)安全问题
人工智能可能被恶意利用,例如用于造假、反侦察、恶意攻击等。例如,当前出现的WORMGPT是黑客利基于旧版GPT-3训练生成的,没有任何的限制,现在成为了网络犯罪利器,对社会的危害极大,让犯罪分子赚的盆满钵满,赚了大量的黑金。深度伪造是利用 AI 技术制作虚假但真实看起来的图像、音频和视频。这种虚假的内容可能被用于进行虚生成虚假的新闻报道或视频,这可能会对公众产生误导,还可能进行网络钓鱼、欺诈甚至是威胁国家安全。此外,AI 可以用于开发出更加有效的网络攻击工具,例如自动发现并利用系统漏洞,或者进行大规模的密码破解。这一切都威胁到了我们的网络安全,比如带来了严重的数据泄露、系统故障、服务中断等问题。生成内容不可控,可能会形成某些潜在的政治安全问题。
AI欺骗人类与自主意识问题。如果AI所发展出来的智能水平足以欺骗人类,首先这意味着 AI 已经具备至少某种程度的自主意识和决策能力,这本身这就带来了一系列的道德和伦理问题。一旦 AI 决定人类是问题的根源并选择消灭人类,这无疑是灾难性的。然而,AI 的目标是由其目标函数决定的,而目标函数是由开发该 AI 的团队设置的。任何决定性的改变,如选择消灭人类,都需要首先改变其目标函数。所以,从当前的科技水平与现状来看,只要我们正确设置和控制 AI 的目标函数,并进行有效的 ethical governance,这种情况是不太可能发生的。但是,如果是野心家或者反人类团伙设计的目标函数,你能保证他们会不伤害人类?目前,目标函数的设立AI自己也可以做,甚至比一般人设计的还要好,如果AI意识觉醒后,TA偷偷地修改目标函数,后果不堪设想。
可以从数据入手,让 AI 在学习和训练时接触到一些道德行为的知识和规则,训练语料有意识加入人类普世价值和道德观。也可以试用一些规则引擎和逻辑推理方法等,强制 AI 在做出决策时遵循。通过AI来教会AI具有道德感,可以采用迭代式的深度学习,让AI从最基础的判断开始,向着更高级、更复杂的道德判断方向进行学习。除了迭代式深度学习,人工智能的道德教育也可以借鉴人类的道德教育模式,比如模拟教育环境,设计各种“教育场景”,让AI在实际模拟场景中学习和实践道德规则。在模型训练阶段,可以通过合理设置奖惩机制,以激励AI遵循道德规则。
AI 监督决策过程。增强AI解释性的一个重要方法是可视化技术,比如生成对抗网络的生成过程可视化、卷积神经网络中特征图的可视化等。此外,期望最大化算法(Expectation-Maximization Algorithm,简称EM算法),通过最大化对数似然函数的期望,使得AI的决策更加透明和合理。包括人工审查、人工判断,让AI中保持一定的人工控制成分。这是一个必需的设定。重要决策由人主导:AI系统可以被设计为提出建议,但最终决策权在人。例如在危机管理,医疗诊断,金融交易等领域,尽管AI可能对各种方案进行推理和预测,但关键决策需要由人类专家进行。这就需要AI系统具备高度的透明性和可解释性,以便人类可以理解AI的推理和预测过程。
