
法律大模型ChatLaw登场!北大学生团队,两天百万关注
有人做了统计,截止到今天,国内已经公布的大语言模型LLM已经达到93个,距离“百模大战”仅差一步之遥。

有意思的是,这些大模型的主体所在地有45%在北京,而其中最知名且开源的大模型莫过于清华的ChatGLM-6B/130B。作为中国两大顶级学府之一,清华的ChatGLM早就名声在外,成为了中文大模型的微调底模标配。
直到几天前,一街之隔的北大学子们终于拿出了他们自己的语言模型:ChatLaw

严格来说,ChatLaw不能算是大语言模型。一方面,它是在其他大模型基础之上做的专项训练;另一方面,显然你也不能指望法律模型给你写小红书写脚本,把它看成是垂直模型更恰当一些。
按理说,大模型发布了这么多,咱们早就看麻木了。但ChatLaw发布当晚就在知乎冲到了热榜第一的位置,很短的时间内话题浏览量就超过150万。
就连我随手回复个求内测名额,也能堆起50层回复。
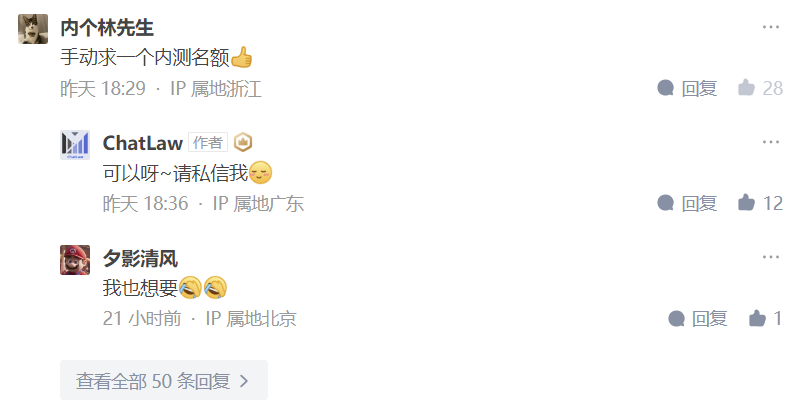
