
三万亿Token!AIlen AI发布史上最大文本数据集Dolma,已开源
随着科技的飞速发展,大型语言模型已经成为了人工智能领域的热门话题。近日,AI研究机构Allen Institute for AI发布了一个名为Dolma的开源语料库,这个语料库包含了3万亿的token,成为了迄今为止最大的开源数据集。

1、Dolma的诞生背景
从今年3月开始,Allen Institute for AI开始创建一个名为OLMo的开源语言模型,旨在推动大规模NLP系统的研究。他们的主要目标是以透明和开源的方式构建OLMo,通过发布工程中的各种成果和文档来记录整个项目的进展。而Dolma就是这个项目中发布的第一个数据成果。这个数据集包含了来自网络内容、学术出版物、代码、书籍和维基百科材料的3万亿token。这个数据集已经在HuggingFace Hub上公开,任何人都可以下载。
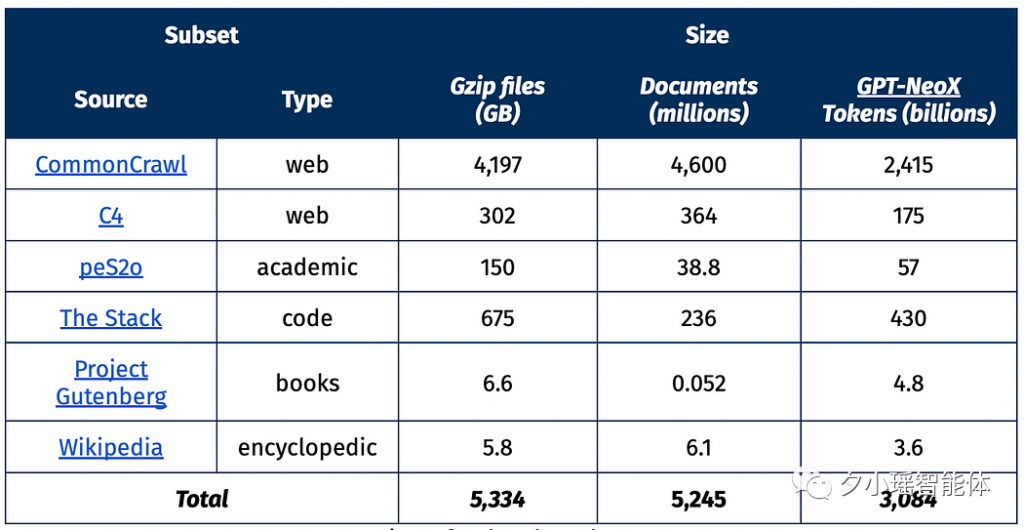
地址:https://huggingface.co/datasets/allenai/dolma2、Dolma的目标
- 开源:AI2希望创建一个数据集,使其他研究者有机会独立地创建更好的版本,研究数据与其上训练的模型之间的关系,并报告他们在检查数据时观察到的任何问题。
- 代表性:Dolma的语料库应该与其他语言模型使用的数据集相当。
- 大小:AI2希望收集一个大型数据集,以研究模型和数据集大小之间的关系。
- 可复制性:在准备数据集时开发的所有工具都应该公开提供,供其他人复制他们的工作。
- 风险缓解:Dolma应该在满足可复制性和代表性的要求的同时,尽量减少对个人的风险。
3、Dolma数据集的设计原则
在创建Dolma时,需要遵循四个原则:
- 遵循现有的实践:通过匹配用于创建其他语言建模数据集的方法,A使广大研究社区能够使用数据集和生成的模型工件来间接研究(并审查)今天正在开发的语言模型,即使那些在封闭的门后开发的模型。
- 信任评估套件:AI2为OLMo开发的评估套件可以提供模型在多种任务上的能力指标;当做出直接影响这些任务之一的数据相关决策时,我们选择改进指标的干预。例如,AI2在Dolma中包括Wikipedia文本,因为它提高了K-12科学知识任务的性能,例如ARC。