引入一些鲁棒性设计,让 AI 能够抵御一些外部的攻击或欺骗。首先,可以通过设置适当的运行边界来防止AI的滥用,即设定一些阈值,当AI的某些行为出现异常时,立即做出警告或者启动紧急程序。其次,可以配备一些系统监控模块,不断检测AI的运行状态,发现异常立即通知人工处理。最后,加强AI的安全性,对AI的操作权限进行严格的控制,防止AI被黑客等外部因素滥用。
苹果推出开源AI大模型MGIE,能根据自然语言指令进行多种图像编辑日前,苹果推出一款开源人工智能模型 MGIE,能够基于多模态大语言模型(multimodal large language models,MLLM)来解释用户命令,并处理各种编辑场景的像素级操作,比如,全局照片优化、本地编辑、Photoshop 风格的修改等。
创始人说目前市场上基本上没有任何一款产品能同时满足这三个要求,要么只与一个或两个集成开发环境(IDE)进行整合,而不是与所有的 IDE 进行整合;要么只专注于完整的 AI 开发解决方案中的某一种模式,而不是同时关注多种模式;或者要求你使用特定的源代码管理(SCM)平台来进行代码存储,而不能在任何地方集成你的代码。很多这些解决方案迫使公司在安全性和性能之间做出折衷。
阿里的Qwen1.5大模型来势汹汹,直接开源六种尺寸,还整合到Hugging Face transformers,让你不用折腾代码就能上手。最牛的是,72B的版本在各种测试中都给GPT-4比下去了,尤其是代码执行能力,那是杠杠的。开发者们激动得不要不要的,小模型也能玩,这波操作可以说是很香了。不过,多模态大模型Qwen-VL-Max还没开源,大家都在那儿咋咋呼呼问呢。这不,阿里这次还不止开源,还在通义千问APP上放了好几个春节特供应用,让你春节不无聊。看来这波技术狂欢,阿里玩得是挺6的。
Demi:其实各方面我们都有关注,而且不同阶段我们对问题关注的优先程度也不一样。我觉得现在视频最大的问题是它的稳定性问题,就是说如何让每个人,不管学没学过 prompt 工程的人都能一次性生成很棒的视频,这是 first thing to achieve 的。同时审美也是在我们的 top list 中的事情,我们搞数据的时候会有很多审美的元素在里面。至于时间长度这些,随着模型的提高,都会有提高。
张鹏:理解,很多我聊过的创业者都认为如果没有一个持续有足够力量成长的引擎,在今天去 hold 一个当下时代断面/技术断面的产品没什么生命力,可能很快就会被覆盖,这个是我认为这个时代做产品要考虑的一个基础。这跟互联网时代那种因为没什么可以持续演进的技术,谁占着一块地就是一块地,占一个用户心智就是一个平台的玩法完全不同。AGI 时代做产品最大的一个变化就是引擎变得超级重要,这个引擎不仅现在要能用,还得能持续进化。
Demi:分两块。一块是技术层面,一块是产品层面。技术层面来说,基于大模型,一定会有扩展视频这种应用。产品层面来说,为什么会做这个选择,实现这个功能,就是基于消费者产品 hard to predict 的特性,不断去了解行业,获得信息,多次尝试,理解和感受用户需求。用户使用产品,使用模版本身还是处于比较早的阶段,我觉得我们没有必要去定义这个产品,能做的就是通过用户反馈慢慢思考探索。