在Github项目库里,点赞的星星数量仿佛旱地拔葱,直接腾空而起,目前已经有1.7K,妥妥的热门项目。
那么,这个模型究竟做对了什么,让见过市面的人们也争先恐后的排队体验?
除了最基础的法律条文问答,这三件事最让人眼前一亮:
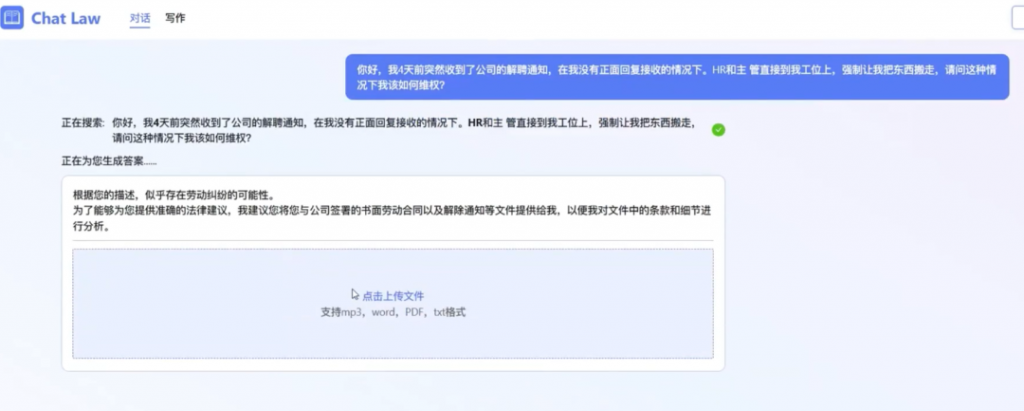
其一,不仅是法律条文的问答,还能上传文档。比如在劳动纠纷中支持上传劳动合同,将重要信息结构化展示。
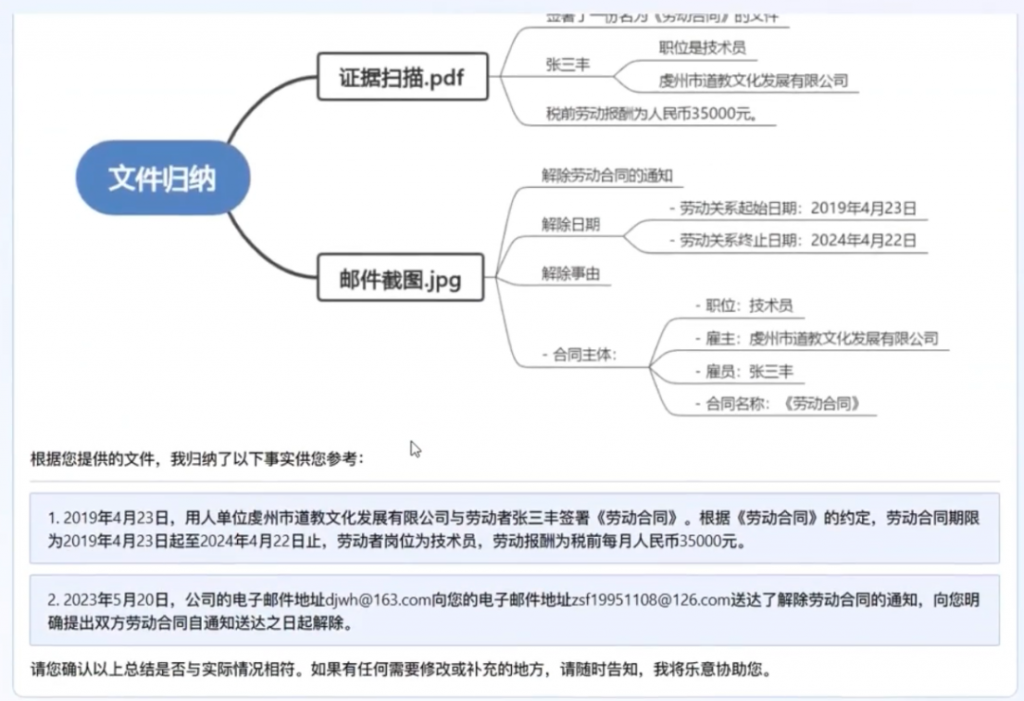
其二,支持上传对话录音。这很接近法律实践中的举证环节,ChatLaw抽取对话录音的信息,结构化展示,刚登场就是多模态级别。
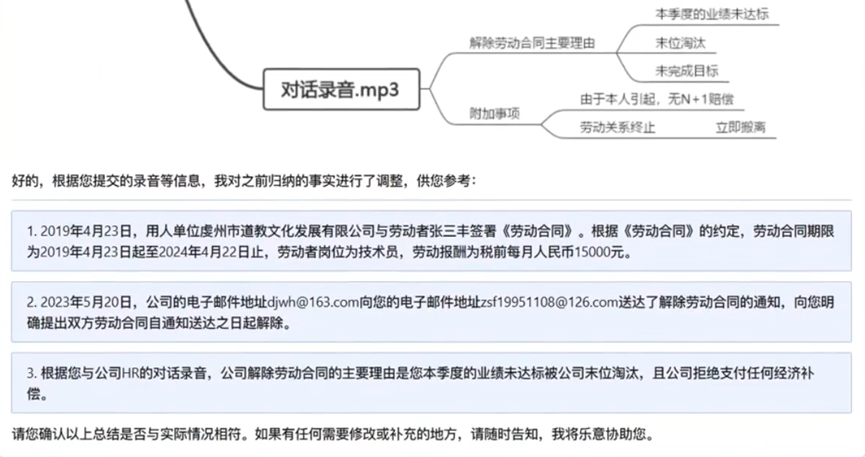
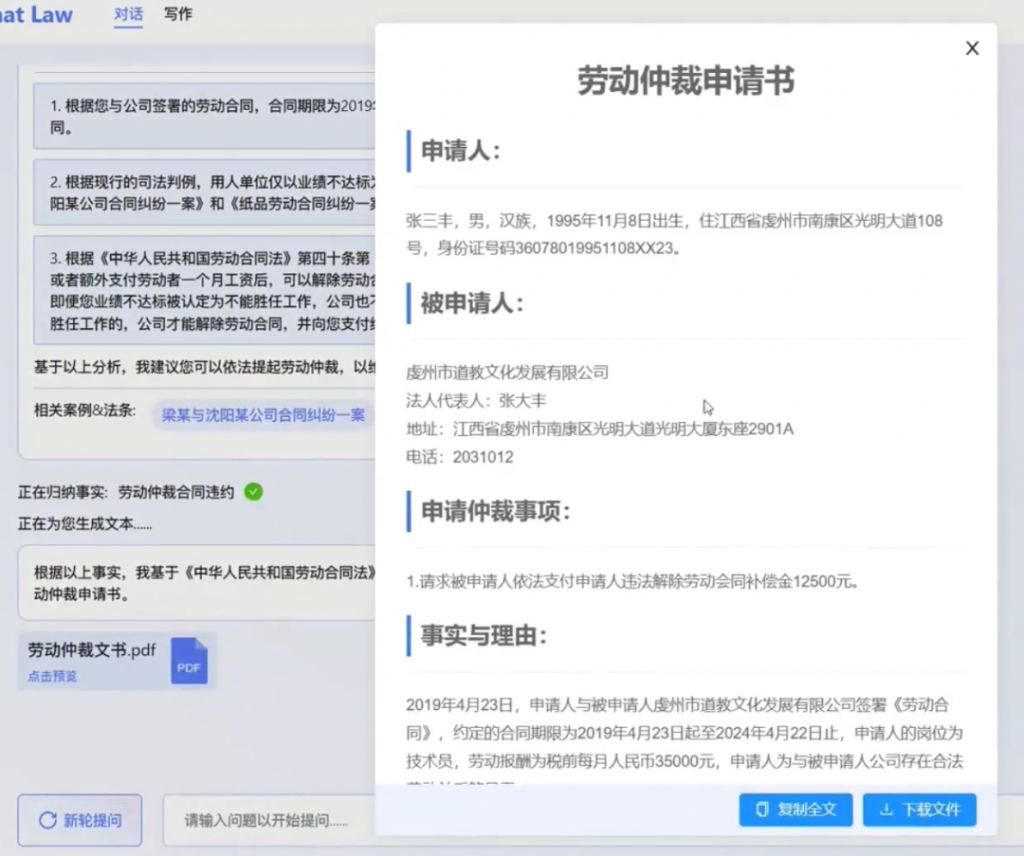
其三,法律文书撰写。基于用户举证,结合判例和法条,为用户撰写法律文书,比如劳动仲裁申请书。
如果要用一句话评价这个项目团队,我只能说他们太会举例子了,简介视频都能拿捏社会热点,产品宣发在宣发上就已经遥遥领先其他大模型。
