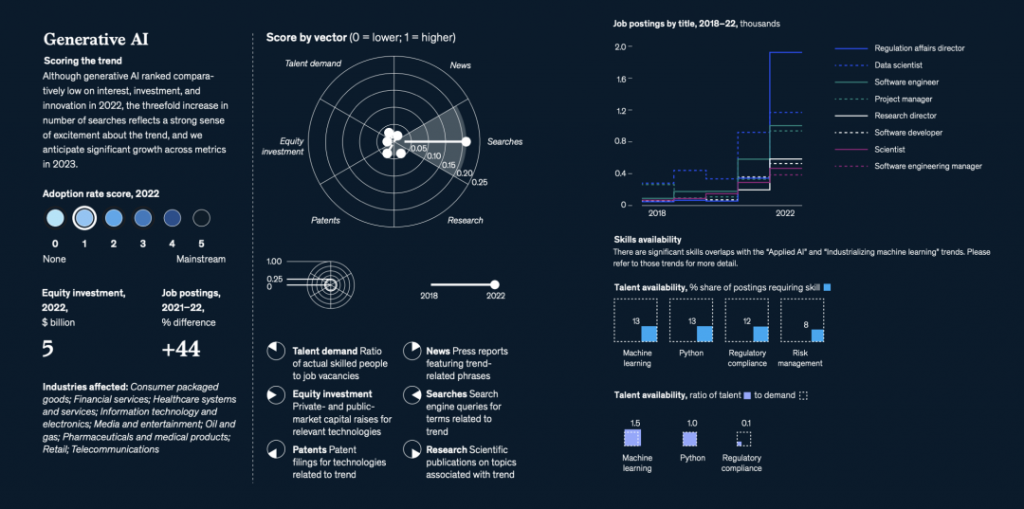
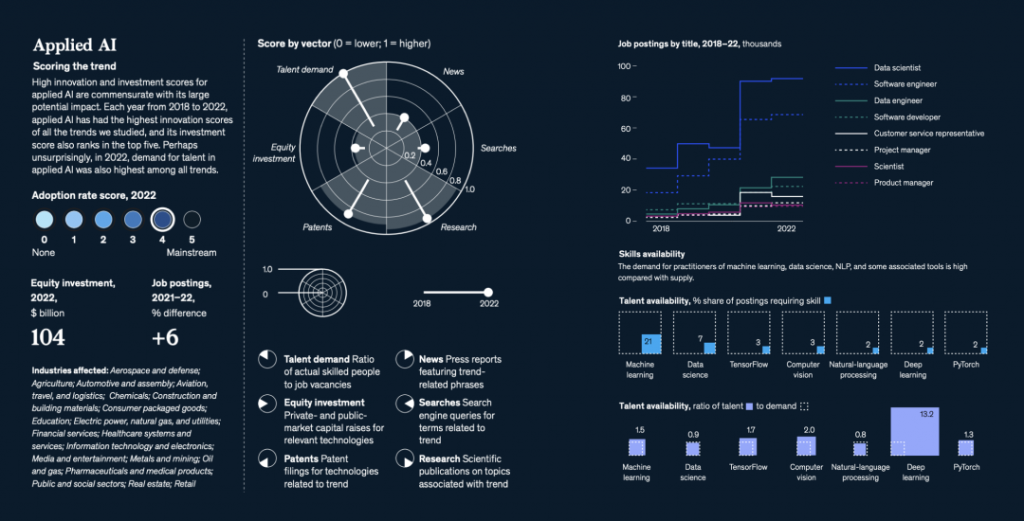
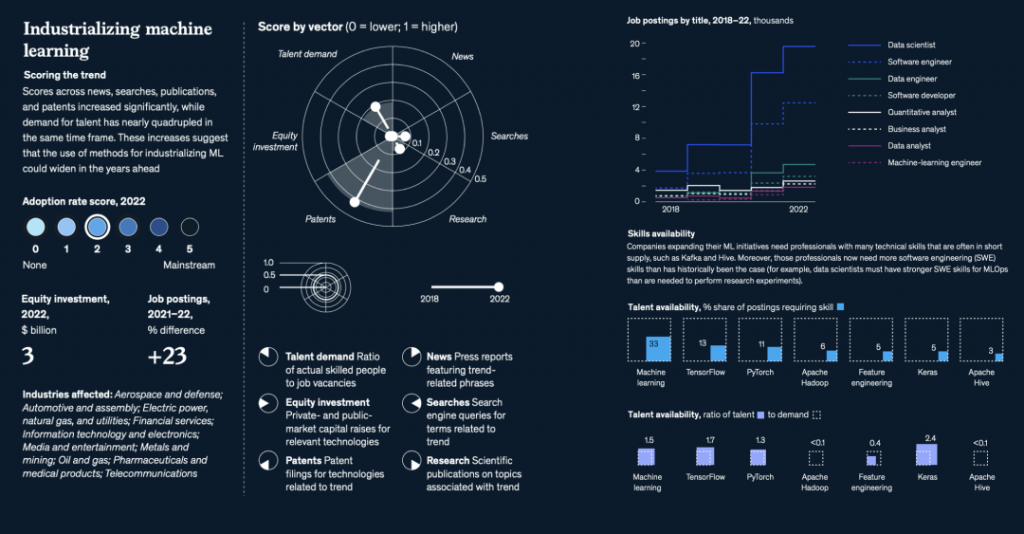
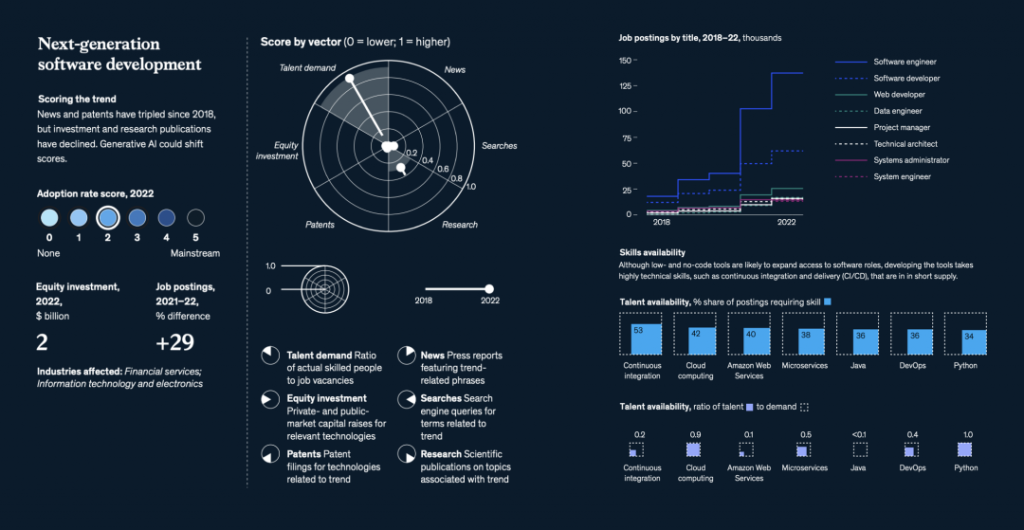
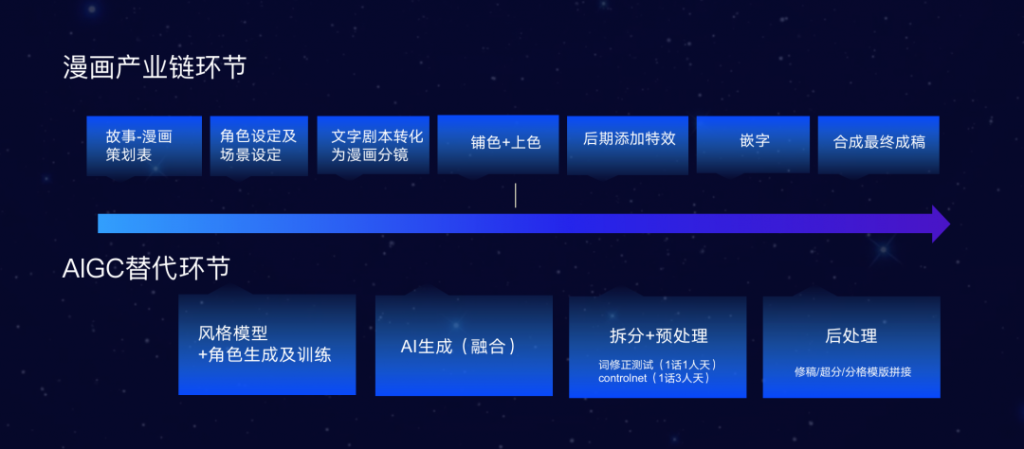
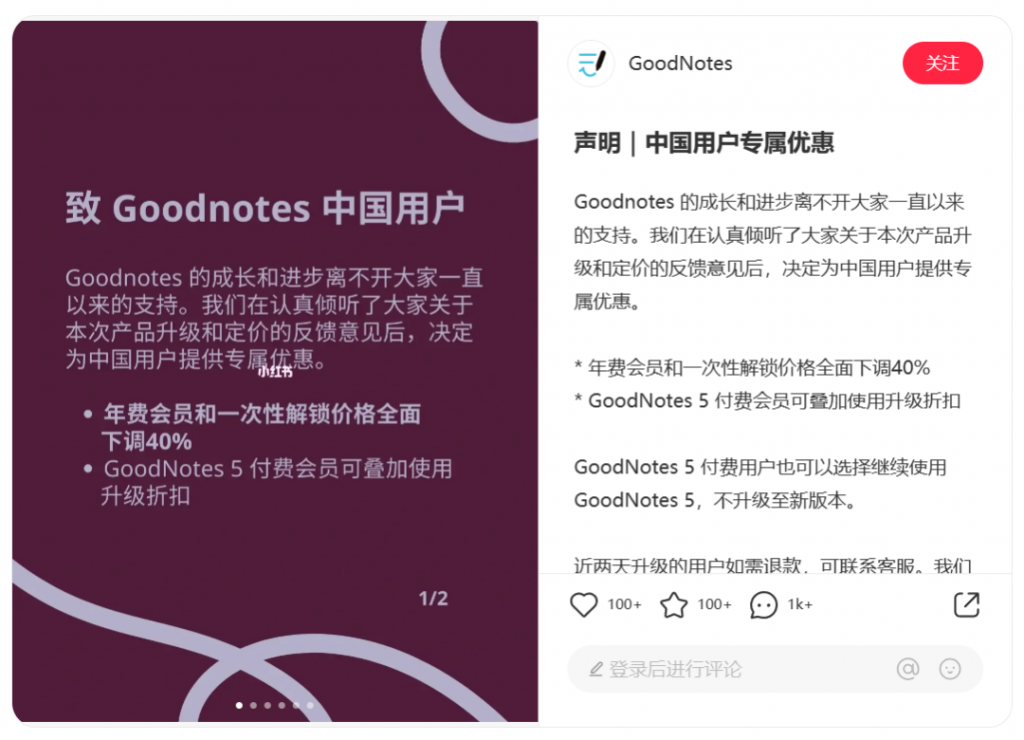
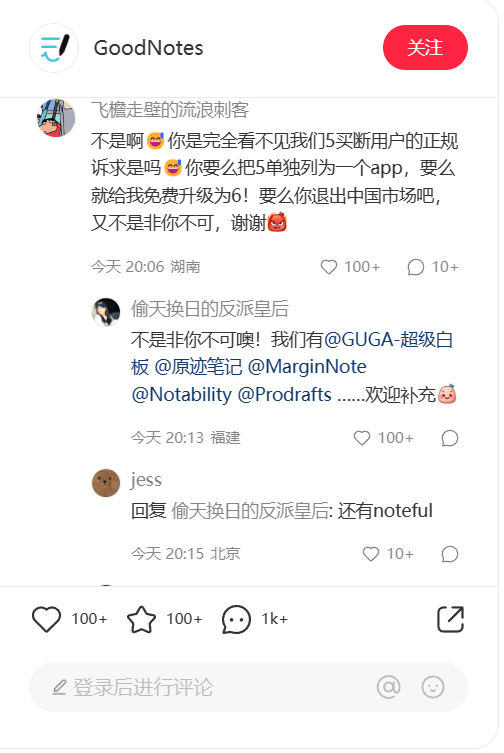
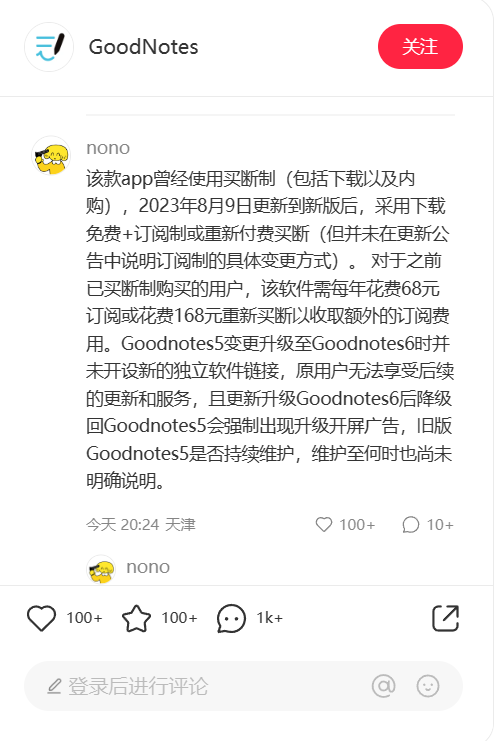
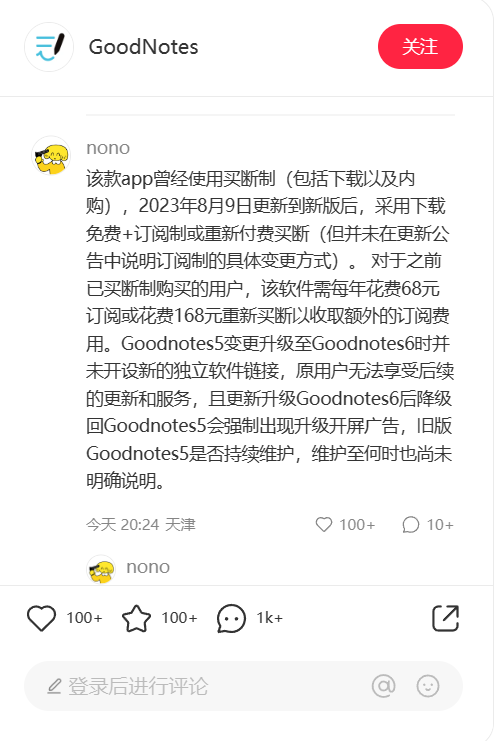
OpenAI公司的代表和作者没有立即回应置评请求。今年夏季早些时候,两个独立的作者团体对OpenAI公司提起了集体诉讼,指控它非法将他们的书籍纳入用于训练ChatGPT对人类文本提示做出反应的数据集中。喜剧演员Silverman的组织还对Meta Platforms提起了相关的诉讼。其他一些公司也对谷歌、微软和 Stability AI 等公司的人工智能训练提起了类似诉讼。
Human error and uncertainty are concepts that many artificial intelligence systems fail to grasp, particularly in systems where a human provides feedback to a machine learning model. Many of these systems are programmed to assume that humans are always certain and correct, but real-world decision-making includes occasional mistakes and uncertainty.
