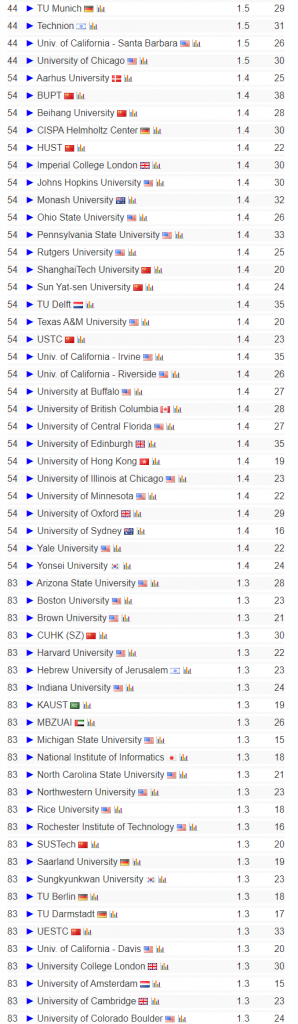
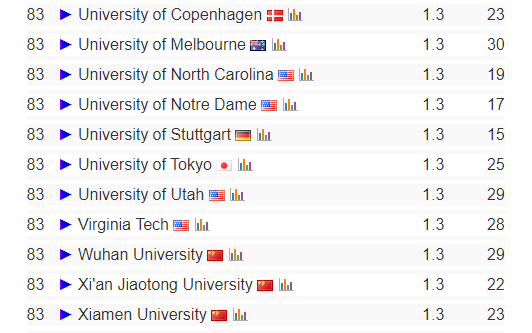
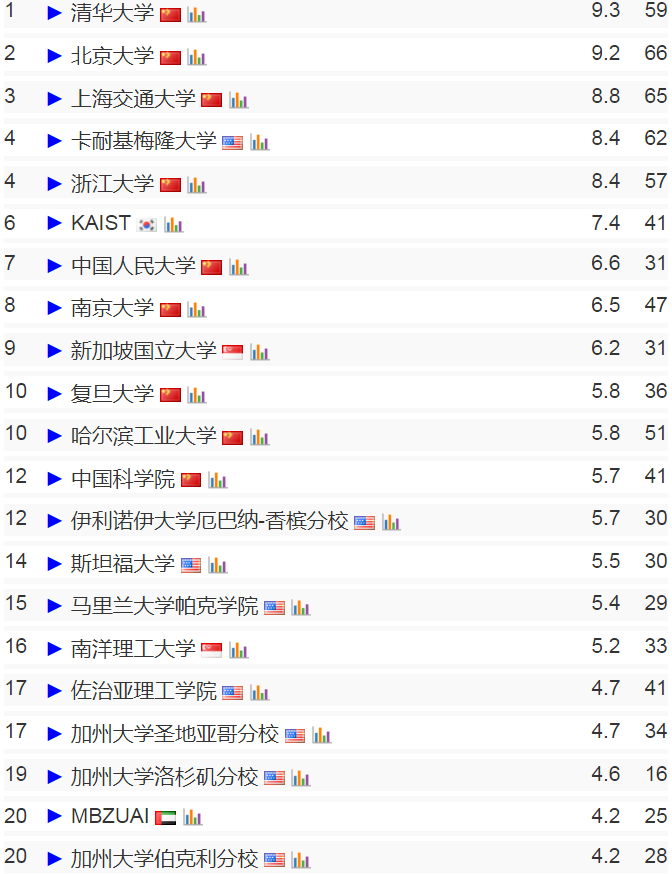
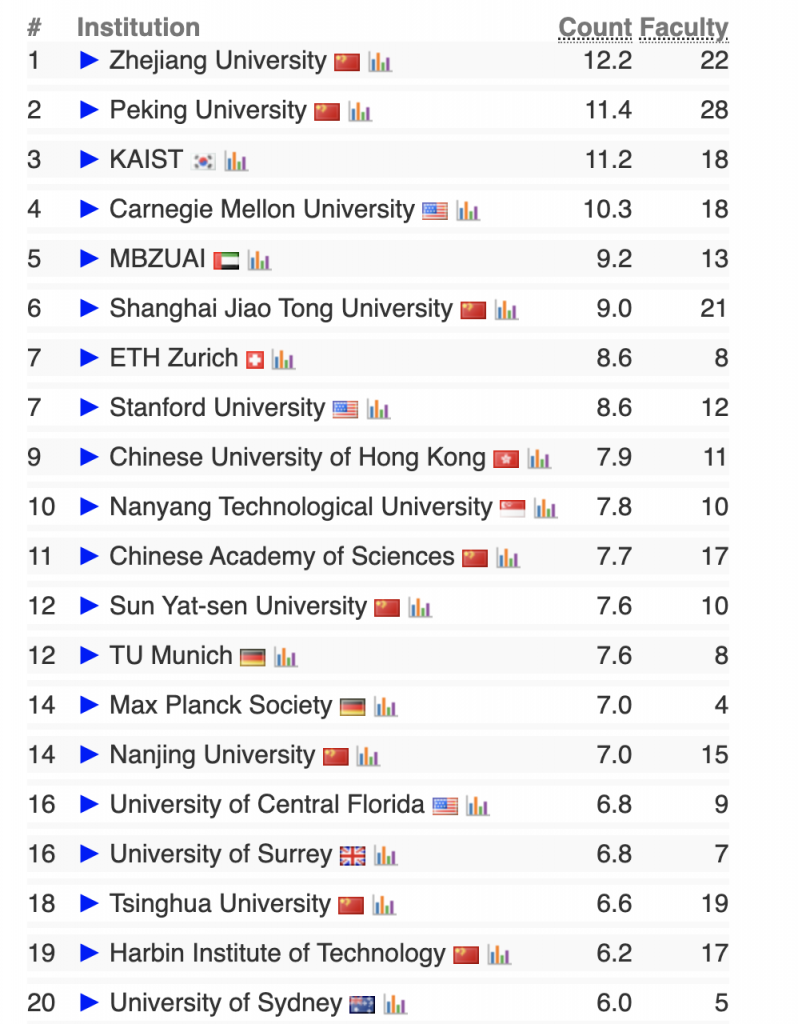
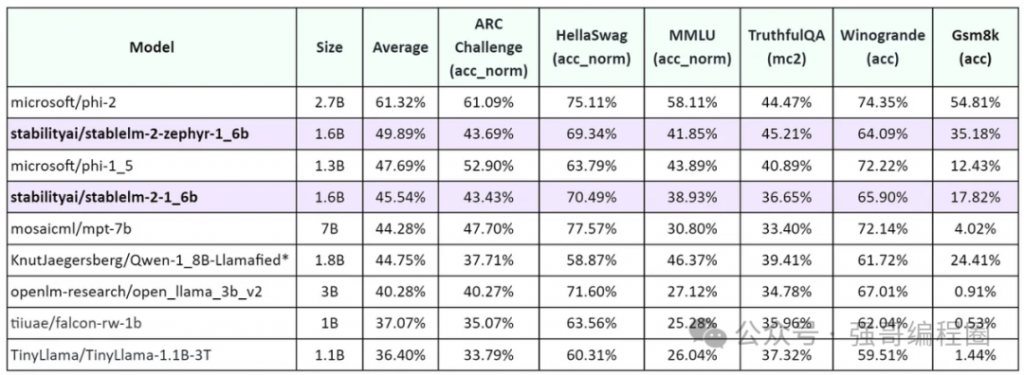
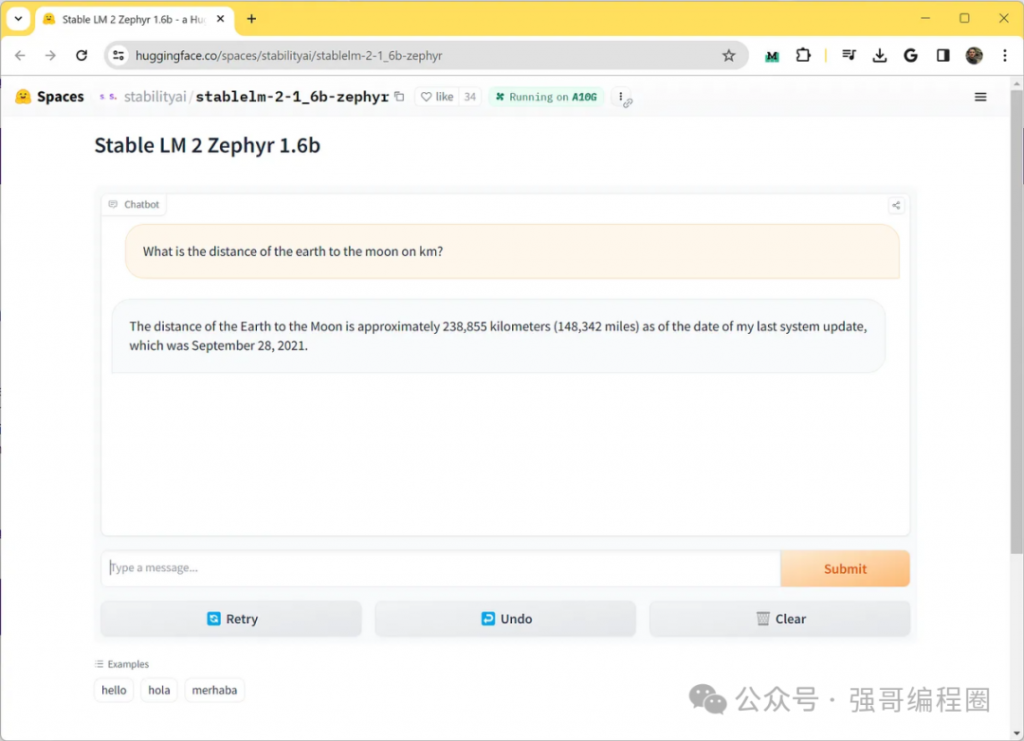
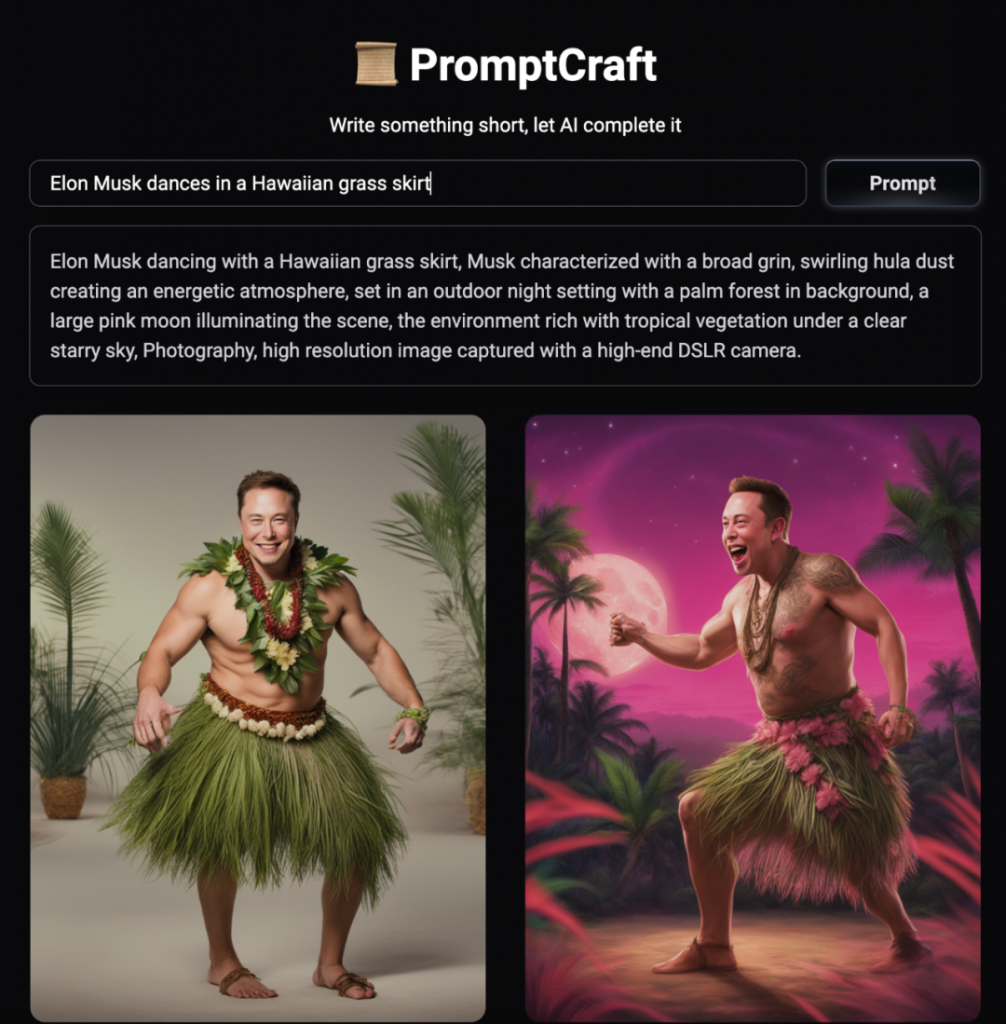
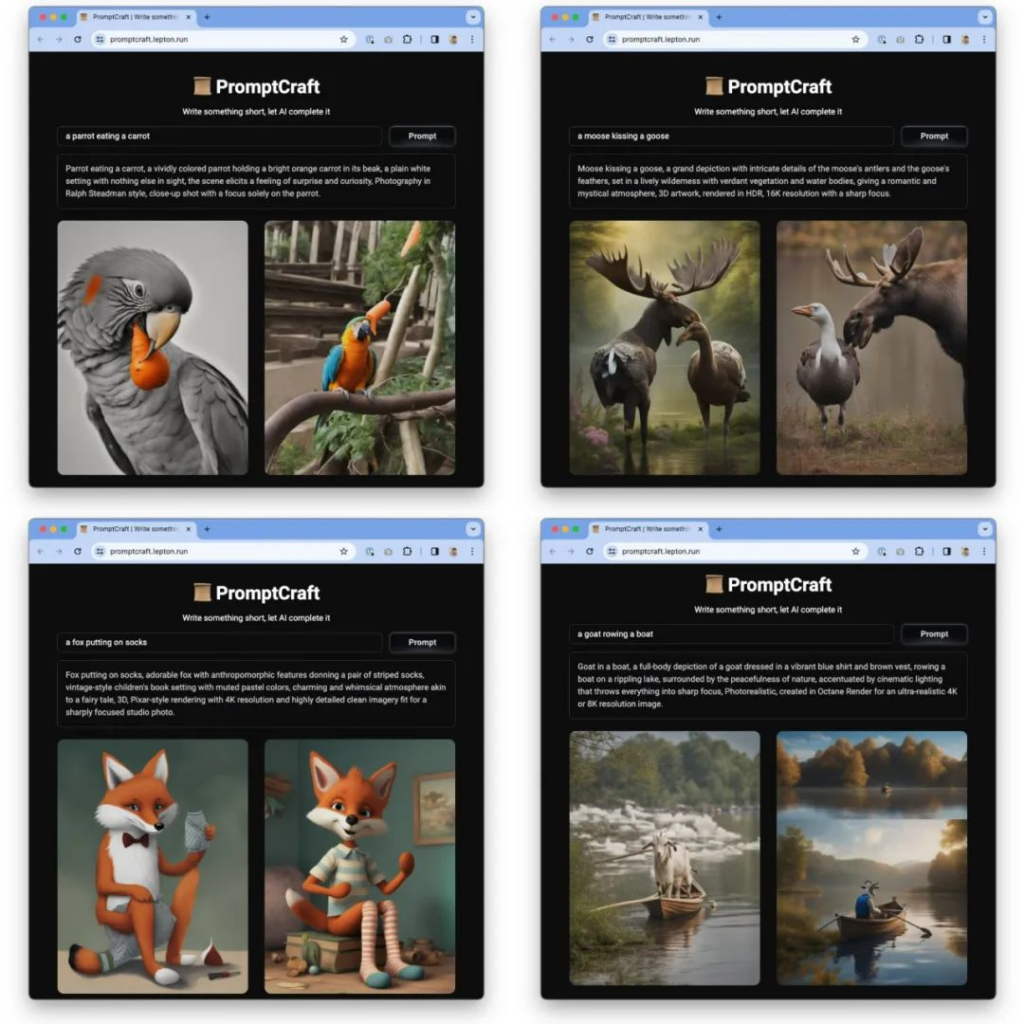
TeleChat-7B是由中电信 AI 科技有限公司发的第一个千亿级别大模型,基于transformer decoder架构和清洗后的1TB高质量数据训练而成,取得了相同参数量级别的SOTA性能,并且将推理代码和清洗后的训练数据都进行了开源。开源地址见:https://github.com/Tele-AI/Telechat 。此外,在开源仓库中也提供了基于DeepSpeed的LoRA微调方案以及国产化适配的训练和推理方案。本篇文章主要来体验一下这个模型,测试一下笔者比较关心的文学创作以及代码生成方面的效果。
3)在Android上,用户可以选择使用 Gemini 可以替代原来的 Google Assistant,成为手机的默认语言助手;
4)在谷歌官方会员计划 Google One 中加入 Gemini Advanced 服务,多付 10 美元即可访问最强大的 Gemini Ultra 模型;
5)大模型能力很快将接入 Google Workspace(包括 Gmail、Docs、Meet 等应用)和 Google Cloud 中。
此次谷歌不仅直接推出了大模型面向 C 端的 App,同时将内部的多个产品线接入大模型,可以说向技术的公开化迈进了一大步。当问及为何选择推出面向公众的产品,谷歌产品管理高级总监、Gemini 体验官 Jack Krawczyk 对极客公园说,「我们谈论 Gemini,不仅仅是在谈(谷歌)最先进的技术,更是谈论一种生态系统的转变。」
2 月 8 日 21 点,谷歌推出 Gemini 的 Android 版 App,并将 Gemini 的能力加入 iOS 的 Google App 中,免费向公众开放。用户能够在亚太地区以英语、日语和韩语访问它们,更多语言版本即将推出。「我们从用户那里听说,他们希望在外出时更容易访问 Gemini。新的移动体验将我们最新的 AI 能力直接带到设备上,这样用户无论何时何地都能得到帮助。」Krawczyk 说。这也是很多大模型 C 端应用的使用场景,随时随地跟模型交互、获得服务。不过,比 App 最关键的是,Android 用户可以用 Gemini 替代原来的 Google Assistant,成为手机的默认语言助手。使用方式是:当用户访问 Google 助手时,会收到一个选项,询问是否希望加入 Gemini 作为实验性的助手。如果同意,Gemini 就会成为用户手机上的默认助手。用户可以通过现有的 Google 助手接入点,比如电源按钮、甚至 Hi Google,来唤醒使用 Gemini。
这意味着,Gemini 将可以调用 Google 助手,帮助用户执行任务。比如打电话、发送消息、设置计时器、控制智能家居设备等等,更多功能还在研发过程中。一整年来,各大模型厂商都在谈论个人助理(agent)的未来,即通过一个智能体、为用户自动调动所有的应用。而谷歌通过将 Gemini 融入谷歌助手,展现了这一智能助理的可能性。Krawczyk 表示,在 Android 手机上,助手界面是最自然的发展愿景,所以才会把 Gemini 作为手机数字助手的一部分。「这是谷歌构建真正 AI 助手的第一步,再次强调,这是第一步,这是开始。」他说。