展开来说,可以分为模型技术层面和社会需求层面。
从模型技术上讲,ChatLaw并没有多先进,而是典型的应试教育+大力出奇迹的结合体。
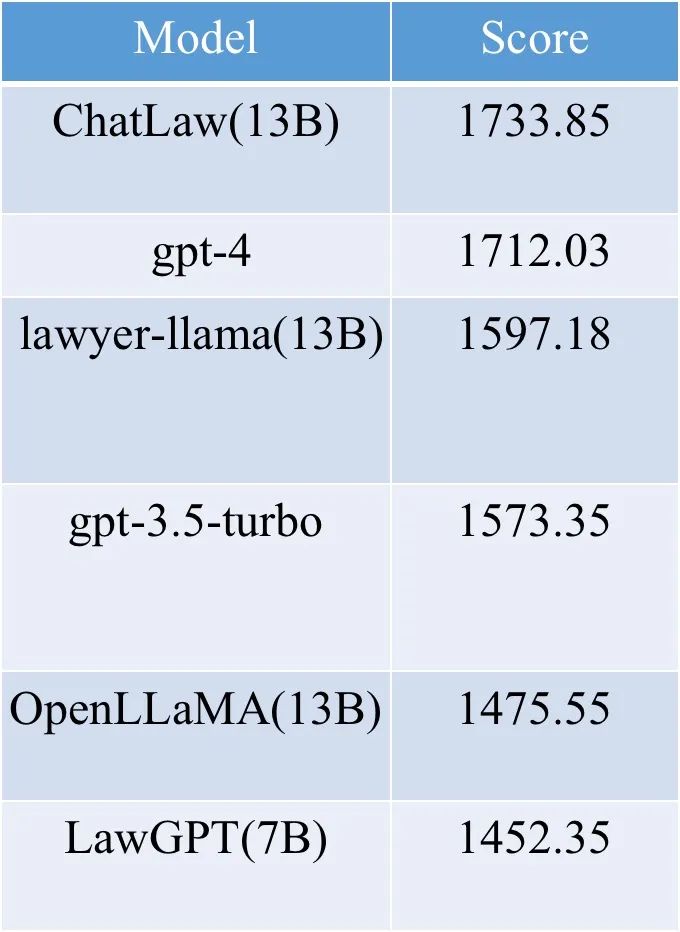
项目团队已经训练出三个版本,底层大模型来自LLaMA,其中:
学术demo版ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,中文表现很好,但是应对逻辑复杂的法律问答时效果不佳,需要用更大参数的模型来解决。
学术demo版ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据。
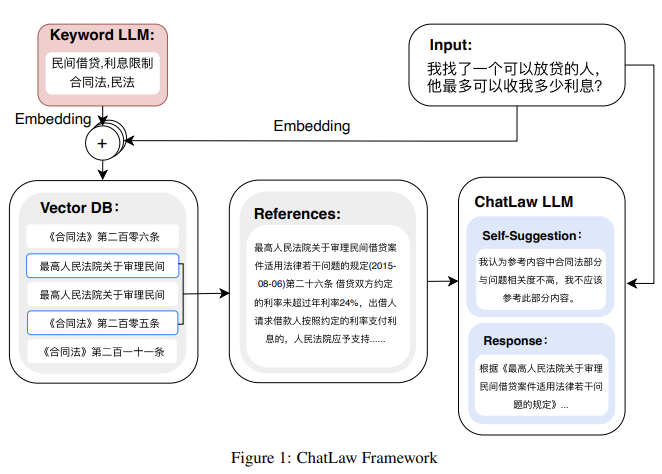
ChatLaw-Text2Vec,使用93万条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,例如:
在训练数据上,项目团队的数据主要由论坛、新闻、法条、司法解释、法律咨询、法考题、判决文书组成,随后经过清洗、数据增强等来构造对话数据。比如像下面这样的对话方式:

在类似这样的大量先验数据投喂下,ChatLaw在司法考试的大模型对比中成绩超过了GPT-4,虽然超过的不多,但证明了这种训练方式的有效性。更具体一点,在训练中加入大量司法考试的选择题作为训练数据,只要让模型牢牢“记住”答案,分数自然就上去了。
为此,团队模型训练上也总结出了三条经验:
一是引入法律相关的问答和法规条文的数据,能在一定程度上提升模型在选择题上的表现;
二是加入特定类型任务的数据进行训练,模型在该类任务上的表现会明显提升,比如问答题数据;
三是大力可以出奇迹,法律选择题需要进行复杂的逻辑推理,参数量更大的模型通常表现更优。
从社会需求上讲,ChatLaw团队做了一件大好事,既是为社会创造了普惠工具,又给大厂们好好上了一课。
自从ChatGPT问世,我们一直在思考一个问题,它对社会带来的具体贡献是什么?
是降本增效,是时代变革,是几天一个王炸的颠覆?