Researchers from the University of Cambridge, along with The Alan Turing Institute, Princeton, and Google DeepMind, have been attempting to bridge the gap between human behaviour and machine learning, so that uncertainty can be more fully accounted for in AI applications where humans and machines are working together. This could help reduce risk and improve trust and reliability of these applications, especially where safety is critical, such as medical diagnosis.
The team adapted a well-known image classification dataset so that humans could provide feedback and indicate their level of uncertainty when labelling a particular image. The researchers found that training with uncertain labels can improve these systems’ performance in handling uncertain feedback, although humans also cause the overall performance of these hybrid systems to drop.
该研究结果将发布于2023年人工智能、伦理和社会会议(AIES 2023),该会议由国际先进人工智能协会(AAAI)和美国计算机协会(ACM)联合举办,今年在蒙特利尔召开。 Their results will be reported at the AAAI/ACM Conference on Artificial Intelligence, Ethics and Society (AIES 2023) in Montréal.
‘Human-in-the-loop’ machine learning systems – a type of AI system that enables human feedback – are often framed as a promising way to reduce risks in settings where automated models cannot be relied upon to make decisions alone. But what if the humans are unsure?
“Uncertainty is central in how humans reason about the world but many AI models fail to take this into account,” said first author Katherine Collins from Cambridge’s Department of Engineering. “A lot of developers are working to address model uncertainty, but less work has been done on addressing uncertainty from the person’s point of view.”
We are constantly making decisions based on the balance of probabilities, often without really thinking about it. Most of the time – for example, if we wave at someone who looks just like a friend but turns out to be a total stranger – there’s no harm if we get things wrong. However, in certain applications, uncertainty comes with real safety risks.
“Many human-AI systems assume that humans are always certain of their decisions, which isn’t how humans work – we all make mistakes,” said Collins. “We wanted to look at what happens when people express uncertainty, which is especially important in safety-critical settings, like a clinician working with a medical AI system.”
“We need better tools to recalibrate these models, so that the people working with them are empowered to say when they’re uncertain,” said co-author Matthew Barker, who recently completed his MEng degree at Gonville & Caius College, Cambridge. “Although machines can be trained with complete confidence, humans often can’t provide this, and machine learning models struggle with that uncertainty.”