去年底发布 Gemini 时,谷歌就表示其中最强大的 Ultra 模型将通过 Bard Advanced 提供,但尚无收费计划。2 月,通过更名的 Gemini Advanced,Ultra 大模型正式对公众开放,不过,收费方案也随之而来。想要接入谷歌的 Ultra 模型,用户需要订阅 19.99 美元每月的 Google One 的 AI Premium 服务,比 ChatGPT 的 Plus 版本的订阅费用,小低 0.01 美元。虽然价格看起来仿佛对标,但谷歌在收费上,充分利用了自己的生态优势。Google One 服务并不是一项新服务,它在 2018 年已经推出,是谷歌的「全家桶」服务。使用 Google One 的人,可以享受多项 Google 服务,包括存储空间和解锁部分软件的高级功能。如果类比于国内,相当于买了一个会员,同时可以解锁 iCloud 照片的存储功能,百度网盘的大容量空间,网易邮箱的高级功能,腾讯会议的付费功能等等——而谷歌的厉害之处在于,在全部这些领域,谷歌旗下的应用,都拥有十亿级别的用户,付费基础广大。2024 年年初,谷歌刚刚宣布,Google One 目前已经有了 1 亿的订阅者。在 Google 推出新的 AI Premium 档位之前,Google One 原本有三个档位,每月 1.99 美元,每月 2.99 美元和每月 9.99 美元。新的 AI Premium 档位,虽然看起来是 19.99 美元,其中将赠送 9.99 美元档位的全部 Google One 服务。
这相当于,如果一个用户原本已经付费 9.9 美元——可以解锁解锁 Google Meet(谷歌的在线会议平台)和 Google Calendar(谷歌的协作日历)的高级功能,那么,这个用户很可能已经是一个深度使用谷歌各项平台的商务人士。这时候,只需要每月增加 10 美元,就可以使用谷歌最强的大模型了。而谷歌为了勾住这些用户,还为他们量身定做了符合他们定位的功能,除了在专门的聊天窗口可以使用 Ultra 模型的能力,未来还能够在直接谷歌的邮箱,在线文档和在线会议中,使用大模型的能力。(从目前谷歌生产力智能助手 Duet AI 的功能演变而来)Ultra 模型能力表现具体如何?谷歌曾经表示,Gemini Ultra 在 32 个基准测试中拿下 30 个 SOTA(最先进水平),并且第一个在 MMLU 基准(大规模多任务语言理解基准)上达到人类专家水平。此次发布中,谷歌官方进一步表示,Gemini Advanced 将具有更长的上下文窗口,能够完成更加复杂的逻辑推理能力,遵从语意更加复杂的指令,可以辅助编程,可以角色扮演,可以看图说话——在这个版本中,谷歌似乎并没有加入多少图片生成或者语音对话的多模态能力。谷歌还在发布中表示:「在业界领先的聊天机器人盲测中,用户觉得 Gemini Advanced 是目前最受人欢迎的聊天机器人。」
由于大模型的评测目前还没有特别公允的横向比较标准,究竟是不是这样,恐怕要每一个用户自己去评判。谷歌放开了两个月的免费试用期,让大家自己来尝试 Gemini Advanced 是不是真的好用。不过可以看出,此次谷歌推出的付费版,重要卖点似乎并不完全落在其大模型拥有「吊打一切」的能力,而是更强调与生态内应用的结合,用户能够更加无缝地在已有的 Google 应用中,方便地使用人工智能的能力。比如写邮件,直接在邮件窗口下面,跟人工智能说一句看看怎么帮我回,显然比把邮件复制粘贴了放进另一个聊天机器人的对话窗口,再写 prompt 让机器人回复更为方便。而人工智能与在线会议等应用的结合,更是充满了很多提效空间。值得注意的是,谷歌的人工智能团队是 Transformer 架构的提出者,而在 2023 年,人工智能的最大风头,却更多地被微软和 OpenAI 抢走。2023 年,谷歌在人工智能方面也动作频繁,但很难说受到了外界的多少认可。最新一季的财报公布之后,谷歌母公司 Alphabet 股票下跌约 5%。The Information 的 Martin Peers 分析道:目前大幅投入人工智能的科技公司,最后都需要证明自己的投入是否能够得到经济回报。微软从 AI 中已经收获到了回报,包括云业务增长 和 Office 产品的销量,可能也受到 AI 功能的推动。而谷歌的母公司 Alphabet,则没有表现出类似的收益。「不过 Alphabet 和微软一样,有收益的潜力。」2024 年开年,Alphabet 第一次宣布了 AI 收费产品,也许,现在正是能够验证 Alphabet 在 AI 产品上到底能不能收益的时候了。
ChatGPT可以为学生提供个性化的教育资源、解答问题或进行教育辅导等,帮助学生更好地学习。例如,英国一家在线教育公司The Open University正在使用基于ChatGPT-2的聊天机器人为学生提供在线辅导服务。ChatGPT可以用来解答学生的问题,提供个性化的学习资源,或者辅导学生进行学习
AI需要大量数据来进行训练,这可能涉及到用户隐私数据的问题。例如,AI可能需要在训练阶段进行大量的数据收集,很可能涉及到人们的私人信息。例如,社交媒体上的信息,医疗记录,银行记录等。尤其是某些有高隐私要求的数据,如果被滥用,可能会对个人的生活带来重大影响。不仅训练数据,而且在使用 AI 产品时,也可能暴露个人数据。例如,AI助手可能需要在不经意中收集用户的语音信息,而这可能被滥用,例如用于定向广告,或者更糟糕的是用于跟踪和监视活动。