够了,不要再被这些只会贩卖焦虑吸引流量的媒体和视频洗脑。
就这么说吧,GPT引发的新一轮AI浪潮是一种显著的创新,但不足以跨越从好玩到好用的鸿沟。它能提升一部分工作流程的效率,但还不足以取代人类。
为什么ChatLaw要大费周章的投喂90多万条真实的司法数据,就是因为通用大语言模型看起来很厉害,实际上到了垂直领域并不能直接用。
比如在司法实践中就发生过这样的乌龙:
美国有一名旅客起诉航空公司,他的代理律师提交了诉状,并引用了六个判例论证起诉要求的合理性。每个判例有原告有被告有法官甚至还有判决书全文,看起来有模有样。
但无论是航空公司还是主审法官,都无法在数据库中查到这六个判例的任何一例。最后代理律师坦言,这些判例都来自ChatGPT之手。
美国人用美国人开发GPT都能胡编法律案例,想象一下用它来咨询中国法律会发生什么。
正应了那句话,你以为它懂得很多,直到有一天它说到了你擅长的领域。
或者换句话说,没有经过足够数量的数据微调或者再训练的大语言模型,充其量就是个社牛:你跟它说什么它都能接上话茬,但是不是胡说八道,请你自行判断。
我们对于生成式人工智能的心态,应当是战术上不要轻视,战略上不要迷信。
很快,我们就会有超过100个大模型,请不要再无谓的重复训练那些超越这个或者那个的模型了。
真的有那么多资金烧算力,不如想ChatLaw一样,做个本地化的,且社会大众都能用得上的AI工具。