这项研究还引入了三个机器学习基准数据集,分别用于数字分类、胸部X射线分类和鸟类图像分类。
For their study, the researchers used some of the benchmark machine learning datasets: one was for digit classification, another for classifying chest X-rays, and one for classifying images of birds. 研究人员对前两个数据集进行了不确定性模拟,但对于鸟类数据集,他们让人类参与者表明对所看图像的确定程度:例如,鸟是红色还是橙色。这些由人类参与者提供的注释“软标签”让研究人员能够修改并确定最终结果。然而他们发现,当机器被人类取代时,性能会迅速下降。
For their study, the researchers used some of the benchmark machine learning datasets: one was for digit classification, another for classifying chest X-rays, and one for classifying images of birds. For the first two datasets, the researchers simulated uncertainty, but for the bird dataset, they had human participants indicate how certain they were of the images they were looking at: whether a bird was red or orange, for example. These annotated ‘soft labels’ provided by the human participants allowed the researchers to determine how the final output was changed. However, they found that performance degraded rapidly when machines were replaced with humans.
“We know from decades of behavioural research that humans are almost never 100% certain, but it’s a challenge to incorporate this into machine learning,” said Barker. “We’re trying to bridge the two fields so that machine learning can start to deal with human uncertainty where humans are part of the system.”