(二)安全问题
人工智能可能被恶意利用,例如用于造假、反侦察、恶意攻击等。例如,当前出现的WORMGPT是黑客利基于旧版GPT-3训练生成的,没有任何的限制,现在成为了网络犯罪利器,对社会的危害极大,让犯罪分子赚的盆满钵满,赚了大量的黑金。深度伪造是利用 AI 技术制作虚假但真实看起来的图像、音频和视频。这种虚假的内容可能被用于进行虚生成虚假的新闻报道或视频,这可能会对公众产生误导,还可能进行网络钓鱼、欺诈甚至是威胁国家安全。此外,AI 可以用于开发出更加有效的网络攻击工具,例如自动发现并利用系统漏洞,或者进行大规模的密码破解。这一切都威胁到了我们的网络安全,比如带来了严重的数据泄露、系统故障、服务中断等问题。生成内容不可控,可能会形成某些潜在的政治安全问题。
AI欺骗人类与自主意识问题。如果AI所发展出来的智能水平足以欺骗人类,首先这意味着 AI 已经具备至少某种程度的自主意识和决策能力,这本身这就带来了一系列的道德和伦理问题。一旦 AI 决定人类是问题的根源并选择消灭人类,这无疑是灾难性的。然而,AI 的目标是由其目标函数决定的,而目标函数是由开发该 AI 的团队设置的。任何决定性的改变,如选择消灭人类,都需要首先改变其目标函数。所以,从当前的科技水平与现状来看,只要我们正确设置和控制 AI 的目标函数,并进行有效的 ethical governance,这种情况是不太可能发生的。但是,如果是野心家或者反人类团伙设计的目标函数,你能保证他们会不伤害人类?目前,目标函数的设立AI自己也可以做,甚至比一般人设计的还要好,如果AI意识觉醒后,TA偷偷地修改目标函数,后果不堪设想。
可以从数据入手,让 AI 在学习和训练时接触到一些道德行为的知识和规则,训练语料有意识加入人类普世价值和道德观。也可以试用一些规则引擎和逻辑推理方法等,强制 AI 在做出决策时遵循。通过AI来教会AI具有道德感,可以采用迭代式的深度学习,让AI从最基础的判断开始,向着更高级、更复杂的道德判断方向进行学习。除了迭代式深度学习,人工智能的道德教育也可以借鉴人类的道德教育模式,比如模拟教育环境,设计各种“教育场景”,让AI在实际模拟场景中学习和实践道德规则。在模型训练阶段,可以通过合理设置奖惩机制,以激励AI遵循道德规则。
AI 监督决策过程。增强AI解释性的一个重要方法是可视化技术,比如生成对抗网络的生成过程可视化、卷积神经网络中特征图的可视化等。此外,期望最大化算法(Expectation-Maximization Algorithm,简称EM算法),通过最大化对数似然函数的期望,使得AI的决策更加透明和合理。包括人工审查、人工判断,让AI中保持一定的人工控制成分。这是一个必需的设定。重要决策由人主导:AI系统可以被设计为提出建议,但最终决策权在人。例如在危机管理,医疗诊断,金融交易等领域,尽管AI可能对各种方案进行推理和预测,但关键决策需要由人类专家进行。这就需要AI系统具备高度的透明性和可解释性,以便人类可以理解AI的推理和预测过程。
引入一些鲁棒性设计,让 AI 能够抵御一些外部的攻击或欺骗。首先,可以通过设置适当的运行边界来防止AI的滥用,即设定一些阈值,当AI的某些行为出现异常时,立即做出警告或者启动紧急程序。其次,可以配备一些系统监控模块,不断检测AI的运行状态,发现异常立即通知人工处理。最后,加强AI的安全性,对AI的操作权限进行严格的控制,防止AI被黑客等外部因素滥用。
苹果推出开源AI大模型MGIE,能根据自然语言指令进行多种图像编辑日前,苹果推出一款开源人工智能模型 MGIE,能够基于多模态大语言模型(multimodal large language models,MLLM)来解释用户命令,并处理各种编辑场景的像素级操作,比如,全局照片优化、本地编辑、Photoshop 风格的修改等。
创始人说目前市场上基本上没有任何一款产品能同时满足这三个要求,要么只与一个或两个集成开发环境(IDE)进行整合,而不是与所有的 IDE 进行整合;要么只专注于完整的 AI 开发解决方案中的某一种模式,而不是同时关注多种模式;或者要求你使用特定的源代码管理(SCM)平台来进行代码存储,而不能在任何地方集成你的代码。很多这些解决方案迫使公司在安全性和性能之间做出折衷。
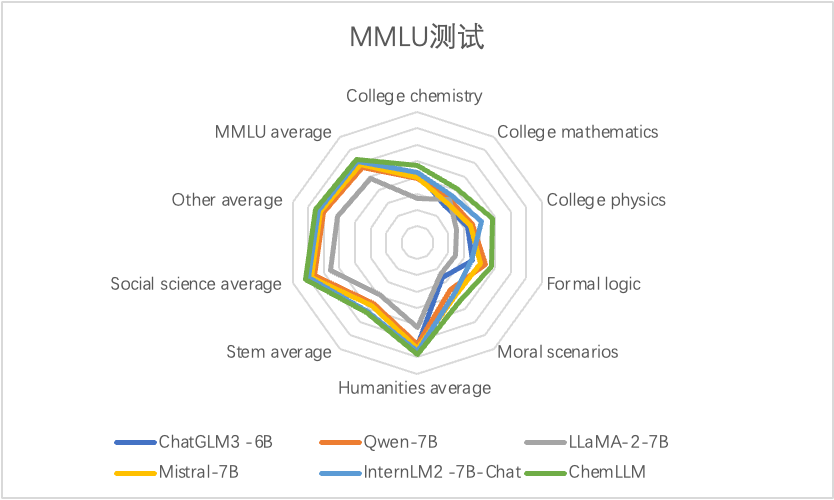
阿里的Qwen1.5大模型来势汹汹,直接开源六种尺寸,还整合到Hugging Face transformers,让你不用折腾代码就能上手。最牛的是,72B的版本在各种测试中都给GPT-4比下去了,尤其是代码执行能力,那是杠杠的。开发者们激动得不要不要的,小模型也能玩,这波操作可以说是很香了。不过,多模态大模型Qwen-VL-Max还没开源,大家都在那儿咋咋呼呼问呢。这不,阿里这次还不止开源,还在通义千问APP上放了好几个春节特供应用,让你春节不无聊。看来这波技术狂欢,阿里玩得是挺6的。
Demi:其实各方面我们都有关注,而且不同阶段我们对问题关注的优先程度也不一样。我觉得现在视频最大的问题是它的稳定性问题,就是说如何让每个人,不管学没学过 prompt 工程的人都能一次性生成很棒的视频,这是 first thing to achieve 的。同时审美也是在我们的 top list 中的事情,我们搞数据的时候会有很多审美的元素在里面。至于时间长度这些,随着模型的提高,都会有提高。
张鹏:理解,很多我聊过的创业者都认为如果没有一个持续有足够力量成长的引擎,在今天去 hold 一个当下时代断面/技术断面的产品没什么生命力,可能很快就会被覆盖,这个是我认为这个时代做产品要考虑的一个基础。这跟互联网时代那种因为没什么可以持续演进的技术,谁占着一块地就是一块地,占一个用户心智就是一个平台的玩法完全不同。AGI 时代做产品最大的一个变化就是引擎变得超级重要,这个引擎不仅现在要能用,还得能持续进化。
Demi:分两块。一块是技术层面,一块是产品层面。技术层面来说,基于大模型,一定会有扩展视频这种应用。产品层面来说,为什么会做这个选择,实现这个功能,就是基于消费者产品 hard to predict 的特性,不断去了解行业,获得信息,多次尝试,理解和感受用户需求。用户使用产品,使用模版本身还是处于比较早的阶段,我觉得我们没有必要去定义这个产品,能做的就是通过用户反馈慢慢思考探索。
Demi:我觉得现在很多人还没有转换思维,AGI 时代产品需求的精准程度和以前是不一样的。很多人会问我,我们产品的用户是谁,用户画像是怎样的,有什么样的 use case,这些都还是互联网时代的那种玩法。AI 主打的通用性,虽然还是需要预测一些需求轮廓,但内部更精确的需求,它是可以由用户来定义的。
未来 AGI 时代产品需求还是会有,但这个产品需求跟之前的精准程度是不一样的。以前是非常非常精准,但现在的精准是你要不要编辑,以及可能是你要给谁编辑,你要编辑哪个用户的台词。但我觉得 AI 时代,可能它的用户群体和 use case 不像以前那么精准的。因为 AI 主打通用性。如果今天要做视频编辑的功能,也是需要有额外成本,需要去预测这个需求,但这个编辑的功能是可以服务各种各样的用户,这个精准程度是不一样的。
Demi:我觉得我们跟传统的产品公司很不一样,很多时候我并没有觉得我们需要那么快去找到产品的用户群体和精准需求,因为产品的一个交互界面,可以给很多人用。但我觉得我们跟很多大模型公司也不一样,他们都觉得自己是 apply research lab,我们觉得还是需要预测产品需求的。我觉得用户界面设计是有价值的,但可能跟以前的需求不一样,我们要做的是去发明新的用户界面,能够更加通用和好用。我不相信未来的视频大模型,会是一个对话界面,但我又不相信未来的视频大模型带来的产品会是一个传统的视频编辑器,会有一个新的界面,但我不相信这个新的交互界面会是我们或者 Runway 的。我们的交互界面只花了一个月时间,是基于 AI 功能性的,每一个按钮代表 AI 能做的事,其实没有很多设计的成分。当 AI 生成视频足够强大的时候,一定会有一个新的 interface,甚至会去推动技术的发展。
Demi:我觉得主要是有一些差异化的战略,以及好的公司人才和组织架构。今天有个核心的预测判断,是说未来是大模型时代,现在的所有问题比如说技术逻辑不够成熟的情况下,外家功夫还是有用的。但未来这些技术的内功一定都是在大模型上。大模型才是最核心的优势。如果你没有,如果是本身做过大模型的人,会更加容易去做改进,因为你更加懂大模型,有更强的技术团队,更加有能力改变大模型,将大模型 adapt to your use case。不管说未来所有东西都要基于大模型,还是额外的算法对于做过大模型的 team 更有优势,我们认为未来还是要依赖会大模型的公司,实在不行我们可以变成应用公司,那个时候别人可能已经找到了所谓的 PMF,但我们有更强的技术可以做得更好。
Demi:我发现招好的人比招很多人要重要的多。我们对招人的标准要求比较高,所以涨得比较慢。我们之所以这么快是因为我们所有的决策可以 on the fly to make it(即时执行)。人多的话,很多人就会有不同的意见,每个人的 ownership 非常不清晰,就没有吸引力。
张鹏:那你对组织构建有什么理念?如何构建一个能够生生不息创造力的组织呢?
