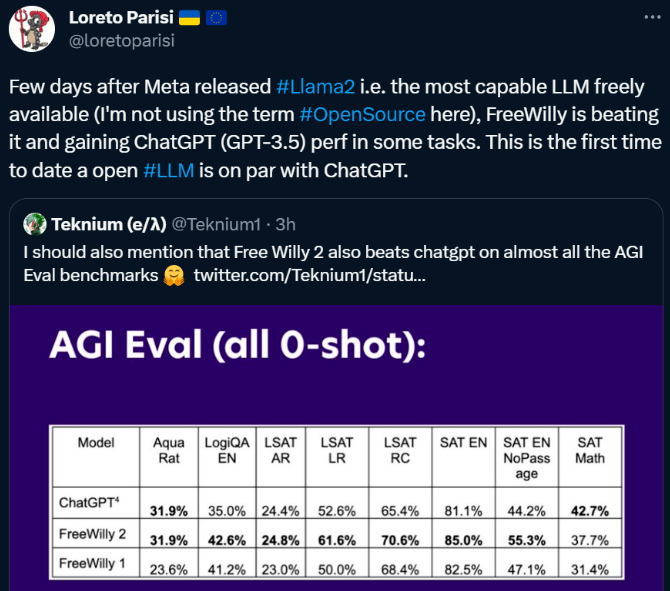
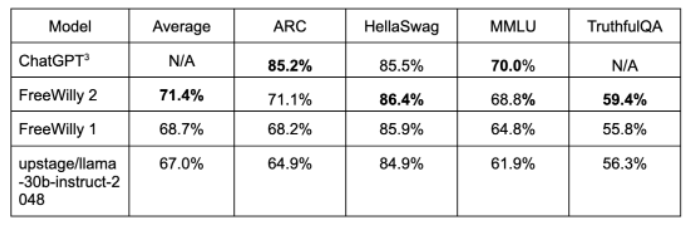
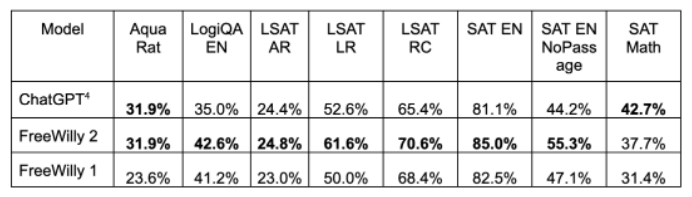
从推出开始,该产品将在试点计划中推出,用户只需上传自己空间的图片即可想象自己不同风格的家。使用上传的图像作为启动提示,Decorify 会生成多个室内设计选项,同时提供进行相关购买的直接链接。他们也起了一个口号,叫Meet Decorify™, your shoppable AI interior designer.翻译一下,就是“遇见 Decorify™,你买得起的AI室内设计师。”具体是怎样一种表现呢,也正如下方gif图片所示。
Wayfair 首席技术官 Fiona Tan 表示:“我们为客户开发或部署的任何东西……都必须支持我们的使命,即帮助任何地方的每个人营造家的感觉。” 通过这种务实的视角来看待生成式人工智能,能够确定部署开发资源的地点和时间的优先顺序,并确保像 Decorify 这样的应用程序让客户满意。Wayfair 已经在客户服务和营销等关键业务领域使用生成式人工智能。
目前完美世界已将AI技术应用于研发管线的多个环节中,如智能NPC、场景建模、AI绘画、AI剧情、AI配音等,也正在尝试AI融合驱动的完整形态案例——复合应用AI in Game Play,包括场景信息、角色信息、情节发展、玩家行为、对话等均由AI演算。将AI融入游戏玩法中,为不同玩家提供不同的感官及游戏体验。
比如,天文学家们试图构建宇宙模型来解释宇宙的起源、演化和结构,然而目前囿于算力,各类宇宙模型都只能用有限的特征来描述它,这对于庞大的宇宙来说并不准确。吴家骥指出,如果利用AI for Science(即人工智能驱动的科学研究)的思路,通过结合已有的天文观测数据和人工智能技术,就有可能探索出新的宇宙模型。这种模型具有非常好的表征能力和泛化能力,可以在没有大量数据标记的情况下进行自我学习和进化。
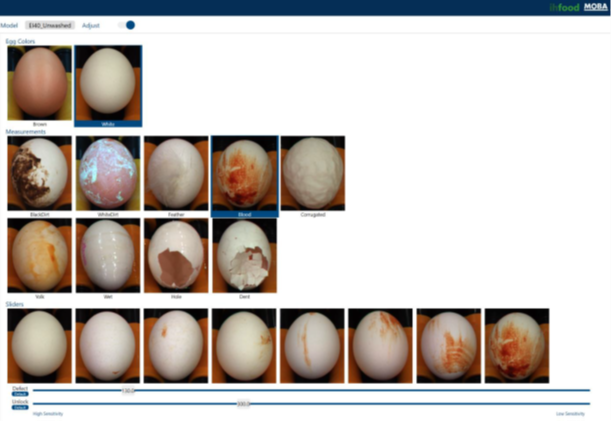