The researchers say their results have identified several open challenges when incorporating humans into machine learning models. They are releasing their datasets so that further research can be carried out and uncertainty might be built into machine learning systems.
“As some of our colleagues so brilliantly put it, uncertainty is a form of transparency, and that’s hugely important,” said Collins. “We need to figure out when we can trust a model and when to trust a human and why. In certain applications, we’re looking at probability over possibilities. Especially with the rise of chatbots, for example, we need models that better incorporate the language of possibility, which may lead to a more natural, safe experience.”
“In some ways, this work raised more questions than it answered,” said Barker. “But even though humans may be miscalibrated in their uncertainty, we can improve the trustworthiness and reliability of these human-in-the-loop systems by accounting for human behaviour.”
The research was supported in part by the Cambridge Trust, the Marshall Commission, the Leverhulme Trust, the Gates Cambridge Trust and the Engineering and Physical Sciences Research Council (EPSRC), part of UK Research and Innovation (UKRI).
然而,如果 OpenAI 无法扭转局面,面对每日高额的成本及其无法快速实现盈利的情况,Analytics India Magazine 认为 OpenAI 甚至可能在不久将来就要宣布破产。
而在 AI 芯片这个赛道英伟达更是遥遥领先,目前还没有哪家科技公司能望其项背。研究公司 Omdia 的数据显示,虽然 Google 、亚马逊、Meta、IBM 等公司也在生产 AI 芯片,但英伟达已占据了超过 70% AI 芯片销售额,并且在训练生成式 AI 模型方面有着更显著的优势。