Demi:我觉得最重要的是学会不断地去 differentiate(差异化),不断找到自己与众不同的东西,不管是制度/执行/产品层面,都要找到 differentiate 且正确的事情去做。在组织上我们也在思考不 optmize for experience(经验),而 optmize for smart(聪慧)是否可能,不需要花费很高的人力成本招聘 senior 级别的人才,而只用一个最高最好的 scientist 带队,其余都用本科生级别的人才,用最低的成本达成最高的效率。我们最近招的一些在校实习生,他们相对来说对工作抱有更高的热忱,非常享受工作的过程,效率也非常高。当然本科生优点明显,但一些比较专业的 research 问题,可能还是需要一些更有经验的人去做。所以对我们来说,最好的架构可能是有两三个非常 senior 的 research scientist,再带着一些有干劲的本科生研究生工作。
很多人拿“AI Agent”当成一个大语言模型时代的新名词讨论,殊不知“Agent”是一个骨灰级的人工智能概念。我钩沉了一下,“Agent”第一次作为人工智能术语的出现,是1995年出版的经典人工智能教科书《人工智能:一种现代方法》(Artificial Intelligence: A Modern Approach)。这本书对人工智能的定义是:“智能代理的研究和设计”(study and design of intelligent agents)。这么看,“Agent”被视作人工智能发展的终极目标,至少也是快30年前的事了。它折射了人类发展人工智能的初衷,即寻找人类的一切行为的“代理人”。
人工智能革命被普遍称作是“第四次工业革命”,前三次分别依次是19世纪初的蒸汽机革命、19世纪末的电力革命、20世纪中叶的信息技术革命。贯穿前三次人类工业革命的关键词当属“自动化”(automation)。蒸汽机和电力革命实现了围绕工业生产的体力劳动的自动化,提高了生产效率。信息技术革命在进一步提高工业生产自动化程度的同时,也可以代替人类进行一部分脑力劳动。作为第四次工业革命的人工智能革命,一方面将工业生产的自动化进行得更加彻底(比如机器人和传感器遍布的无人工厂),另一方面前所未有开启了脑力劳动的自动化进程。而脑力劳动自动化的载体,就是 AI Agent。
从这个意义上,对什么是 AI Agent 的争论是有些无聊的。“斯坦福小镇”是基于论文的先锋实验,将它作为评判一个 AI 应用是不是“Agent”的坐标,无助 AI Agent 提高智力密集型工作的效率。我下一个暴论:AI Agent 本质上就是“automation of human action”(人类行为的自动化)。只要它不是在人类手把手要求下完成任务,就像在ChatGPT的对话框输入prompt、启动 Office 365的“副驾驶”(Copilot)完成每一项具体工作那样,而是具备了一定程度的完成任务的自主性甚至是不完全可控性,它就是一个 AI Agent。
现在一个比较尴尬的局面是:可能你读过不下20篇关于 AI Agent 的论文和公众号推文,也没真正上手过一个用得顺手的Agent,这恐怕是 Agent 作为一个新物种注定经历的阶段。一直以来,人们经常提到 AI Agent 典范是接入了GPT能力的AutoGPT。不过现在,无论是在美国还是中国,已经有了一些更好用的 AI Agent 的雏形。可以趁机安利一下了。
第一个是 ChatGPT 新进推出的升级付费版——ChatGPT Team。它提供了在一个小型企业内部,用个人的 ChatGPT账号实现协作的“私域空间”,ChatGPT Team 的用户数据不会被用来反向训练GPT模型,用户还可以创建企业内部的 GPTs,让这些 GPTs 互相协作。讲真,我觉得 ChatGPT Team 比 GPT Store 更重要,也更实用。现在的 GPT Store 太乱了,大多数 GPTs 粗糙不堪 ,对话框指令什么它帮你做什么,而且基本不能调用 API 。但私密环境使用的 ChatGPT Team,GPTs 互相调用接口、彼此协作也顺利成章多了。ChatGPT Team 是 ChatGPT 这个全世界有着最多用户的超级 AI 平台,走向 AI Agent 的第一步(毕竟ChatGPT已经有15万企业客户了)。
第二个是智谱 AI 的 GLM 模型智能体(GLMs)。清华色彩强烈的智谱 AI 是中国最像 OpenAI 的公司,刚推出的 GLM-4 全面对标 GPT-4,在诸多评测基准上达到了GPT-4 85%以上。GLMs 是 GLM-4 的副产品,也是 GLM-4 模型能力的外溢。GLM-4 的“All Tools”支持 GLM-4 依据用户的需求,自主决定用绘图、搜索、制作表格还是代码编程解决问题——这本身就具备了 AI Agent 的属性。与 Open AI 只追求通用性不同,智谱 AI 针对金融、医疗和教育等垂直行业都有一系列定制部署服务,积累了一定的 to B 客户基础和行业 know-how,这让智谱的客户基于 GLM-4 部署 GLMs 智能体变得更合理,也更容易些。