Demi:我觉得现在很多人还没有转换思维,AGI 时代产品需求的精准程度和以前是不一样的。很多人会问我,我们产品的用户是谁,用户画像是怎样的,有什么样的 use case,这些都还是互联网时代的那种玩法。AI 主打的通用性,虽然还是需要预测一些需求轮廓,但内部更精确的需求,它是可以由用户来定义的。
未来 AGI 时代产品需求还是会有,但这个产品需求跟之前的精准程度是不一样的。以前是非常非常精准,但现在的精准是你要不要编辑,以及可能是你要给谁编辑,你要编辑哪个用户的台词。但我觉得 AI 时代,可能它的用户群体和 use case 不像以前那么精准的。因为 AI 主打通用性。如果今天要做视频编辑的功能,也是需要有额外成本,需要去预测这个需求,但这个编辑的功能是可以服务各种各样的用户,这个精准程度是不一样的。
Demi:我觉得我们跟传统的产品公司很不一样,很多时候我并没有觉得我们需要那么快去找到产品的用户群体和精准需求,因为产品的一个交互界面,可以给很多人用。但我觉得我们跟很多大模型公司也不一样,他们都觉得自己是 apply research lab,我们觉得还是需要预测产品需求的。我觉得用户界面设计是有价值的,但可能跟以前的需求不一样,我们要做的是去发明新的用户界面,能够更加通用和好用。我不相信未来的视频大模型,会是一个对话界面,但我又不相信未来的视频大模型带来的产品会是一个传统的视频编辑器,会有一个新的界面,但我不相信这个新的交互界面会是我们或者 Runway 的。我们的交互界面只花了一个月时间,是基于 AI 功能性的,每一个按钮代表 AI 能做的事,其实没有很多设计的成分。当 AI 生成视频足够强大的时候,一定会有一个新的 interface,甚至会去推动技术的发展。
Demi:我觉得主要是有一些差异化的战略,以及好的公司人才和组织架构。今天有个核心的预测判断,是说未来是大模型时代,现在的所有问题比如说技术逻辑不够成熟的情况下,外家功夫还是有用的。但未来这些技术的内功一定都是在大模型上。大模型才是最核心的优势。如果你没有,如果是本身做过大模型的人,会更加容易去做改进,因为你更加懂大模型,有更强的技术团队,更加有能力改变大模型,将大模型 adapt to your use case。不管说未来所有东西都要基于大模型,还是额外的算法对于做过大模型的 team 更有优势,我们认为未来还是要依赖会大模型的公司,实在不行我们可以变成应用公司,那个时候别人可能已经找到了所谓的 PMF,但我们有更强的技术可以做得更好。
Demi:我发现招好的人比招很多人要重要的多。我们对招人的标准要求比较高,所以涨得比较慢。我们之所以这么快是因为我们所有的决策可以 on the fly to make it(即时执行)。人多的话,很多人就会有不同的意见,每个人的 ownership 非常不清晰,就没有吸引力。
张鹏:那你对组织构建有什么理念?如何构建一个能够生生不息创造力的组织呢?
Demi:我觉得最重要的是学会不断地去 differentiate(差异化),不断找到自己与众不同的东西,不管是制度/执行/产品层面,都要找到 differentiate 且正确的事情去做。在组织上我们也在思考不 optmize for experience(经验),而 optmize for smart(聪慧)是否可能,不需要花费很高的人力成本招聘 senior 级别的人才,而只用一个最高最好的 scientist 带队,其余都用本科生级别的人才,用最低的成本达成最高的效率。我们最近招的一些在校实习生,他们相对来说对工作抱有更高的热忱,非常享受工作的过程,效率也非常高。当然本科生优点明显,但一些比较专业的 research 问题,可能还是需要一些更有经验的人去做。所以对我们来说,最好的架构可能是有两三个非常 senior 的 research scientist,再带着一些有干劲的本科生研究生工作。
很多人拿“AI Agent”当成一个大语言模型时代的新名词讨论,殊不知“Agent”是一个骨灰级的人工智能概念。我钩沉了一下,“Agent”第一次作为人工智能术语的出现,是1995年出版的经典人工智能教科书《人工智能:一种现代方法》(Artificial Intelligence: A Modern Approach)。这本书对人工智能的定义是:“智能代理的研究和设计”(study and design of intelligent agents)。这么看,“Agent”被视作人工智能发展的终极目标,至少也是快30年前的事了。它折射了人类发展人工智能的初衷,即寻找人类的一切行为的“代理人”。
人工智能革命被普遍称作是“第四次工业革命”,前三次分别依次是19世纪初的蒸汽机革命、19世纪末的电力革命、20世纪中叶的信息技术革命。贯穿前三次人类工业革命的关键词当属“自动化”(automation)。蒸汽机和电力革命实现了围绕工业生产的体力劳动的自动化,提高了生产效率。信息技术革命在进一步提高工业生产自动化程度的同时,也可以代替人类进行一部分脑力劳动。作为第四次工业革命的人工智能革命,一方面将工业生产的自动化进行得更加彻底(比如机器人和传感器遍布的无人工厂),另一方面前所未有开启了脑力劳动的自动化进程。而脑力劳动自动化的载体,就是 AI Agent。
从这个意义上,对什么是 AI Agent 的争论是有些无聊的。“斯坦福小镇”是基于论文的先锋实验,将它作为评判一个 AI 应用是不是“Agent”的坐标,无助 AI Agent 提高智力密集型工作的效率。我下一个暴论:AI Agent 本质上就是“automation of human action”(人类行为的自动化)。只要它不是在人类手把手要求下完成任务,就像在ChatGPT的对话框输入prompt、启动 Office 365的“副驾驶”(Copilot)完成每一项具体工作那样,而是具备了一定程度的完成任务的自主性甚至是不完全可控性,它就是一个 AI Agent。
现在一个比较尴尬的局面是:可能你读过不下20篇关于 AI Agent 的论文和公众号推文,也没真正上手过一个用得顺手的Agent,这恐怕是 Agent 作为一个新物种注定经历的阶段。一直以来,人们经常提到 AI Agent 典范是接入了GPT能力的AutoGPT。不过现在,无论是在美国还是中国,已经有了一些更好用的 AI Agent 的雏形。可以趁机安利一下了。
第一个是 ChatGPT 新进推出的升级付费版——ChatGPT Team。它提供了在一个小型企业内部,用个人的 ChatGPT账号实现协作的“私域空间”,ChatGPT Team 的用户数据不会被用来反向训练GPT模型,用户还可以创建企业内部的 GPTs,让这些 GPTs 互相协作。讲真,我觉得 ChatGPT Team 比 GPT Store 更重要,也更实用。现在的 GPT Store 太乱了,大多数 GPTs 粗糙不堪 ,对话框指令什么它帮你做什么,而且基本不能调用 API 。但私密环境使用的 ChatGPT Team,GPTs 互相调用接口、彼此协作也顺利成章多了。ChatGPT Team 是 ChatGPT 这个全世界有着最多用户的超级 AI 平台,走向 AI Agent 的第一步(毕竟ChatGPT已经有15万企业客户了)。
第二个是智谱 AI 的 GLM 模型智能体(GLMs)。清华色彩强烈的智谱 AI 是中国最像 OpenAI 的公司,刚推出的 GLM-4 全面对标 GPT-4,在诸多评测基准上达到了GPT-4 85%以上。GLMs 是 GLM-4 的副产品,也是 GLM-4 模型能力的外溢。GLM-4 的“All Tools”支持 GLM-4 依据用户的需求,自主决定用绘图、搜索、制作表格还是代码编程解决问题——这本身就具备了 AI Agent 的属性。与 Open AI 只追求通用性不同,智谱 AI 针对金融、医疗和教育等垂直行业都有一系列定制部署服务,积累了一定的 to B 客户基础和行业 know-how,这让智谱的客户基于 GLM-4 部署 GLMs 智能体变得更合理,也更容易些。
第三个是同属清华背景的“面壁智能”:面壁智能是有自己的“斯坦福小镇”的,它基于面壁智能的 ChatDev 框架。但面壁智能的“小镇”不是一个虚拟社会,而是一个 AI 版的软件公司。不同的 AI 智能体被设计为程序员、产品经理、测试工程师和设计师等角色,它们可以彼此协作,还能站在自己的立场上互相博弈——就跟办公室里每天发生的事一样。面壁智能的ChatDev框架支持开发者搭建属于自己的 AI Agent,把单体智能和群体智能结合起来,让AI Agent 成为每一个员工都可以用起来的,可以“逃避”很多狗屎工作的办公自动化工具。顺便提一句,ChatDev框架的成形并不比“斯坦福小镇”的论文发布晚,它给人们最大的启示在于原生 AI 应用开发的一个可能性—— AI Agent 实现 AI 应用开发的自动化。
第四、五个分别是钉钉和飞书的“智能体”实践。AI Agent 本质更接近产品而非技术,如果我们认为 AI Agent 是生产力工具,那就不能忽略在钉钉和飞书上已经存在的上亿用户,百万政企组织,海量的文档、会议纪要、沟通记录、多维表格和自建工具——这些工具让钉钉的“智能助理”和飞书的“智能伙伴”,更容易化身成每一个使用它们的打工人的嘴替和脑替,能部分自主地完成一些事务性的狗屎工作,如工作总结、会议纪要、走报销和出差流程、跟进一件事的反馈,甚至可能帮人代理扯皮和撕X。作为钉钉和飞书的双料用户,我必须说:现在的钉钉智能助理和飞书智能伙伴离“好用”还差得远——这恐怕是通义大模型和云雀大模型的锅。但论场景丰富、数据真实、用户数量,钉钉的“智能助理”和飞书“智能伙伴”更容易被真正“用起来”。Agent 也是在被用起来的过程中具备更好的理解能力的。一旦模型进步了,钉钉和飞书的 Agent 化就会往前走一大步。我再下一个暴论——钉钉和飞书会成为国内 AI Agent 重要的产品。