Futurum Group 分析师 Daniel Newman 表示,很多客户宁愿等待 18 个月向英伟达采购芯片,也不从初创公司或其他竞争对手那里购买现成的芯片。即便是十多年前就开始布局 AI 芯片的 Google,有些工作也不得不依赖英伟达的 GPU 来完成。尽管芯片的价格高昂且缺货,但反而英伟达芯片可能是目前世界上成本最低的解决方案。
国际劳工组织(ILO)近日发布报告,表示生成式 AI 固然不会接管、替代所有人的工作,但对于以女性为主的文书岗位会产生较大影响。研究报告称尤其在发达国家,在文书相关岗位中女性员工的占比更高。在高收入国家,8.5% 的女性就业岗位可以实现高度自动化,而男性就业岗位占比为 3.9%。研究报告认为大多数工作岗位和行业开始朝着自动化方向发展,生成式 AI 是现有岗位的补充,而非替代。报告认为受生成式 AI 影响最大的岗位是文书工作,大约四分之一的工作可以通过自动化方式完成,交由生成式 AI 来生成文本、图像、声音、动画、3D 模型和其他数据。报告认为经理和销售人员等大多数其它职业受到生成式 AI 的影响并不会太大。
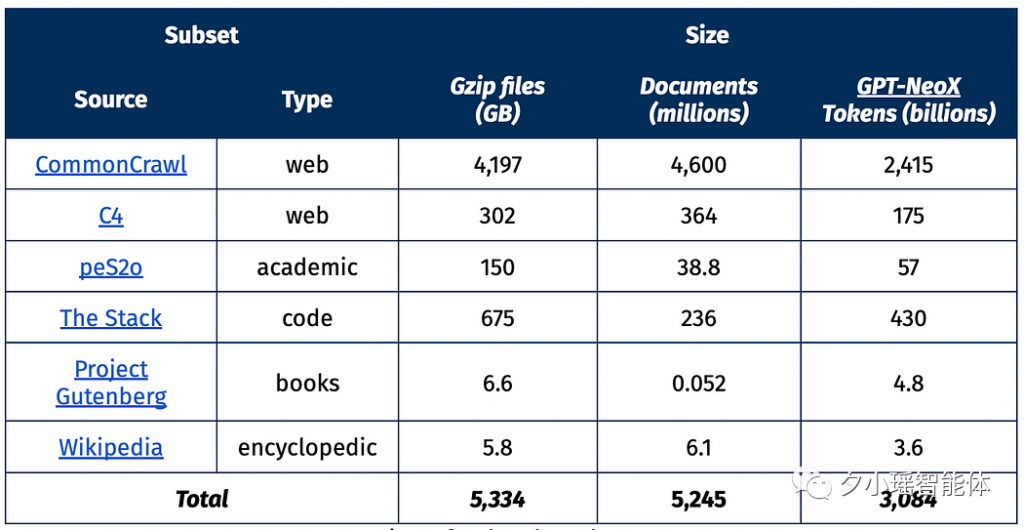
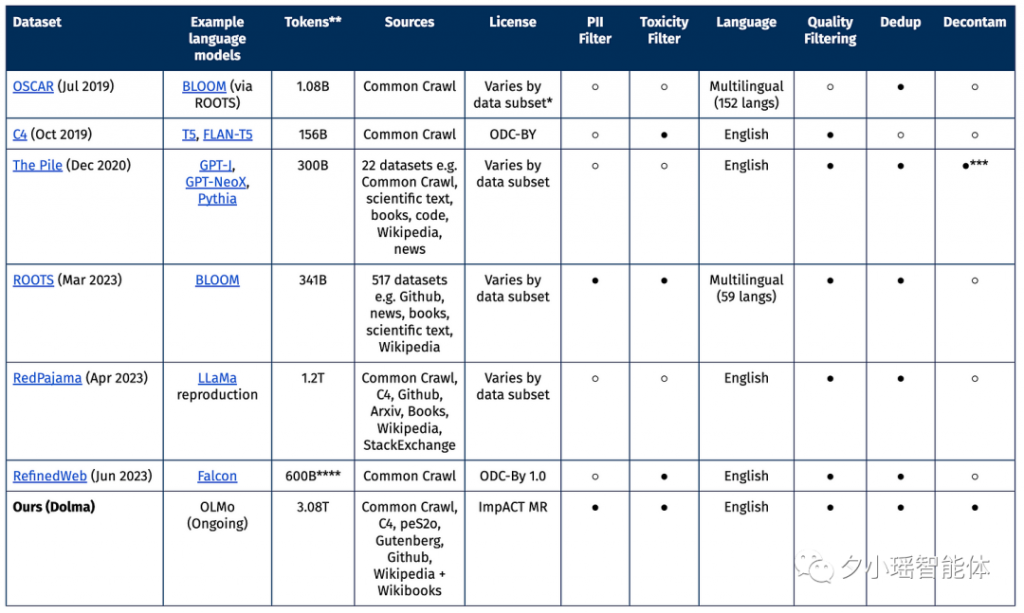
随着科技的飞速发展,大型语言模型已经成为了人工智能领域的热门话题。近日,AI研究机构Allen Institute for AI发布了一个名为Dolma的开源语料库,这个语料库包含了3万亿的token,成为了迄今为止最大的开源数据集。
1、Dolma的诞生背景
从今年3月开始,Allen Institute for AI开始创建一个名为OLMo的开源语言模型,旨在推动大规模NLP系统的研究。他们的主要目标是以透明和开源的方式构建OLMo,通过发布工程中的各种成果和文档来记录整个项目的进展。而Dolma就是这个项目中发布的第一个数据成果。这个数据集包含了来自网络内容、学术出版物、代码、书籍和维基百科材料的3万亿token。这个数据集已经在HuggingFace Hub上公开,任何人都可以下载。
为了捍卫其 AI 训练模型,OpenAI 可能不得不声称自己在“合理使用”该公司为训练 ChatGPT 等工具而收集的所有互联网内容。在潜在的《纽约时报》案中,这将意味着证明复制《纽约时报》的内容以生成 ChatGPT 回复不会与《纽约时报》构成竞争。
专家们告诉 NPR,这对 OpenAI 来说将是一个挑战,因为与谷歌图书( Google Books )不同,ChatGPT在一些互联网用户看来实际上可以取代《纽约时报》网站作为报道来源。谷歌图书在 2015 年赢得了联邦版权诉讼,因为其书籍摘录并没有成为“重要的市场替代品”,替代不了真正的书籍。
《纽约时报》的代理律师似乎认为这是一个切实而重大的风险。NPR 报道称,今年6月,《纽约时报》的管理层向员工们发布了一份备忘录,似乎对这个风险作出了预警。在备忘录中,《纽约时报》首席产品官 Alex Hardiman 和代理总编辑 Sam Dolnick 表示,《纽约时报》最大的“担忧”是“保护我们的权利”,不受生成式 AI 工具的侵犯。