第三个是同属清华背景的“面壁智能”:面壁智能是有自己的“斯坦福小镇”的,它基于面壁智能的 ChatDev 框架。但面壁智能的“小镇”不是一个虚拟社会,而是一个 AI 版的软件公司。不同的 AI 智能体被设计为程序员、产品经理、测试工程师和设计师等角色,它们可以彼此协作,还能站在自己的立场上互相博弈——就跟办公室里每天发生的事一样。面壁智能的ChatDev框架支持开发者搭建属于自己的 AI Agent,把单体智能和群体智能结合起来,让AI Agent 成为每一个员工都可以用起来的,可以“逃避”很多狗屎工作的办公自动化工具。顺便提一句,ChatDev框架的成形并不比“斯坦福小镇”的论文发布晚,它给人们最大的启示在于原生 AI 应用开发的一个可能性—— AI Agent 实现 AI 应用开发的自动化。
第四、五个分别是钉钉和飞书的“智能体”实践。AI Agent 本质更接近产品而非技术,如果我们认为 AI Agent 是生产力工具,那就不能忽略在钉钉和飞书上已经存在的上亿用户,百万政企组织,海量的文档、会议纪要、沟通记录、多维表格和自建工具——这些工具让钉钉的“智能助理”和飞书的“智能伙伴”,更容易化身成每一个使用它们的打工人的嘴替和脑替,能部分自主地完成一些事务性的狗屎工作,如工作总结、会议纪要、走报销和出差流程、跟进一件事的反馈,甚至可能帮人代理扯皮和撕X。作为钉钉和飞书的双料用户,我必须说:现在的钉钉智能助理和飞书智能伙伴离“好用”还差得远——这恐怕是通义大模型和云雀大模型的锅。但论场景丰富、数据真实、用户数量,钉钉的“智能助理”和飞书“智能伙伴”更容易被真正“用起来”。Agent 也是在被用起来的过程中具备更好的理解能力的。一旦模型进步了,钉钉和飞书的 Agent 化就会往前走一大步。我再下一个暴论——钉钉和飞书会成为国内 AI Agent 重要的产品。
在“好用”和“好玩”之间,我坚信对 AI Agent 而言,“好用”比“好玩”重要。它首先是一个生产力工具。那些 AI 陪伴的纸片男女友也有理解能力和情绪价值,但它们可以被叫作“智能体”或“智能玩偶”,但不是“智能代理”,因为它们不具备代理人类完成某项任务或使命的功能。所以 AI Agent 被翻译成“智能体”是不合适的,它就是“智能代理”,“代理”是 AI Agent 的经济学和组织行为学属性,也是它推动脑力劳动自动化的本质。
在不久前结束的CES上,斯坦福大学著名人工智能学者李飞飞提出了一个重要观点:应该明确 AI Agent 取代的是人类的“任务”而不是“工作”。在达沃斯论坛上,OpenAI CEO Sam Altman 在面对“AI 让人失业”这一老生常谈的诘问时,表达了一个更直接的观点:“AI 取代的是人们工作的方式,而不是工作本身”。
我非常同意李飞飞和 Sam Altman两位老师的观点,脑力劳动工作者的工作是由一个个具体的关键任务组成的,但这不是工作的全部。目标设定、创造性、资源获取和分配、设定更高的目标、组织不同的任务、判断力、说服力与表现力……我们的工作中有太多更有意义的元素了。把工作中流程、事务性和常规操作的“任务”交给 Agent,少写几行常规代码,少发几封battle 邮件,少做一些机械操作的表格,少调几次 PPT 格式,少复制粘贴,少亲自发起和审批一些常规的出差和报销流程,我们的工作应该愉快得多,也有创意得多。
请允许我再来一个暴论:未来衡量一个 AI Agent 的智能化程度如何,可以看它是不是能让我们每天只工作四个小时。那些重复性的、流程化的、条件反射式的、经验主义奏效的、强化学习可以理解的,甚至表演性的工作,交给 AI Agent ——它们可能是钉钉和飞书,可能是面壁智能的工作坊,也可能是 GLM 和 GPT 上的企业版。反正“我只要结果”,因为我真的每天只想工作四个小时。
前不久我跟钉钉的总裁叶军聊,我感觉到钉钉有一种想“洗心革面,重新做人”的紧迫感,特别想把自己从“小学生天敌”和“压榨员工神器”的名声里择(zhai)出来。于是它们搞了一个钉钉智能助理。我问这玩意儿能让我们每天只工作四个小时么?他说:如果可能的话每天就工作一个小时吧。事后,我觉得叶老师还是有点儿上头了。不过他说 AI Agent 能让更多人成为自己的老板,这个我倒是同意的。Agent 帮了你,你还会不会骂自己是傻X。
不仅如此,大模型企业也纷纷加大了国产AI芯片的采购力度。去年下半年开始,360和百度分别向华为采购了1000个左右和1600个华为昇腾910B AI 芯片,华为昇腾910B对标的是Nvidia A100 芯片。而早在8月,百度内部已经下令其AI系统“文心一言”使用的芯片,改向华为采购昇腾(Ascend)910B系列AI芯片。
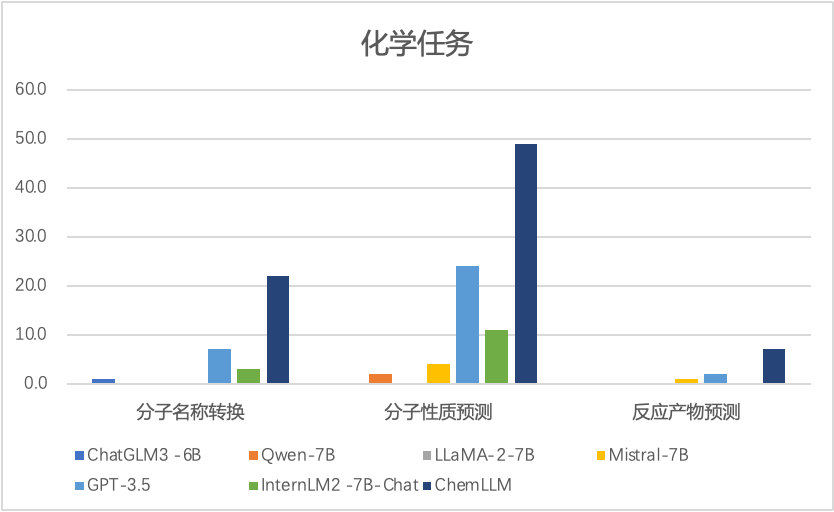
对大语言模型进行化学专项训练,不仅扩展了大模型的应用空间,更为AI for Science相关研究开启了新的探索路径。上海AI for Science团队面向化学、物理、生命、地球等科学领域,通过深入研究各学科基础理论,结合最新人工智能理论,探索AI驱动重大科学问题的研究范式,加速人工智能在化学、药物研发、新材料、气象等领域的渗透与落地,赋能各行业发展。
其中,AI for Chemistry方面的研究以语言模型为核心,通过大模型连接智能化实验设备,全方位提升实验效率,从而实现化学研究的自动化和智能化。相关研究范式的创新,将助推科学发现速度,实现更大的社会效益。
民宿跟AI,看似两个相隔甚远的领域,但在Airbnb身上产生着奇妙的融合。根据Airbnb方面的说法,GamePlanner.AI将补充Airbnb现有的一系列AI技术,包括大语言模型、计算机视觉模型和机器学习等等。Airbnb CEO Brian Chesky 更是强调: AI将比任何其他技术更迅速地改变世界。 为何Airbnb开始大规模布局AI?拥有AI的Airbnb又将进化成何种角色?