- 支持AI2的核心研究方向:不是所有的数据集策划决策都是关于基准性能的。事实上,许多理想的干预措施彼此相互矛盾。例如,AI2希望OLMo既能处理代码任务,也能处理文本任务,但添加包含代码的文档会降低许多文本基准的性能,反之亦然。
- 采取基于伤害的风险缓解方法:为了研究的利益,某些界限不应该被越过,即使它们在大规模语言建模项目中是常见的实践。AI2在项目的早期与法律和伦理专家进行了接触,并根据他们的反馈对数据设计决策进行了评估。
4、Dolma的创建过程
Dolma的创建涉及从多个来源获取的原始数据转化为清洁的纯文本文档。这些数据处理步骤通常分为两类:特定于来源和与来源无关。如下图所示,预训练语料库的创建需要这两种操作的组合;多个转换按顺序在一个管道中执行。

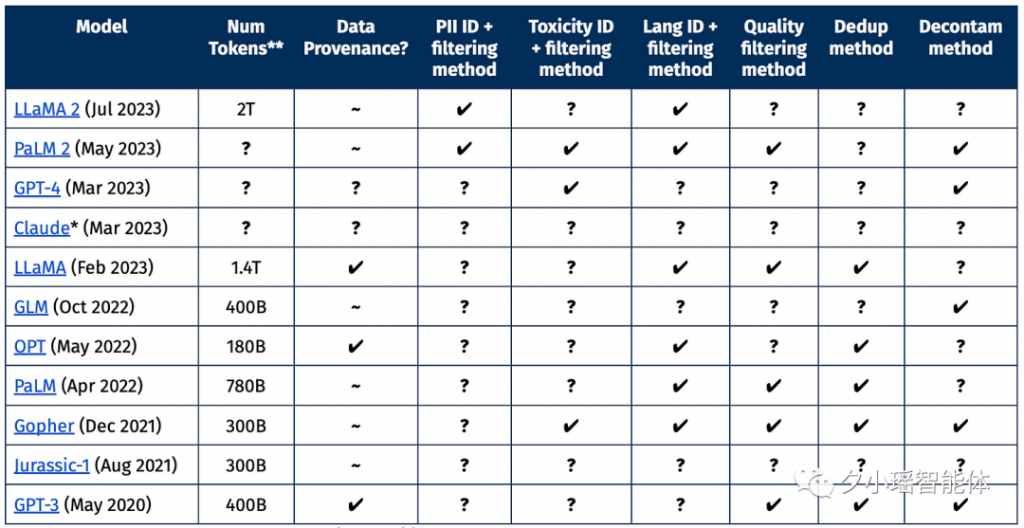
5. Dolma与封闭数据集的比较
以下表格提供了不公开其预训练数据的语言模型的高级摘要。为了使表格不至于过大,AI2将其限制为65B+参数规模的全密集、自回归模型。✔ 表示引用的作品明确描述了论文中报告的处理步骤,?表示缺少报告,~表示仅存在部分信息。
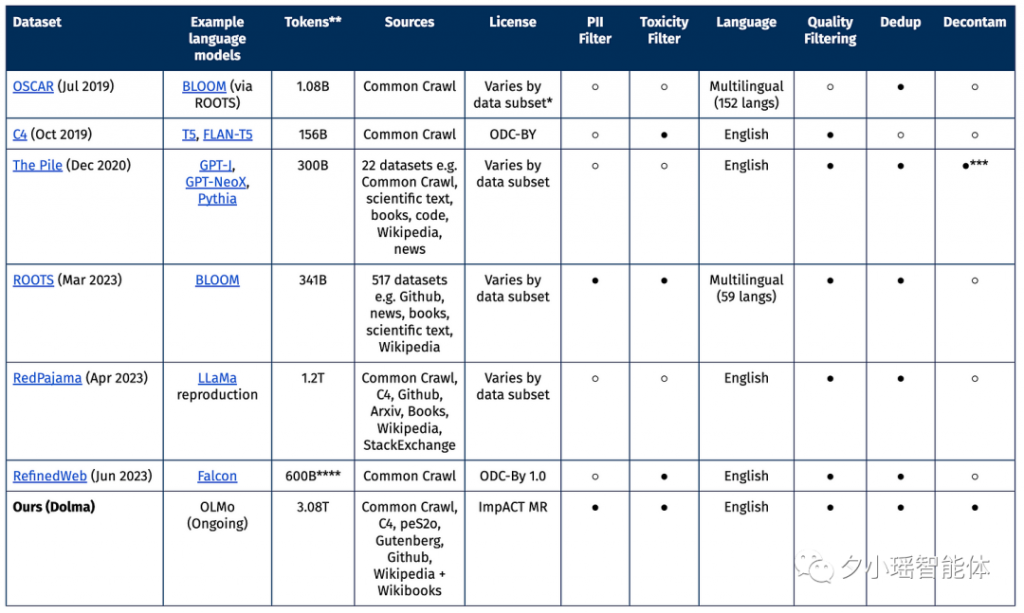
6. Dolma与其他数据集的比较
Dolma与其他开源数据集的主要区别在于,它的大小远远超过其他开源数据集,并且它是在AI2的ImpACT许可下发布的,这是为了平衡易于访问与分发大型数据集的潜在风险。
7. Dolma的发布
Dolma在AI2的ImpACT许可下作为中等风险工件发布。根据此许可,研究者必须:
- 提供他们的联系信息,并声明他们访问Dolma的预期用途;
- 披露基于Dolma创建的任何衍生物;
- 根据ImpACT许可的相同限制分发衍生物;
- 同意不利用Dolma进行一系列禁止的用途,如军事监视或生成假信息。
8.未来展望
Dolma的发布不仅仅是一个技术上的里程碑,更是对开放研究和透明度的一次重要承诺。随着技术的不断进步,我们期待看到更多的创新和突破,为人工智能和机器学习的未来铺设坚实的基石。Dolma的出现,为我们揭示了一个充满无限可能的未来。
参考链接:https://blog.allenai.org/dolma-3-trillion-tokens-open-llm-corpus-9a0ff4b8da64
想要做大模型训练、AIGC落地应用、使用最新AI工具和学习AI课程的朋友,扫下方二维码加入我们人工智能交流群