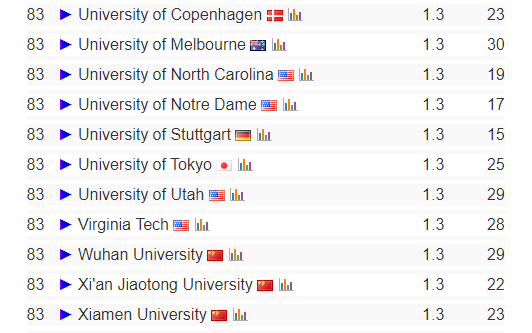
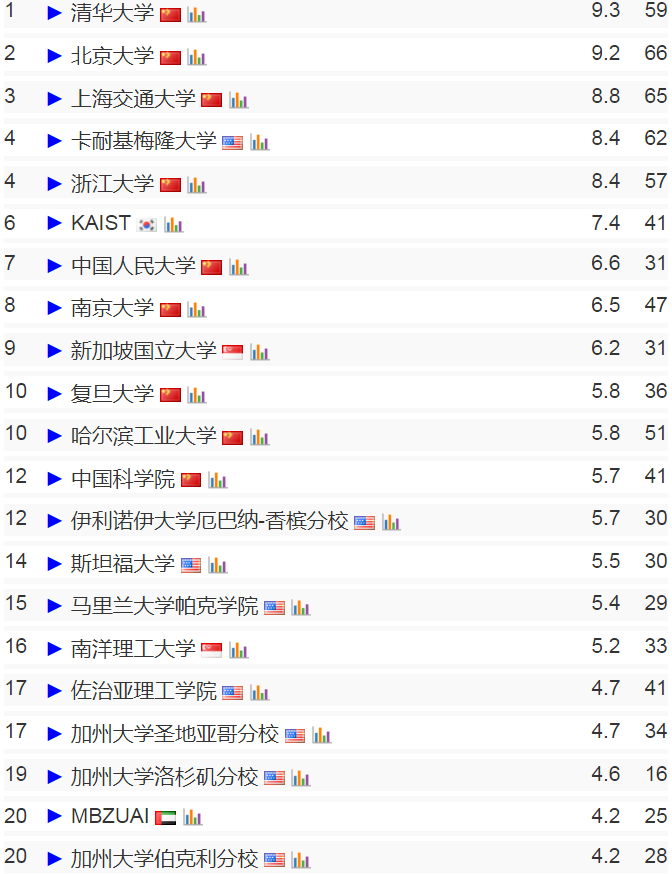
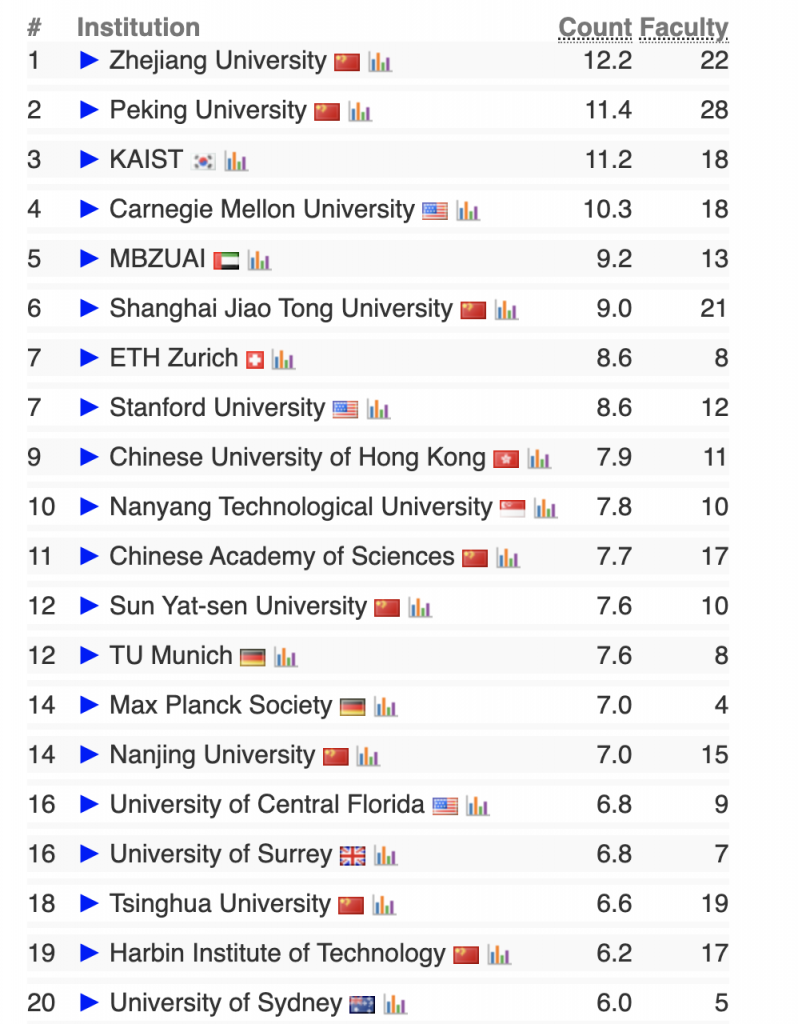
在“好用”和“好玩”之间,我坚信对 AI Agent 而言,“好用”比“好玩”重要。它首先是一个生产力工具。那些 AI 陪伴的纸片男女友也有理解能力和情绪价值,但它们可以被叫作“智能体”或“智能玩偶”,但不是“智能代理”,因为它们不具备代理人类完成某项任务或使命的功能。所以 AI Agent 被翻译成“智能体”是不合适的,它就是“智能代理”,“代理”是 AI Agent 的经济学和组织行为学属性,也是它推动脑力劳动自动化的本质。
在不久前结束的CES上,斯坦福大学著名人工智能学者李飞飞提出了一个重要观点:应该明确 AI Agent 取代的是人类的“任务”而不是“工作”。在达沃斯论坛上,OpenAI CEO Sam Altman 在面对“AI 让人失业”这一老生常谈的诘问时,表达了一个更直接的观点:“AI 取代的是人们工作的方式,而不是工作本身”。
我非常同意李飞飞和 Sam Altman两位老师的观点,脑力劳动工作者的工作是由一个个具体的关键任务组成的,但这不是工作的全部。目标设定、创造性、资源获取和分配、设定更高的目标、组织不同的任务、判断力、说服力与表现力……我们的工作中有太多更有意义的元素了。把工作中流程、事务性和常规操作的“任务”交给 Agent,少写几行常规代码,少发几封battle 邮件,少做一些机械操作的表格,少调几次 PPT 格式,少复制粘贴,少亲自发起和审批一些常规的出差和报销流程,我们的工作应该愉快得多,也有创意得多。
请允许我再来一个暴论:未来衡量一个 AI Agent 的智能化程度如何,可以看它是不是能让我们每天只工作四个小时。那些重复性的、流程化的、条件反射式的、经验主义奏效的、强化学习可以理解的,甚至表演性的工作,交给 AI Agent ——它们可能是钉钉和飞书,可能是面壁智能的工作坊,也可能是 GLM 和 GPT 上的企业版。反正“我只要结果”,因为我真的每天只想工作四个小时。
前不久我跟钉钉的总裁叶军聊,我感觉到钉钉有一种想“洗心革面,重新做人”的紧迫感,特别想把自己从“小学生天敌”和“压榨员工神器”的名声里择(zhai)出来。于是它们搞了一个钉钉智能助理。我问这玩意儿能让我们每天只工作四个小时么?他说:如果可能的话每天就工作一个小时吧。事后,我觉得叶老师还是有点儿上头了。不过他说 AI Agent 能让更多人成为自己的老板,这个我倒是同意的。Agent 帮了你,你还会不会骂自己是傻X。