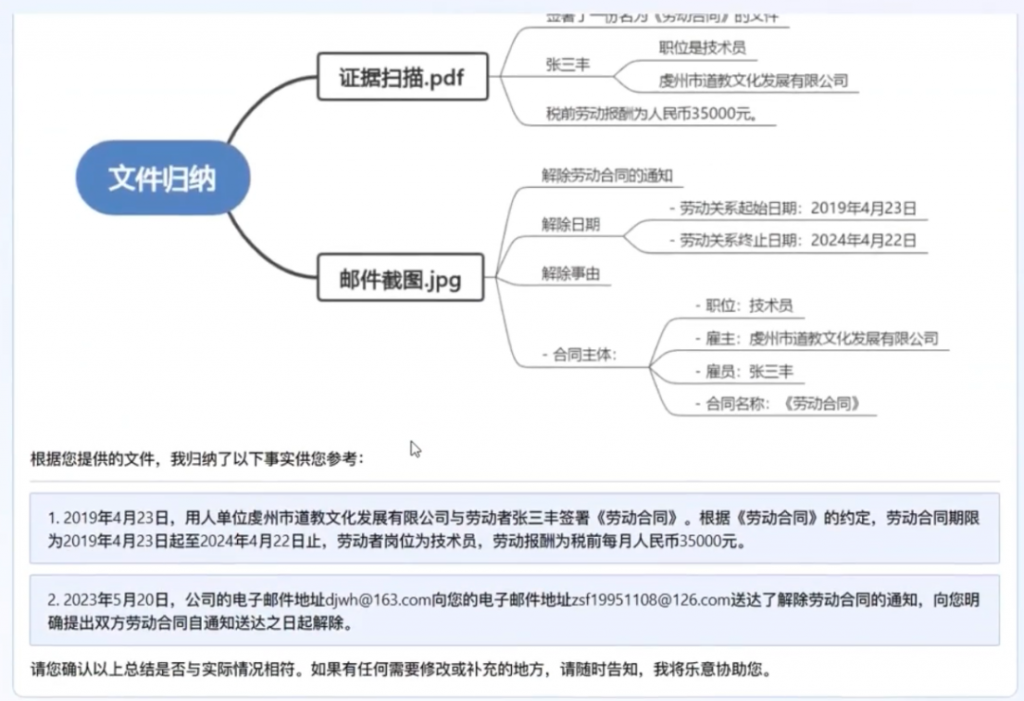
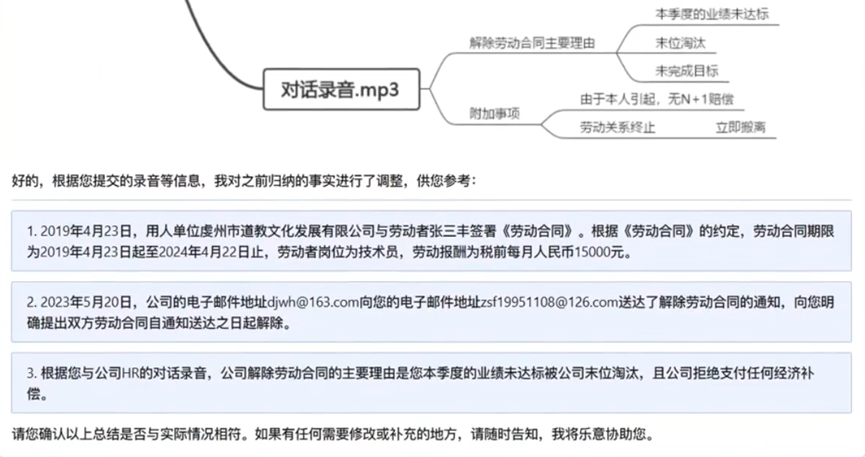
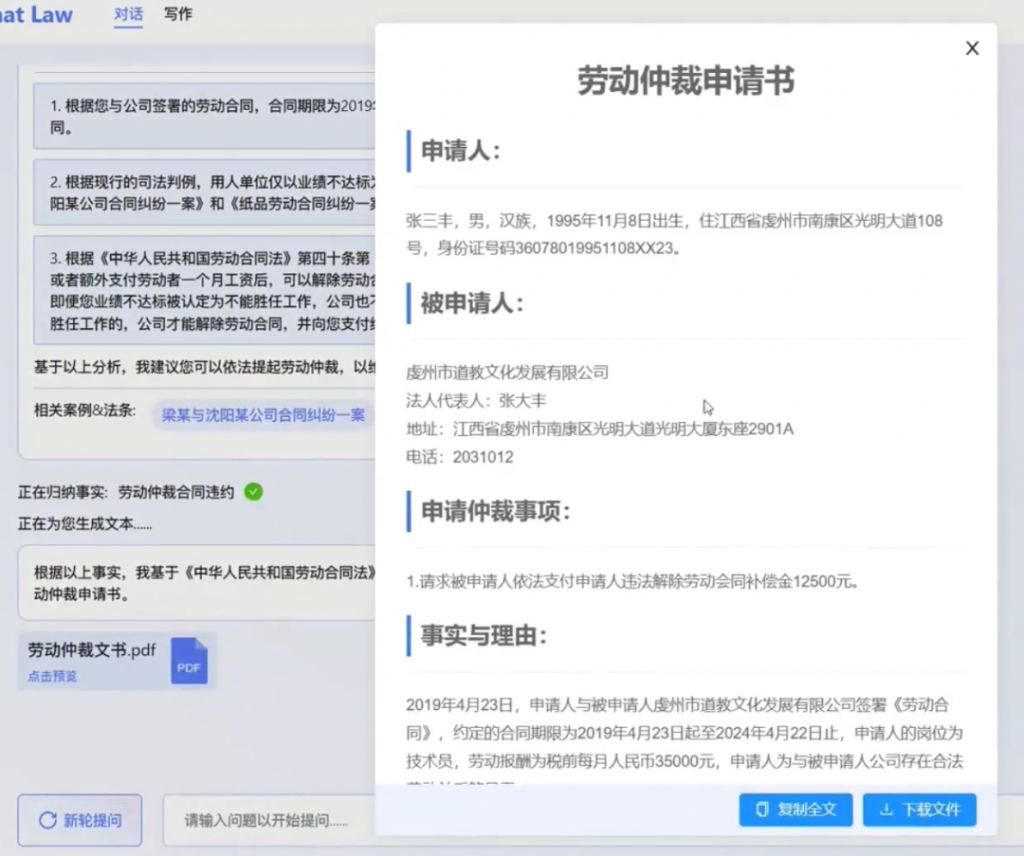
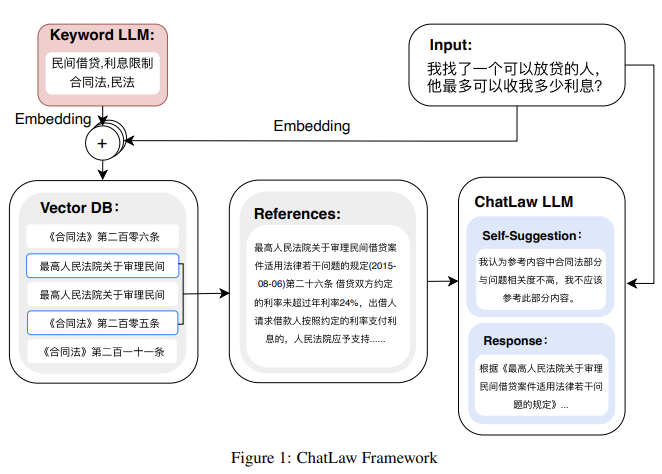
AIGC大热后,设计师林俪和版师张宇都觉得自己混得比对方惨,经营模特摄影工作室的“浪猪灰头”也觉得正在失去生意。
4万亿服装行业,正在被新一波AI技术改变,且冲击和机遇并存——麦肯锡分析,未来3到5年,生成式AI可能会帮助服装、时尚及奢侈品行业的营业利润创造1500亿美元的增量,乐观估计可高达2750亿美元。
记者注意到,AIGC对服装行业的影响主要集中于商品企划、产品设计、零售终端三个环节,AIGC提升设计师效率、数字人+3D服装给消费者带来新体验,这些新内容都将给服装行业带来新机会。
只不过,要想解决行业内从设计到生产到营销多环节的难题,并非易事。服装行业也曾经过几轮AI洗礼,从RNN(递归神经网络,1990年提出)到GAN(生成对抗网络,2014年提出)到如今的Diffusion(扩散模型),每一波AI都试图打通整个产业链。那么,这一轮生成式AI会对服装行业产生哪些影响?AIGC将影响哪些岗位就业?AI能力外溢到供应链,能够产生多大影响?