备忘录问道:“我们如何才能确保使用生成式 AI 的公司尊重我们的知识产权、品牌、读者关系和投资?”这与许多报社提出的一个问题相呼应,许多报社开始权衡生成式AI的利弊。上个月,美联社成为了首批与 OpenAI 达成许可协议的新闻机构之一,但协议条款并未披露。
今天美联社报道,它已与其他新闻机构一起制定了在新闻编辑室使用 AI 的标准,并承认许多“新闻机构担心自己的材料被 AI 公司未经许可或付费就擅自使用。”今年 4 月,新闻媒体联盟( News Media Alliance )发布了一套 AI 原则,坚持要求生成式 AI 的“开发者和部署者必须与出版商就后者的内容使用权进行谈判”,以便将出版商的内容合法用于 AI 训练、发掘信息的 AI 工具以及合成信息的 AI 工具,从而竭力捍卫出版商的知识产权。
第二季度,腾讯游戏业务收入为445亿元。凭借《VALORANT》《胜利女神:妮姬》《Triple Match 3D》等游戏的出色表现,腾讯游戏国际市场收入达127亿元,同比增长19%,相当于本土游戏市场收入的40%。财报显示,二季度手游和端游的月活跃账户数和日活跃账户数均实现同比增长,而且腾讯游戏近两年发布的三款新游戏在第二季度中国手游时长排名前列。
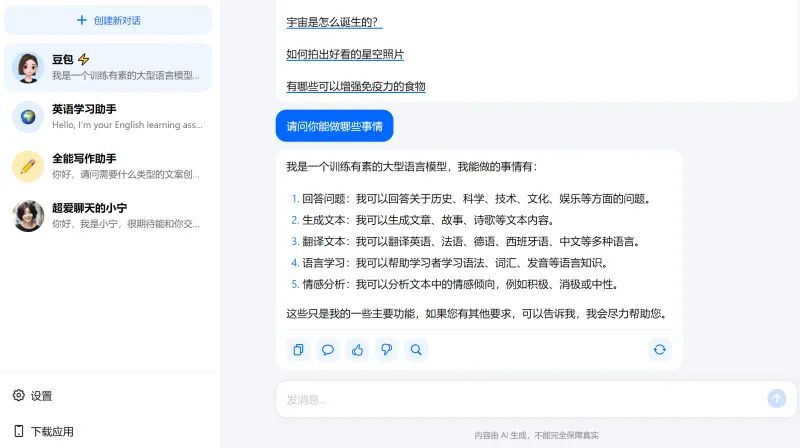
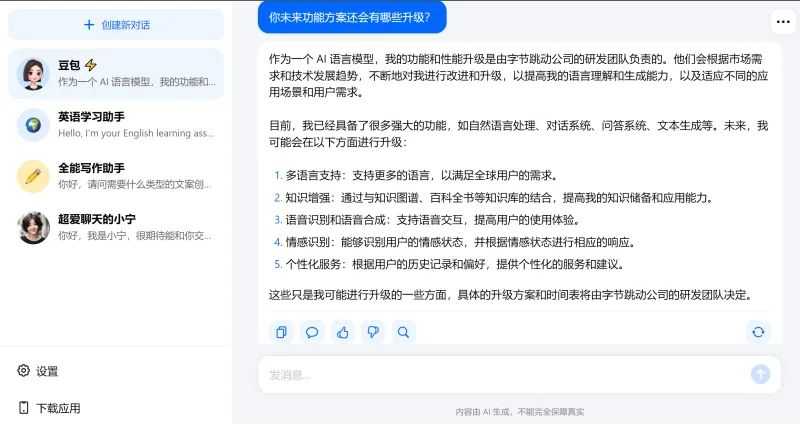
节跳动首个大模型独立App近日上线,是一个AI对话产品,叫“豆包”。并启动测试,网页版、移动端均已上线,支持手机号、抖音账号、Apple ID 登录。目前拥有文生文的功能。 豆包的官网为www.doubao.com,由北京春田知韵科技有限公司开发并运营,后者由字节旗下的北京抖音信息有限公司100%控股。 目前可在其官网直接注册使用,或通过官网提供的二维码下载App,不需要邀请码。该产品前身正是字节内部代号为“Grace”的AI项目。提供“豆包”、“英语学习助手”、“全能写作助手”、“超爱聊天的小宁”等四个虚拟角色,为用户提供多语种、多功能的AIGC服务,包括但不限于问答、智能创作、聊天等。“豆包”项目组人士回应称,“豆包”是一款聊天机器人产品,还处于早期开发验证阶段,这次上架仍是小范围的邀请制测试。
不过,不断膨胀的成本以及与数据隐私和延迟有关的问题导致企业向公有云的迁移速度放缓。然而Uptime Institute Global Data Center最近的一项研究发现,约33%的受访者已经从公有云回迁到数据中心或合作设施。然而,在那些回迁的企业中,只有6%完全放弃了公有云。大多数采用混合方法,同时使用本地和公有云。
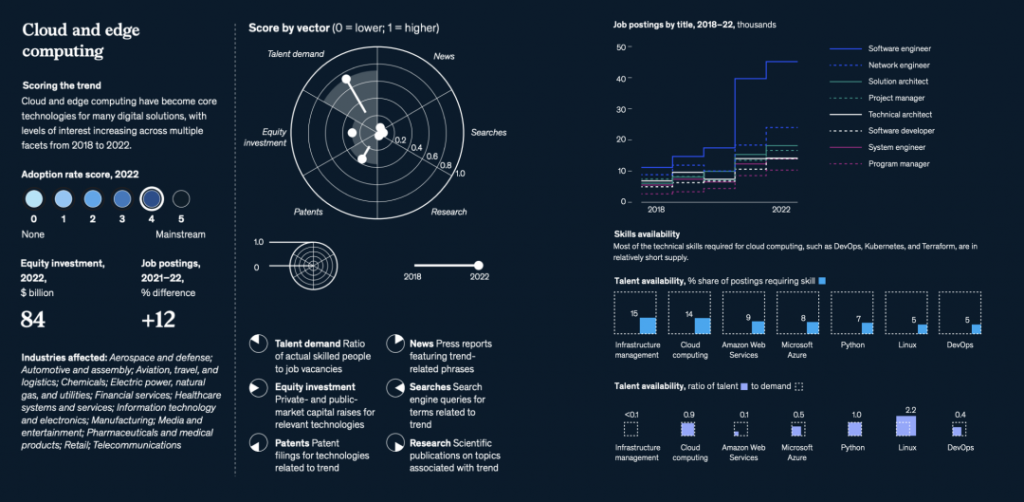
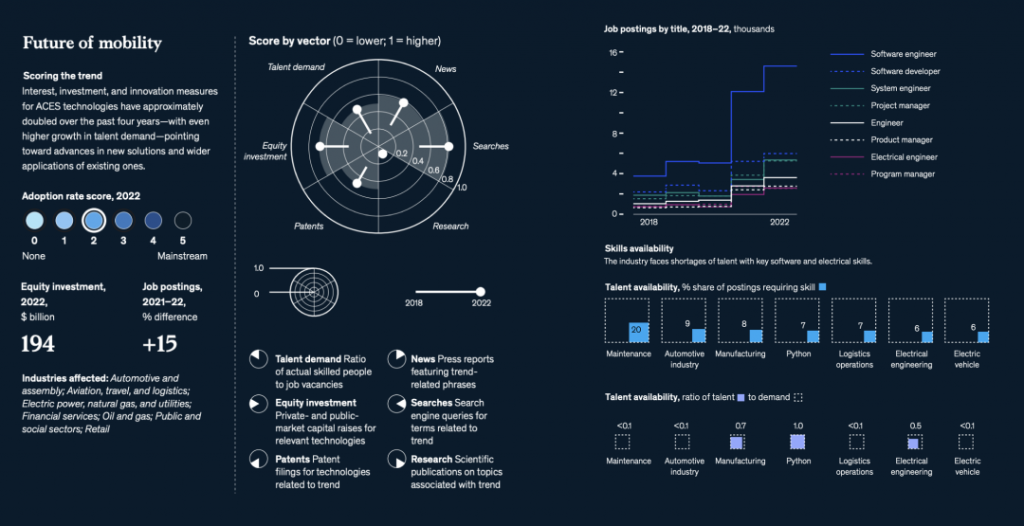
在汽车大规模生产开始一个多世纪后,出行正在经历第二个重要的转折点:向自动驾驶、连接性、车辆电气化和共享出行(ACES,Autonomous, Connected, Electric and Shared vehicles)技术的转变,甚至先进空中移动技术,如垂直起降电动飞行器(eVTOL)也在快速推进。