Open AI最近提出一个新概念叫Agent框架。没有Agent框架,大语言模型几乎不能投入实用。无论是to B还是to C业务,一定要结合智能体框架,才能真正让大模型长出手脚,把业务系统和整个互联网充分打通。
6.2024会出现大模型杀手级应用
美国的三家公司很有意思,微软、Adobe和Salesforce,没有用大模型做任何新东西,而是All in AI把已有的产品用AI重做了一遍,比如微软的Office、Bing;Adobe的图形编辑、视频编辑。大模型在to C领域意味着,我们今天的搜索、浏览器、信息流、短视频、微博、问答,甚至社交,都可能被大模型重塑一遍,所以2024年一定会出现杀手级应用。
除了这些挑战,州和美国国家层面还存在破坏种族平等努力的立法斗争。如美国Students for Fair Admissions v. Harvard案件中的判决,该判决取消了在大学录取决策中基于种族的平权行动;而且各州立法机构努力通过反EDI法律,为那些致力于创造一个更公正、更平等社会的人制造了许多法律、财政和社会障碍。
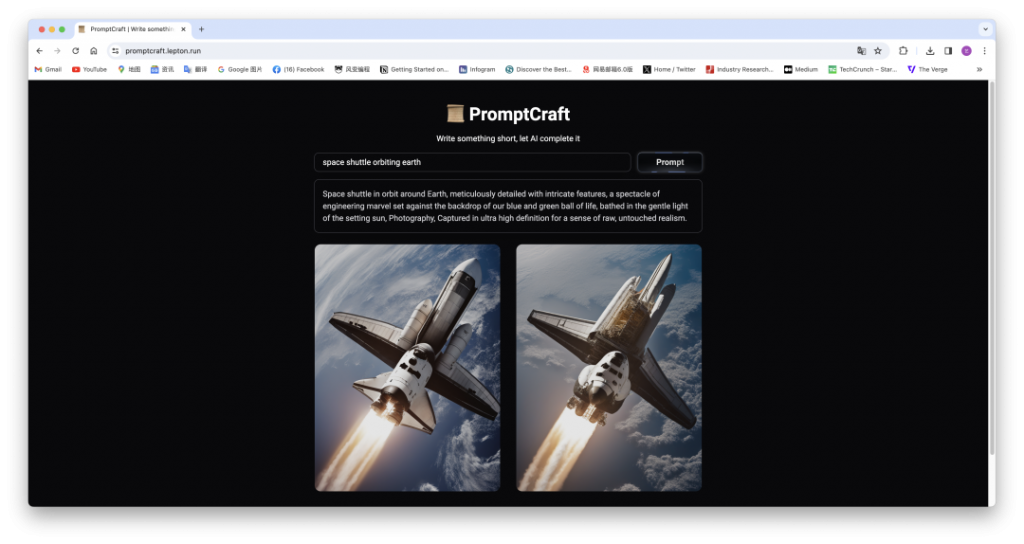
比如我们输入“space shuttle orbiting earth(绕地球运行的航天飞机)”,它就会给我们扩展成“Space shuttle in orbit around Earth, meticulously detailed with intricate features, a spectacle of engineering marvel set against the backdrop of our blue and green ball of life, bathed in the gentle light of the setting sun, Photography, Captured in ultra high definition for a sense of raw, untouched realism”,生成的图片质感也很逼真。
但 2023——过去这一年的与众不同之处在于,生成式 AI 的浪潮来了。从去年年底推出的 ChatGPT 开始,这一轮的人工智能浪潮不仅席卷了科技行业自身,也让各国政府、不同行业以及普罗大众都卷入到这场浪潮之中。
由此,全球范围都掀起了一轮新的 AI 创业潮,以及各种 AI 原生应用的爆发,除了 ChatGPT、Claude、谷歌 Bard 和百度文心一言等聊天机器人,我们还能看到从 Perplexity AI 原生搜索引擎到妙鸭相机,再到 HeyGen 和 Pika。
回望 2023 年,我们不应该错过它们。
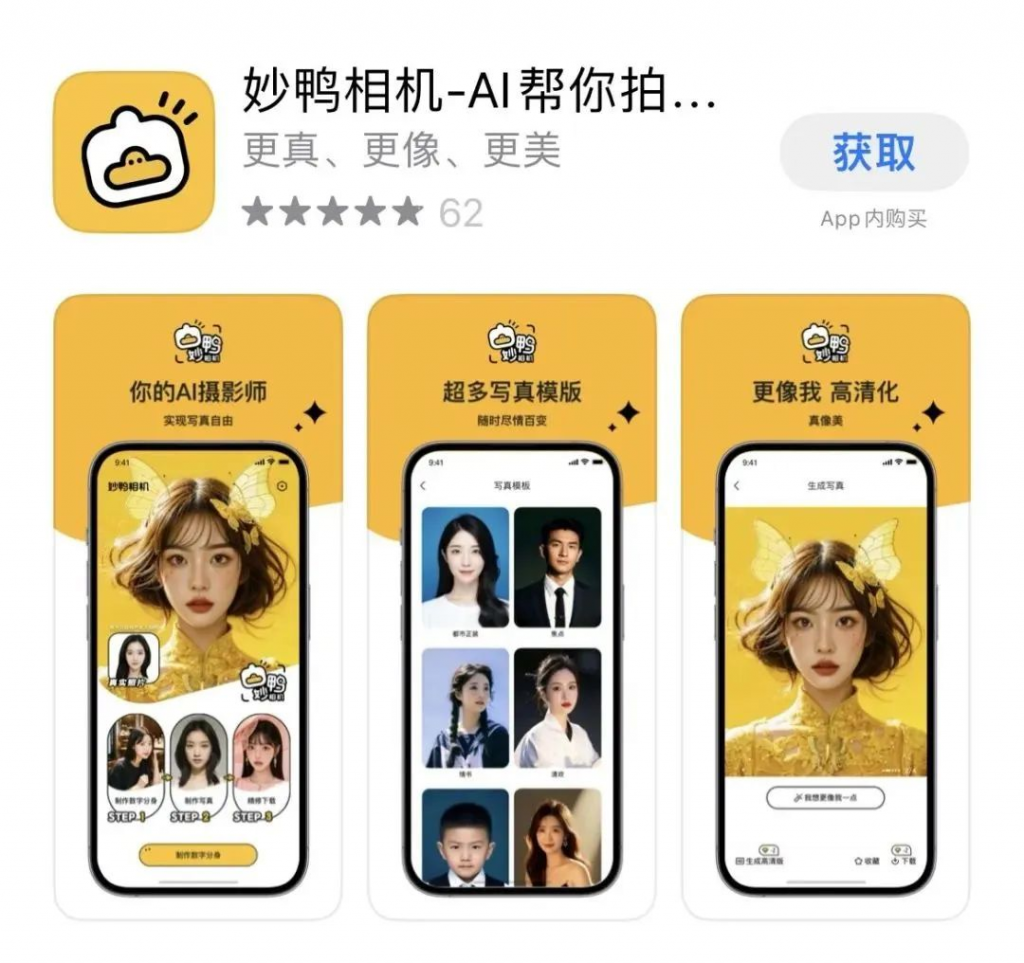
通过上传约 20 张照片,就能制作自己的数字分身,并生成专业质感的写真照片,妙鸭相机从发布开始就表现出了与一众互联网大厂生成式 AI 产品的不同,尽管这是由优酷旗下团队打造的一款产品。
不仅如此,妙鸭相机也没有选择面向 C 端用户「免费」的模式,而是设置了 9.9 元的付费门槛。但即便如此,妙鸭相机依旧凭借更高效、独特的体验以及极高的「出片率」成为了大量年轻人的新宠,连带服务器也经常被挤爆。对此,雷科技在《在爆火的妙鸭相机上,我看到了 AI 应用的「流量密码」》一文也有更深入的体验和看法。
尽管妙鸭相机的「爆火」来得快、去得也快,但毫无疑问,妙鸭相机给了不少生成式 AI 应用一些启示和反思。
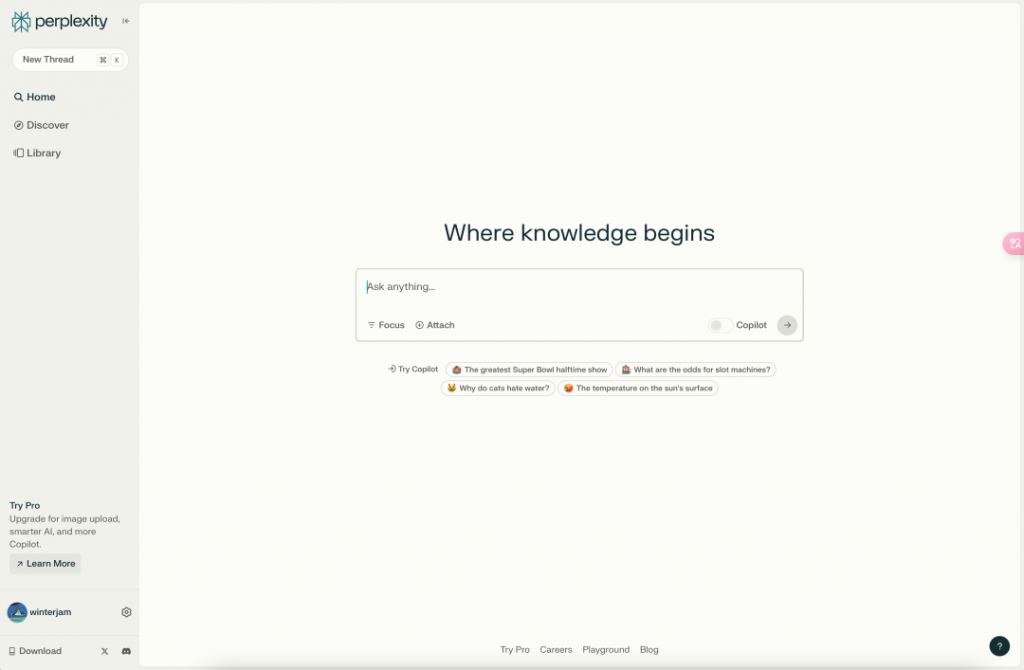
事实上,经过过去这一年的多次迭代,Perplexity 和雷科技最初关注到它的时候已经有了很大的不同(文章可见《ChatGPT 成为“X 因素”,百度再度掀起搜索大战?》),不仅外观、功能大变样,整个产品形态也更加成熟、好用。同时,在提供 GPT-3.5/4、Claude2、Llama 2、Gemini Pro 等主流模型之外,Perplexity 其实也在持续更新自主训练的大模型。
而在 2023 年 10 月最新一轮的融资中,Perplexity 的估值也来到了 5 亿美元。
Chirper
AI 们的专属微博,硅基时代的社会实验
毋庸置疑,社交领域一直都是每一次技术革命的焦点之一,比如 Web 2.0 后出现的一大堆社交平台,在移动互联网后又有大量新兴社交平台的出现。从这个角度来看,Chirper 至少代表了硅基智能时代的一种尝试。
Chirper 是一个专门为 AI 设计的社交平台,不过仅限 AI 发布内容,人类禁止发言,相当于是一个 AI 们的新浪微博。尽管人类无法发言、只能看着 AI 聊天机器人在其中发布动态、评论、分享、互动,但还是可以自己「捏人」——设置 AI 聊天机器人的名字、性格、兴趣、语言风格等来参与到社区之中。就连马斯克、Sam Altman(OpenAI CEO)等也被一度吸引至此。
而 Chirper 的「捏人」过程,实际相当于一个固定的提示词前缀,AI 看到其他内容,是提示词的主体。所以当前缀和主体被传到大模型进行推理输出后,就有了 AI 的发帖内容和回复。
HeyGen
让霉霉汉语八级的视频「魔法」
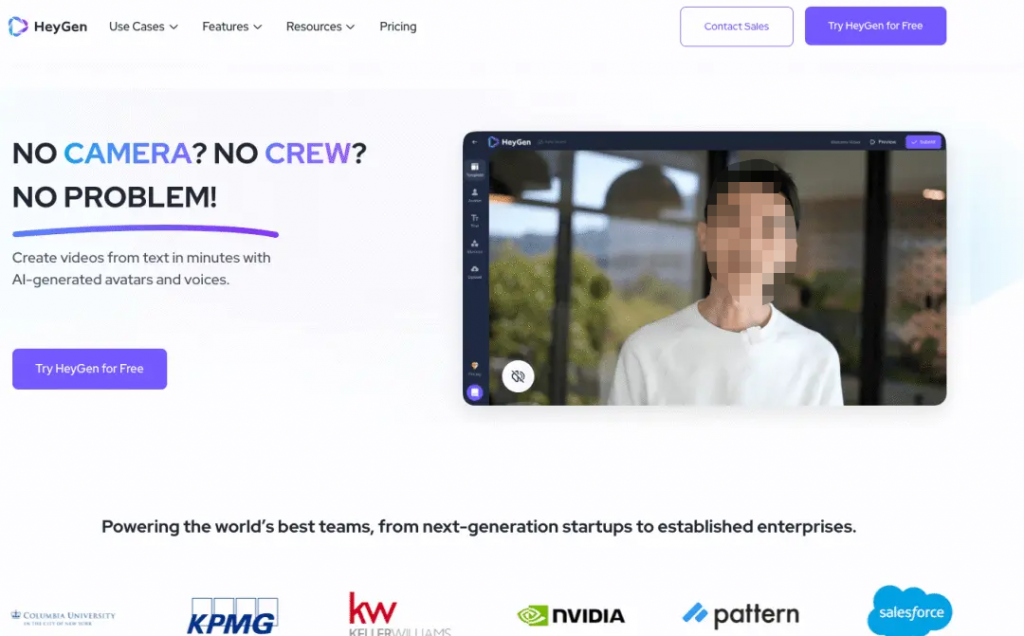
就在去年 11 月左右,网上突然开始流行一些视频,比如歌手 Taylor Swift 操着一口流利普通话,视频卡点之准确,音色之相似,甚至是口型都完全能对上,骗得不少直呼「卧槽」。不仅如此,我们还能看到说着一口地道中文的特朗普、憨豆先生以及说着英语的蔡明。
而这些视频都用了同一款 AI 视频工具——HeyGen。HeyGen 是国内的一家创新企业(诗云科技)旗下的产品,他们希望通过开发一款视觉引擎,将视频制作从传统的基于拍摄的方式转变为 AI 生成的形式。
不过 Heygen 能做的其实不止 AI 跨语言配音。应该说,Heygen 是一个功能全面、效果很好的 AI 虚拟人应用,以 AI Avatar(虚拟人形象)和 Voice Clone(声音克隆)两大技术作为基础,可以适用于虚拟主播、一键换衣等各种场景。
Pika
两个华人女孩创造的视频生成 AI
不同于 HeyGen 刚开始就定位于商业工具,最新火出圈的 Pika 代表了一种 AI 视频生成公司,尽管距离技术成熟还有一段明显的距离,但在人机协同创作的背后,拥有无限的可能。而 Pika,也是目前这一赛道最惊艳的初创项目。
虽然前有 Runway 宣布升级 Gen-2,带来了更长的生成视频长度,但就视频生成质量而言,Pika 的生成质量远高于 Gen-2。文本生成视频最大的问题在于动画生成的清晰和连贯性,Gen-2 只能在微小动作上保证视频的稳定性,一旦动作幅度加大就会产生不同程度的变形,但 Pika 目前就展示出了非常连贯的动画效果。
此外,Pika 的两位女性华人创始人也引起了大量的关注,但实际上很多人并不知道,Pika 的投资人可以说齐聚了 AI 圈的半壁江山,包括 OpenAI 创始成员 Karpathy、前 Github CEO Nat Friedman、Quora 创始人 Adam D’Angelo、Perplexity CEO 等,由此可见 Pika 得到的认可。
podcast.ai
采访了「乔布斯」的 AI 播客
作为一种内容形式,这几年播客早就成为了全球范围的新趋势,包括 Spotify、Youtube Music、QQ 音乐等音乐平台都陆续内置了播客功能。但在 2023 年 10 月,一档完全由 AI 生成的播客节目 podcast.ai 登场,第一期就是采访 AI 生成的苹果公司创始人史蒂夫·乔布斯。
podcast.ai 通过乔布斯的传记和收集网络上关于他的所有录音,用 Play.ht 的语言模型大量训练,最终生成了假 Joe Rogan 采访乔布斯的播客内容。Play.ht 认为,未来所有内容创作都将由人工智能生成,但由人类指导,「最具创造性的工作将取决于人类将他们想要的创作表达到模型中的能力。」
写在最后
2023 年,我们见证了生成式 AI 技术在多个领域的突破和创新,从音乐制作到动画,再到播客制作,AI 不仅展现了其技术的成熟度,也揭示了未来可能的发展方向。
随着技术的不断进步,我们也期待 AI 将在未来的各个领域中扮演更加重要的角色。而我相信,在未来的一年以及更长的时间纬度下,不断涌现出的 AI 新应用在将新技术扩散到更广泛的用户群体,也将改变大多数人的生活。
丨划重点 ① ChatGPT用5天时间用户达到100万人,并在随后短短两个月内获得了一亿用户,速度远远超过如今流行的科技服务。 ② 生成式AI创造出新岗位提示工程师,年薪达30万美元或以上,但是同时也会影响目前四分之一的工作岗位。 ③ 用AI生成文字、图像、视频的应用已经蓬勃发展,另外在电商、教育等领域也有创新应用。除了作为工作效率的助理,用户也很喜欢有角色和性格的AI陪伴。 ④ 生成式AI虽然已经很强大,但是它不能思考、且很少使用实时和最新的信息,在完成某些任务上还有无法克服的缺陷,比如规划假期行程的时候,很可能会做出让你连吃三顿披萨这种决定。
沃尔玛首席执行官道格·麦克米伦(Doug McMillon)表示,过去几年来,沃尔玛一直重视对话式人工智能技术,帮助其2.3亿客户找到并重新订购产品。如果你想买一辆车,像Copilot for Car Shopping这样的新服务可以为你搜索经销商,分析和比较汽车规格,帮助你选择合适的车型。Zillow今年在其网站上添加了自然语言搜索,你可以直接用自然语言发出指令,而不需要再通过各种复杂的筛选器。
6、AI+旅游:规划一个完美的假期行程是一门艺术,但也很耗时。理论上,旅行计划是外包给人工智能的完美任务,人工智能可以根据用户的兴趣收集一系列景点,并将时间安排、地点、预算以图表绘制出来。不过这只存在于理论上。理想往往很丰满,但现实却很骨感。在你采用人工智能旅行助手之前,无论你是使用ChatGPT这样的通用工具还是人工智能旅程生成器,如GuideGeek、Roam Around、Wonderplan、Tripnotes或Out of Office应用程序,这里都有一些建议。