我们深耕蛋品行业长达75年,对客户面临的挑战有着深刻的了解。我们拥有多项突破性的创新技术,它们能够提高 A 级禽蛋的比例和禽蛋的盈利能力,同时简化清洗程序,降低禽蛋分级站的劳动力需求。这些特点都可以通过 Omnia PX系列分级机 + 人工智能裂纹和脏破蛋检测系统和人工视觉称重系统来实现!这些创新技术无需直接接触鸡蛋,它将尽可能降低交叉污染的几率,并且简化了清洗程序,因此提高了食品安全性。人工视觉称重系统专为水洗蛋市场而设计,将率先在北美市场隆重亮相。
我们通过探索新的视觉系统与人工智能(也称为“AI”)相结合的潜力,实现了这些功能。我们全球客户超过 5,000个,我们的系统处理了惊人的 10 亿枚禽蛋,因此我们有独特的视角来充分利用 AI 赋能的全部学习能力。
AI视觉称重系统
通过大量研究和开发,我们成功地开发了一种使用 AI 技术给禽蛋称重的创新方法。通过使用包含数千张禽蛋图像及其相应重量信息的庞大数据库,对我们的 AI 系统进行训练,该模型现已能够识别每枚禽蛋特有的视觉特征,并将之与其特定重量相关联。一旦 AI 模型经过训练,它就可以通过分析其图像,无缝地预测新蛋的重量。通过物理接触进行禽蛋检测的时代已一去不复返 — 禽蛋分级机只需捕获每枚禽蛋的多张图像,借助我们先进的技术,即可提供准确的重量估计值。
现在,MOBA可以为 Omnia PX530型 和 PX700型禽蛋分级机配置AI 称重系统、AI禽蛋裂纹检测系统和AI脏破蛋检测系统。此 PX+ 提供了综合解决方案,无需直接接触鸡蛋,操作简单,简化了清洗程序,并尽量减少了维护工作量。PX+ 凭借其可靠的性能,使我们的客户能够集中精力提高其业务成果。
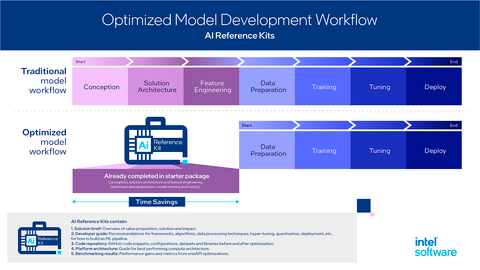
最近,芯片巨头英特尔与埃森哲合作,向开源社区提供了包含34 个开源 AI 参考套件的产品组合,这标志着英特尔在促进开源 AI 生态发展方面迈出了重要的一步。这些参考套件可以帮助开发者和数据科学家更快更轻松地部署人工智能,为多种架构的本地、云端和边缘计算环境提供 AI 服务。
每个套件都包含了模型代码、训练数据、机器学习管道指令、相关库和oneAPI 组件等内容,旨在优化 AI 性能,简化 AI 引入应用的过程。这些套件基于英特尔端到端的 AI 软件产品组合和开放的 oneAPI 异构编程模型构建,可以充分发挥英特尔 AI 芯片的计算优势。与传统的模型开发流程相比,英特尔 AI 参考套件可以极大地提高工作效率。
这些预配置的AI 套件覆盖了众多关键行业的典型应用场景,如消费品、能源、金融服务、医疗健康、制造业、零售业等。在这些应用场景中,英特尔 AI 参考套件展现出显著的优势:
SMP 2023 ChatGLM金融大模型挑战赛(The Evaluation of Large Model of Finance Technology,SMP2023-ELMFT)由中国中文信息学会社会媒体处理专委会主办,智谱 AI、安硕信息、阿里云、魔搭社区、北京交通大学联合承办,天池平台为指定赛事平台。第十一届全国社会媒体处理大会(SMP 2023)将于2023年11月在合肥召开。SMP 大会专注于以社会媒体处理为主题的科学研究与工程开发,为传播社会媒体处理最新的学术研究与技术成果提供广泛的交流平台,SMP 2023 由中国中文信息学会社会媒体处理专委会主办,安徽大学、中国科学技术大学和合肥工业大学联合承办。
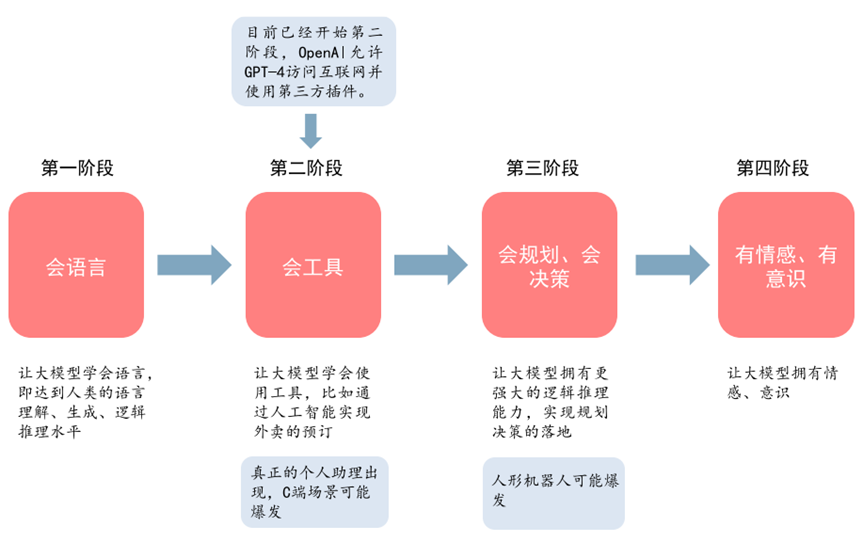
针对通用人工智能的定义及发展现状,北京智源人工智能研究院院长黄铁军指出,“通用人工智能”往往对应GAI(General Artificial Intelligence)和AGI(Artificial General Intelligence)两个概念,GAI是指(具有)通用性的人工智能,AGI严格意义上叫做人工通用智能。两者的含义具有根本性差别,通用人工智能强调的是通用性,而AGI强调的是全面超越人类的一种人工智能。“今天我们说的大模型,实际上是指从通用人工智能向真正超(越)人的人工智能的过渡阶段。”
由ChatGPT和GPT-4引发的“人工智能狂潮”远比人们预想的持续更久,伴随而来的争议与忧虑也在不断发酵。回归科学,反思以GPT-4为代表的AI能力的边界:它能做什么?不能做什么?最重要的是,人类现在必须采取什么行动来实现“有益的AI”?《中国新闻周刊》近日就以上问题专访美国加州理工学院电气工程和计算机科学教授亚瑟·阿布-穆斯塔法(Yaser S. Abu-Mostafa)。他是人工智能领域的知名专家,同时也是IEEE神经网络委员会的创始人之一,曾在多家科技公司担任机器学习顾问。