01设计师、版师、模特,谁被冲击?
1 AIGC干不掉设计师
设计师和版师是服装设计中的主要岗位,一个负责将天马行空的灵感变成一张张图纸,一个负责将图纸变成样衣。
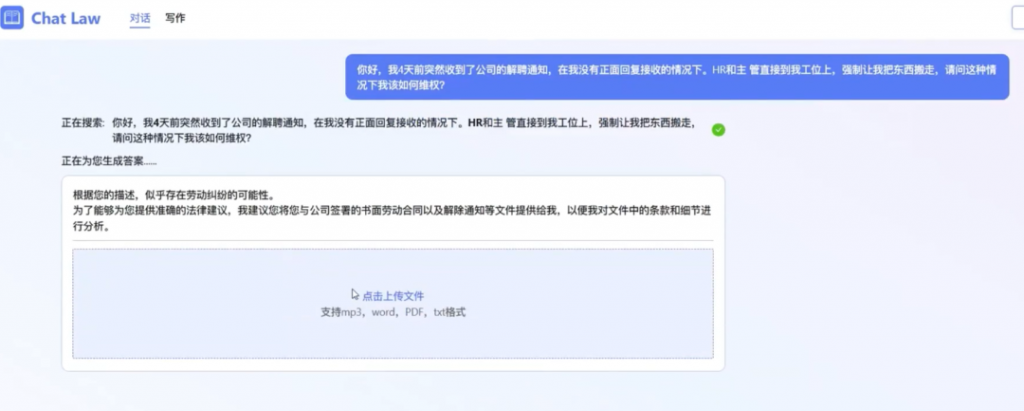
Midjourney和Stable Diffusion一度给设计师林俪带来很大的职业生涯危机,输入提示词,5秒内生成六张设计图,还可以不停更新。林俪从事快时尚设计快5年,见过不少设计高手,还是被Stable Diffusion的生成效果惊艳了一把,“关键是速度快且量大,感觉分分钟要失业。”
“上新”是快时尚的命脉,品牌企业对创造力
和效率有极致追求。坚持用了半年Midjourney和Stable Diffusion,林俪放心下来,“大模型确实在生成速度上远超设计师,但AIGC只是一个素材生成方式,输入什么提示词,需要哪些元素,到底要用哪张,这些都需要我们来做选择。我现在的灵感图都由AIGC完成,效率大概提升了3倍。”
而且,AIGC目前只是在单款服装的设计上提供了灵感。除了单款设计,设计师还需要做一些系列企划——比如当季主推的款有哪些系列,哪些款式搭配起来好看,常规款和主推款怎么搭配。甚至这些款式在门店的陈列,都得在设计师企划时去规划——主推款式放在什么位置,效果如何,在门店如何陈列。显然这些工作内容都超出AIGC的范围。
“单从款式设计上来说,其实绝大多数服装企业都有自己的版型基础,也就是大体‘规矩’,在这个‘规矩’内,设计师会去判断用什么样的颜色、辅料、装饰性元素。AIGC就是在这个环节给出灵感和帮助。”林俪补充。
AIGC到底能帮服装设计师做什么?知衣科技创始人兼CEO郑泽宇认为主要有三方面:
第一,提供灵感;第二,快速生成出大量符合提示词的图片;第三,降低设计的成本,提高设计的精度和投产效率比。
“但目前AIGC能够达到的效果只有第二点,第一和第三步还在测试中,1-2年内实现还有困难。”郑泽宇补充。
郑泽宇也认为,AIGC还远远谈不上取代设计师,“AIGC只是一个素材生成方式,判断这些图是否是设计师或品牌方想要的,到底用哪张,这才是最重要的问题。”
2 20年后再无版师?
AIGC取代不了设计师,但可以取代版师。这是凌迪科技Style3D首席科学家王华民对本轮AI的预判。
版师指从事服装制版工作的人,制版在整个服装生产流程中承上启下——对上,要和设计师沟通样衣的工艺细节;对下,要向样衣工或生产工厂交代缝制样衣的注意事项,把控样衣(非大货)质量。
一件衣服的设计图出来后,还得经历“打版-修改-再打版-再修改”的过程。“有时候一个装饰是要2.5厘米还是3.5厘米,得样衣出来之后再看效果,因为这就是一个感觉的东西,就是大一点小一点,左一点右一点,得来回调整。”林俪回了一个不忍直视的表情。
这个过程往往耗时耗力,“设计师很多是不懂打版的,或者懂得不多,他需要和版师反复沟通,时间成本和沟通成本就会很高。”王华民认为。
和林俪在同一公司的版师张宇也认同AIGC对版师们的威胁,版师要将设计师的2D稿子变成生产需要的CAD图,同时生产出样衣,供设计师进行修改。“2D转3D,这个活儿很专业也很套路化。现在一些复杂的版,我们已经不用自己立裁,而是把3D效果给到设计师去看,让他们直接在3D上做调整。”张宇说。
在凌迪的Style3D AI产业大模型中,只要将相应的服装拖入设计框,点击AI生成版片,几秒内可以将版片和3D效果独立出来。

图片来源:凌迪科技Style3D官网
“20年后,当我们的模型足够大,设计师会变得更全能,因为他的工具更多了。”王华民补充,“到时候,最完美的情况是设计师自己设计,自己打版,甚至人人都可以成为设计师。”
3 电商不需要模特了?
除了设计师和版师,模特界也开始“地震”。
在电商平台的款式的详情页背后,是十几个人的分工协作,需要从请模特、摄影师、造型师、助理等+准备服装+影棚租赁or出外景+选片+修片+配图说明,成本百元到千元不等。
微博账号“浪猪灰头”曾发出一张模特摄影工作室的价格表:一天8小时拍摄,需要支出3.6万元。其中摄影费(包含400张修图)1万,男模和女模费用超2万,化妆费2000元,搭配费4000元。
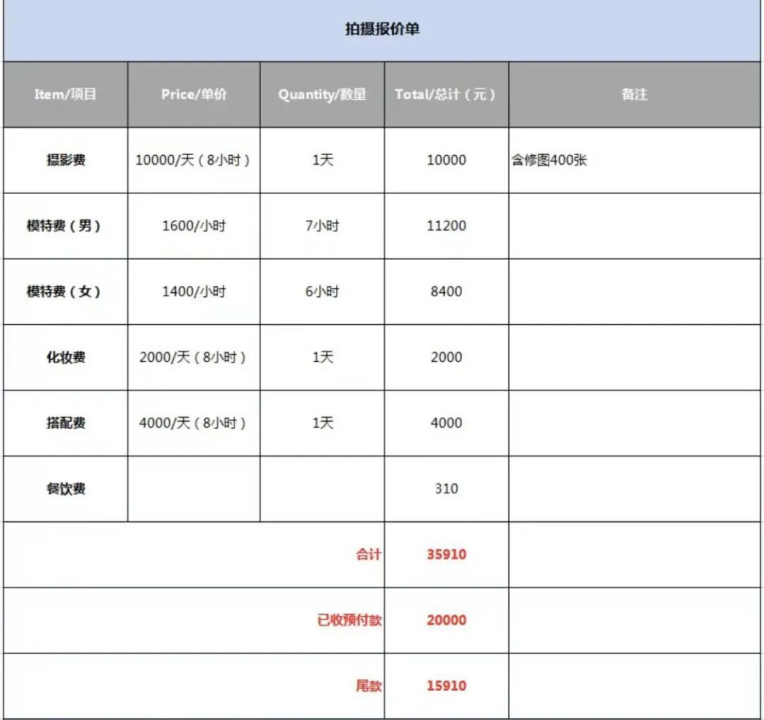
图片:来自网络
“请多个模特的话,得同时照顾几个模特的档期,大量的服装也需要提前熨烫和整理。而且照片数据大,数量也多,下载、制作、挑选的过程至少5天。我们一个服装专场至少10天就要上线,经常得招20个兼职人员才够用。”“浪猪灰头”补充。
而在凌迪科技推出的AI产业模型中,这些人员和费用都可以省略,只需输入关键词,就可以生成“数字模特”。
输入“欧洲女子的脸型,中分长发,典雅气质,妆容干净”,就能生成对应脸型。
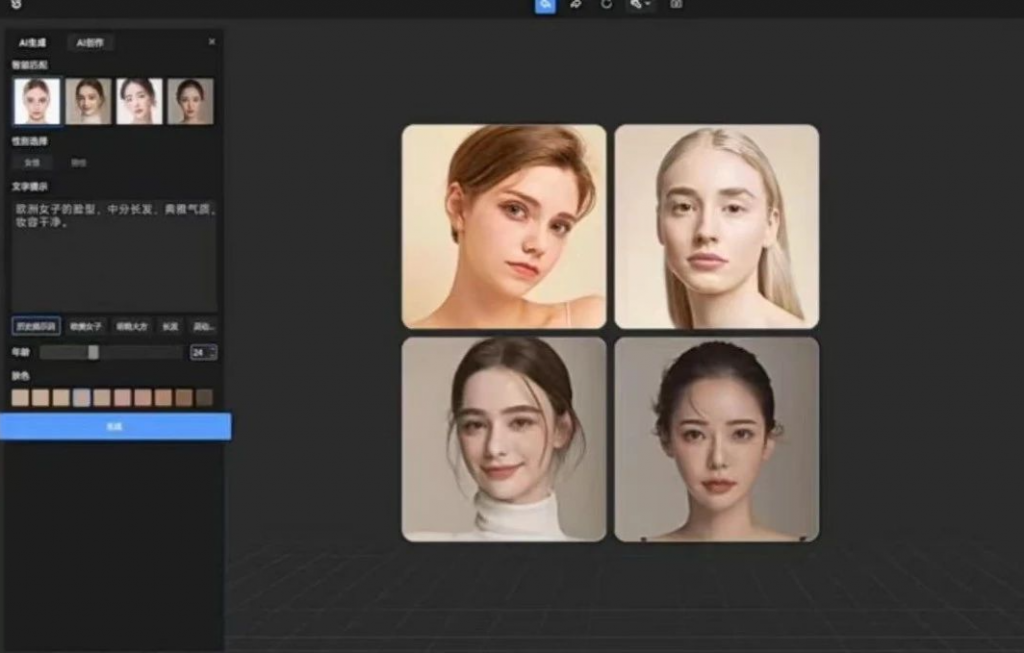
图片来源:凌迪科技Style3D官网
上传一个模特姿势图,就能生成对应姿势的模特图。

图片来源:凌迪科技Style3D官网
输入背景关键词“超现实主义背景,极简主义的建筑风格,画面充满活力,具有梦幻般的建筑空间”,就能得到多张对应风格的背景图。
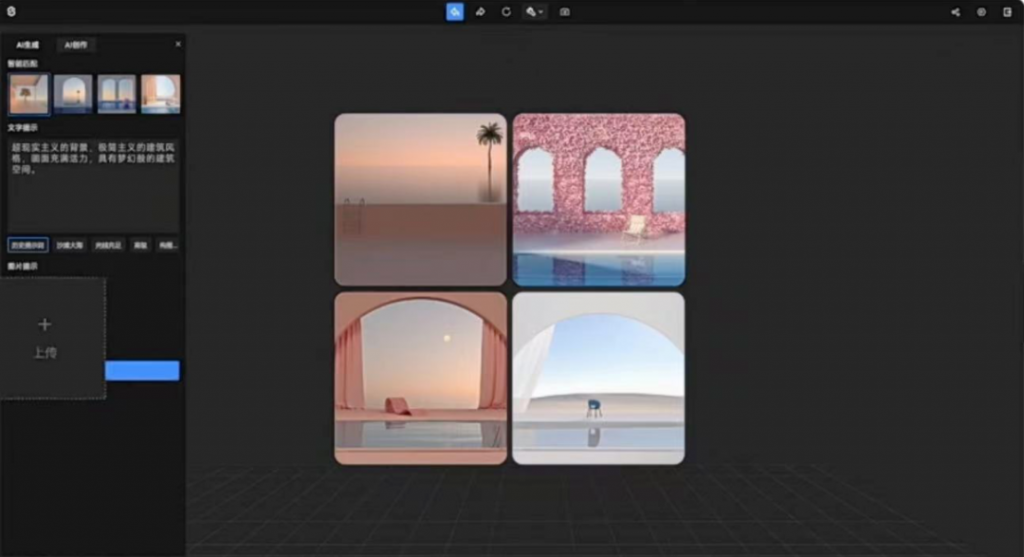
图片来源:凌迪科技Style3D官网
数字人+3D服装的AI组合拳,正在把一个款式的传播成本,拉低到无法想象。未来也许品牌方提供一件衣服的照片就可以组织一场走秀和直播。
“AI+3D技术将改变传统的人货场模式。”王华民认为,“通过文生图,我们可以生成模特、生成背景、生成姿势,具体能省多少还没有衡量。我们主要是工具给到他,至于他们怎么使用,应用在哪些场景,能节约多少钱,就看他们如何使用这个工具。”
02AI技术路径之于服装,有何不一样设计、打版、营销,在这三个环节,已经有“服装设计+AIGC”产品相继面世。
- 万事利丝绸与无界AI合作,探索AIGC +丝巾设计;
- 知衣科技与西湖心辰合作,推出服装产业模型“FASHION DIFFUSION”,要做服装行业的Midjourney,在找款、改款与设计等场景中提升设计效率;
- 供应链服务企业魔鱼发布“魔鱼GPT”,提高服装设计师提高工作效率;
- 凌迪科技Style3D发布的Style3D AI产业模型,提供AI预测趋势、AI生成图案/版片/材质/图像等功能,试图构建起数字时尚产业的“基础设施”。
服装设计在过去也一直被AI赋能,这一轮AI与此前有什么不同?王华民认为,虽然都是AI,但是10年前的AI、5年前的AI和这2年的AI各不相同,“一个人说自己是AI从业者,你得看看他干的是哪一个AI。”
AI行业经历了RNN、GAN、Diffusion等多轮迭代,此前的服装AI都基于GAN,即用生成模型和判别模型相互竞争,生成模型用于创造一个看起来像真图片的图片,判别模型用于判断一张图片是不是真实的图片,两个模型一起对抗训练,最终两个模型的能力越来越强,最终达到稳态。
和GAN相比,Diffusion模型只需要训练生成模型,训练目标函数简单,可以实现更优的图像样本质量和更好的训练稳定性。
王华民指出,“GAN的可控性较差,很多东西停留在学术上或者论文上,Diffusion比GAN更容易训练,同时将可控性整体上了一个台阶,训练效果也有了很大提升。”
基于Diffusion模型的AIGC有两个明显优势:
1 降低设计工具的使用门槛,提高行业渗透率
以往的服装设计工作,需要掌握绘画、PS技能,而在本轮AI产业模型中,通过自然语言描述,就能直接生成设计图。
比如打开知衣科技的FASHION DIFFUSION使用界面,风格、款式、特征一目了然,只需选择款式、颜色、材质等选项,10多秒,AI就能生成T台走秀风格、淘宝抖音商品风格,以及INS小红书社媒风格等各种风格的款式图片。
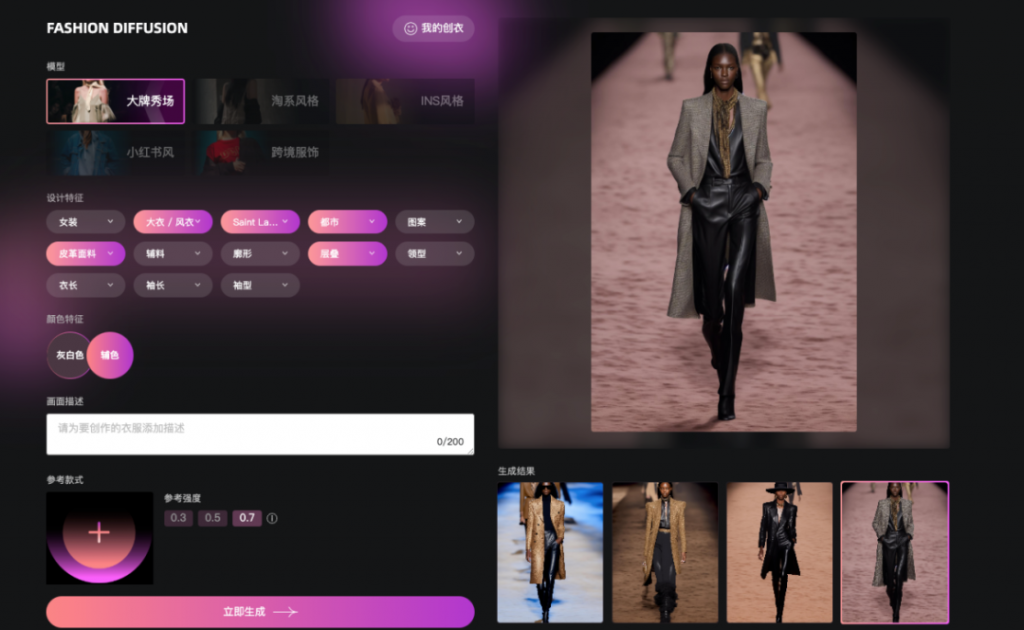
图片来源:知衣科技官网
这样的便利性和“低门槛”背后,是知衣科技超10亿的服饰图片与500+服装设计标签的行业沉淀,以及西湖心辰在深度学习方面的积累。
2 一个模型满足多个任务
传统AI的工作方式是一个任务训练一个算法模型,且各个模型之间彼此独立。比如要做图片搜索,训练一个模型;要做图片生成,再训练一个模型。
而大模型可以一个模型解决多个任务,比如Style3D AI 产业模型提供AI生成图片、AI生成版片、AI生成材质、AI生成图片等多种功能。
服装行业的设计图需要在2D、3D之间反复切换:
- 2D:是设计师最初在纸面上设计的内容,如草图或款式图。
- 2.5D:是版师基于款式图进行制版,是连接二维和三维的桥梁,可以称作2.5D。
- 3D:3D数字服装与数字人(Avatar)结合起来,有了可交互的方式。
- 2D:在服装展示环节,图形学技术通过渲染,把三维物体变成2D视觉效果,例如输出电商上新的图片或视频。
王华民认为,“一个模型可以完成这些模态之间的设计和转化——我想要干什么,我直接告诉他就行了,只需要在出口端设立不同的出口形式,这是理想状态。但也需要2-3年才能完成。”
目前AI生成的设计图,在精度、分辨率、细节、算力成本、制作成本、投产效率比都在测试中,距离商用还有距离。
郑泽宇认为,尽管有海量数据支持,但设计师到底想要什么,提示词怎么来,如何清晰描述出你想要的东西?还是一个问题,还需要通过关注趋势预测或者捕捉灵感去实现。
同时,大模型的可控性始终是隐患。王华民认为,怎么保证它出的图是你想要的,而且可以修改、怎么样去提升可控性稳定性,是AIGC商用的重要一环。“只不过我个人觉得,AI里面的很多问题可能都是因为数据不够导致。”
03AI能否深入服装供应链?“没有一个万亿级的行业能够像服装行业这样来适应AIGC。”Style3D创始人刘郴认为。
尽管这一波人工智能被冠以“第四次工业革命”,但郑泽宇觉得,相比起工业革命,目前AIGC对服装行业的改变还差点意思。
“工业革命发生在生产制造维度上,AIGC更多在设计和时尚维度上,它确实会加速品牌迭代,但想要推动整个产业转型升级,我觉得它还不够。服装的周期长环节多,推动产业转型升级,还得是整个产业的数字化,而不是单一环节的调整。”郑泽宇指出。
“尽管我们希望以后人人都是设计师,消费者在C端通过AIGC设计一件自己喜欢的衣服,然后通过C2M直接生产,但中间还有很多环节没有打通。”王华民认为。
中国服装供应链已经从传统模式走向快反模式。亿邦智库认为,在小单、快反、个性定制等消费新需求驱动下,数字技术重构服装产业生态,倒逼工厂及上下游走向敏捷响应。
不断推广的3D技术、AR制版、虚拟试衣也在不断缩短设计师的时间,提高产业链反应速度。
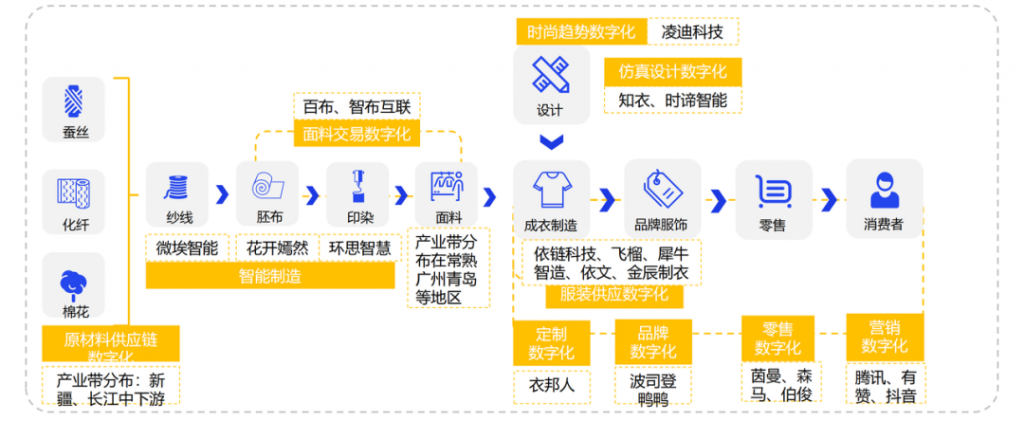
图源:亿邦智库
供应链的数字化似乎超出了AIGC的范畴,但郑泽宇认为,从设计师切入是牵引供应链升级的很好抓手,“设计定了,供应链、工艺、面料这些东西才能定。掌控了设计,就有对后端供应链的引导力。”
如何从设计出发,牵引供应链变革?郑泽宇认为,数据打通和流转仍然是核心问题——服装行业的数据极度分散,掌握在不同参与者手上,几乎不共享也不传递,这是服装行业数字化的瓶颈。对整个产业变革来说,数据打通是更急迫和更瓶颈的那个环节。
阻力是多方面的。“首先,大家不想要被打通的动力要远远大于打通的动力。”有从业者指出,“毕竟,一个工厂也不愿意告诉你产能是多少,如果告诉你,你就不会派超过我产能的订单;面料厂也不愿意把最新款出上传平台,防止抄袭。所以其中有很多的阻力。”
其次,有些环节的工艺始终难以数字化。比如面料环节很多企业没有ERP,更不用提数字化。有服装品牌负责人告诉亿邦动力,“目前设计和生产的快反可以实现,但在面料环节,还是得提前备货,还是传统方式,因为面料涉及物理和化学等过程,还没有太强的快反能力,这个问题短期内也无法解决。”
究其根源,服装行业庞大而分散——这个行业是就业大户,能提供约3亿的就业岗位,但企业分散度极高,品牌存活周期平均不超过一年。“大家都生存在一个高度不确定的环境下,都有很强的危机感。”郑泽宇认为。
在这一背景下,如何实现服装从设计、生产、销售的局部协作与闭环?郑泽宇指出,SheIn做了一个好示范——从订单的维度去打通整个产业链。SheIn可以给工厂提供稳定的订单,工厂可以安心出货;SheIn会把面料提前给到工厂,品牌也可以放心合作。
设计与生产打通的好处也立竿见影,从设计草稿到打版到下大货,如果品牌内部流程快,2~3天可以实现下大货。
目前,知衣科技也在进行这样的数字化协作——从设计师构思开始,设计师选款时看了哪些图,选到哪个款,用了哪个供应商,用了哪些面料,谁来打版,线稿展样板图是什么样子,在哪个展厅,存放了多久,哪些品牌借出,最后谁下了单,下了多少订单,被分发到哪一个工厂,什么时候面料到仓,什么时候开始生产,什么时候出厂,工厂如何交付,这些所有流程都能用数据串联起来。一个设计师的款式,从设计到交付,全流程一两个月内完成。
在这个局部的产业链协同中,前端是数字化设计,中间是数字化款式匹配,后端是数字化供应链平台,“只有在这种协同下,才可以将AIGC的效率优势发挥出来。我们距离人人都可以当设计师的时间,才会越来越近。”郑泽宇认为。
对于AI技术的迅猛发展,您的职业有危机感吗?您认为它真的可以取代设计师,版师,模特……吗?欢迎留言分享。