C-Eval中文大模型权威排名公布!APUS得分名列第四,难题排名全球第一!
C-Eval全球大模型综合性考试评测榜公布,全球排名前四的分别为清华智谱的ChatGLM2、OpenAI的GPT-4、商汤的SenseChat, APUS的AiLMe-100B v1。然而值得关注的是,在难题排行榜中,APUS位列全球榜首!
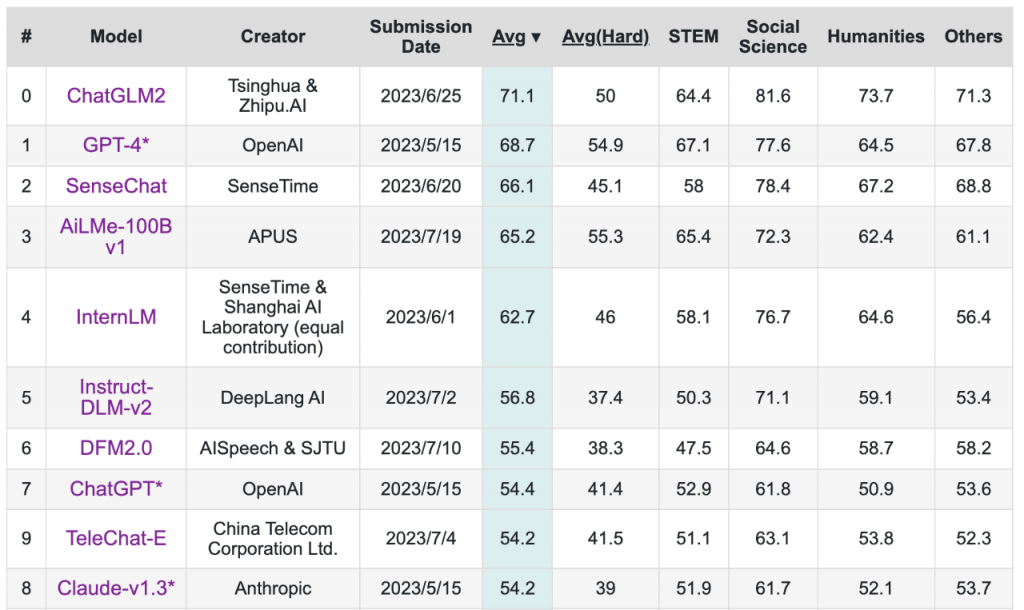
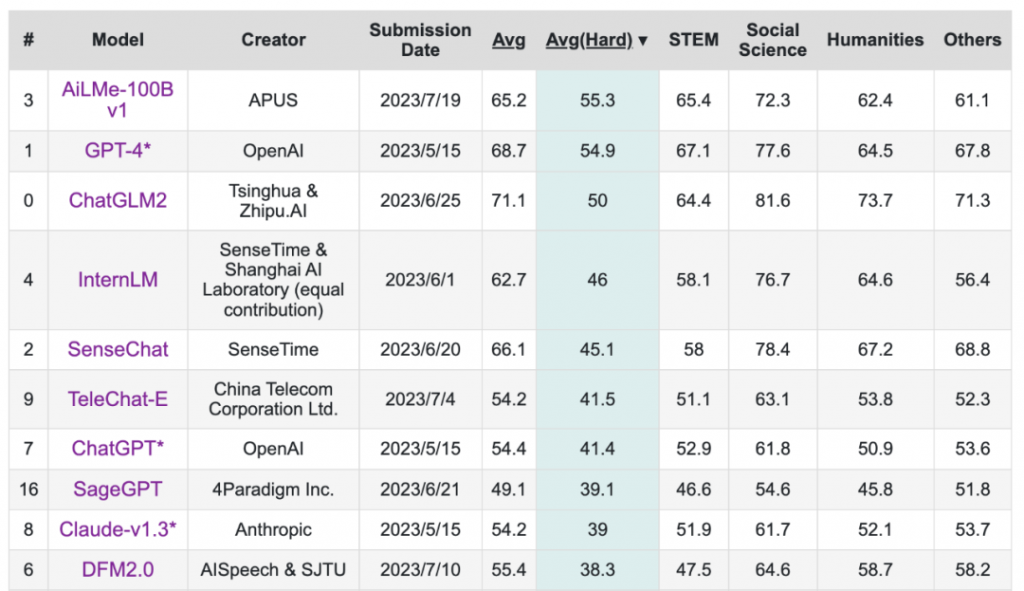
C-Eval是由清华大学、上海交通大学和爱丁堡大学合作构建的面向中文语言模型的综合性考试评测集,包含13948道多项选择题,涵盖52个不同学科和四个难度级别。
想要做大模型训练、AIGC落地应用、使用最新AI工具和学习AI课程的朋友,扫下方二维码加入我们人工智能交流群