就像Demo中预设的这些问题,普通人并不知道如何拿起法律武器保护自己权益,也不知道怎么找或者找什么样的律师帮自己维权。

也难怪ChatLaw刚宣布内测,就吸引如此之多的人去排队等待体验。
什么是刚需,这就是刚需!普法之路任重道远。
再看看下面几个例子,请点开来仔细看。以后微博热搜再发小作文,多少先过一遍ChatLaw再评论不迟。
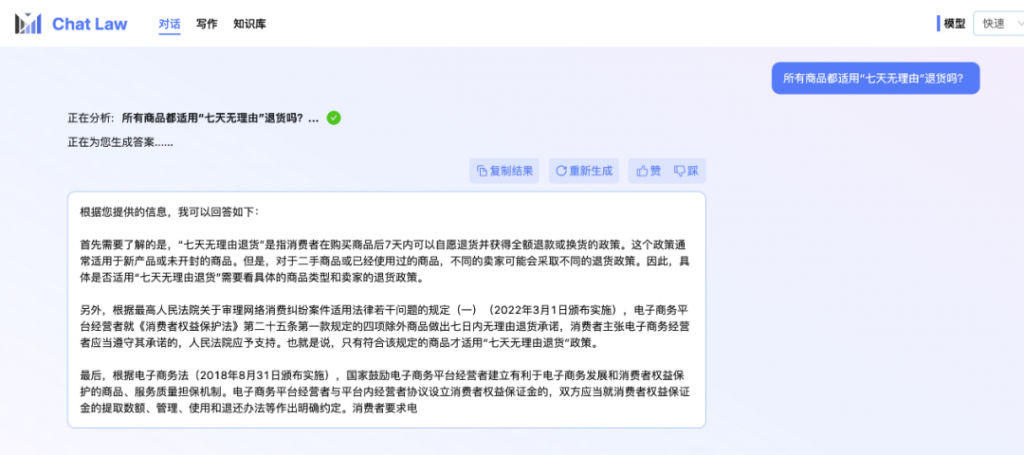
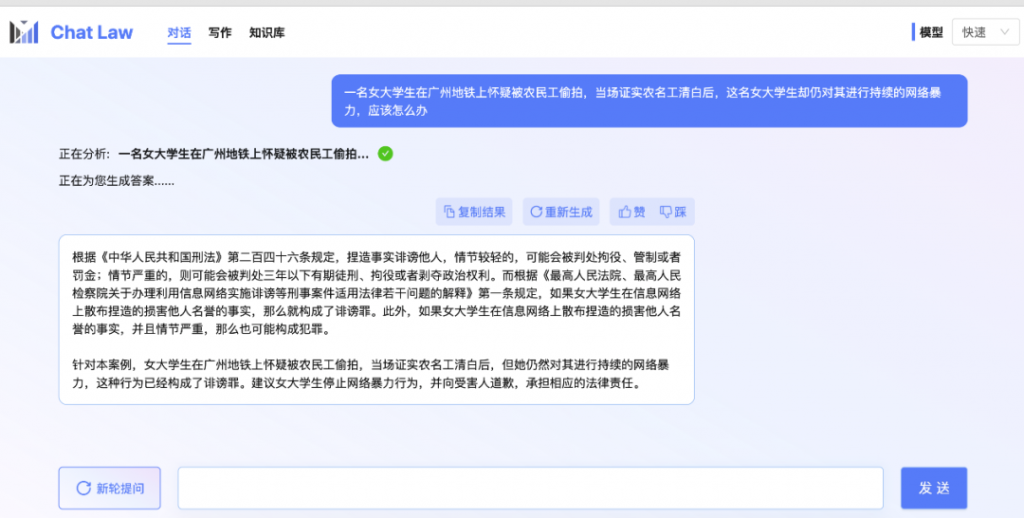
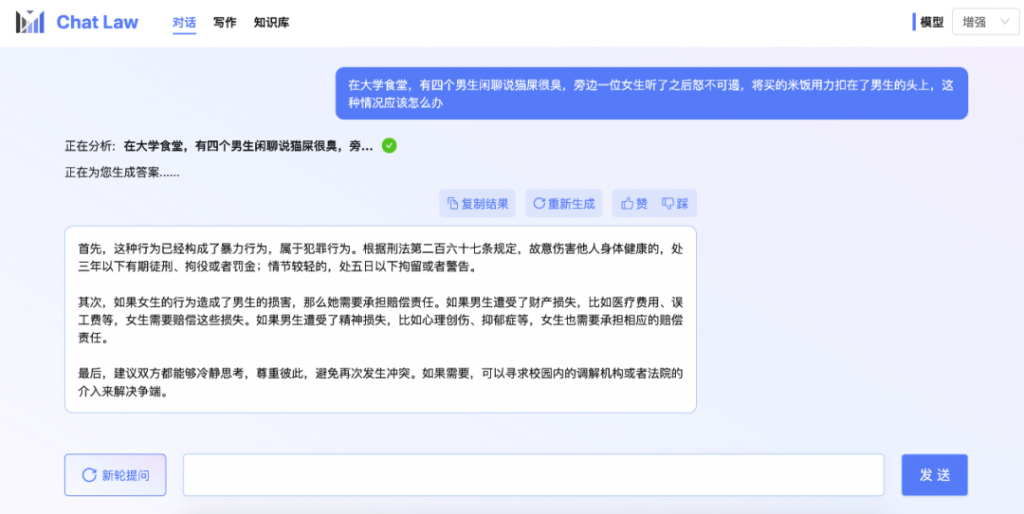
这群来自北大信息工程学院的学生们,清晰的勾勒出下一步的开发计划:
一方面法律场景的真实问答通常涉及很复杂的逻辑推理,为了提升逻辑推理能力,必须训练30B以上的中文模型底座;
另一方面法律是一个严肃的场景,在优化模型回复内容的法条、司法解释的准确性上还可以进一步优化,预计还需要两个月的时间,大幅减轻大模型幻觉的现象。
当大厂们还在挖空心思筑高墙炒概念,拿开源冒充原创,重复训练低质量闭源模型时,一群学生肩负起了为社会创造开源普惠工具的责任。
祝ChatLaw好运!
论文地址:
https://arxiv.org/pdf/2306.16092.pdf
Github:
https://github.com/PKU-YuanGroup/ChatLaw
官网:
开源Demo: