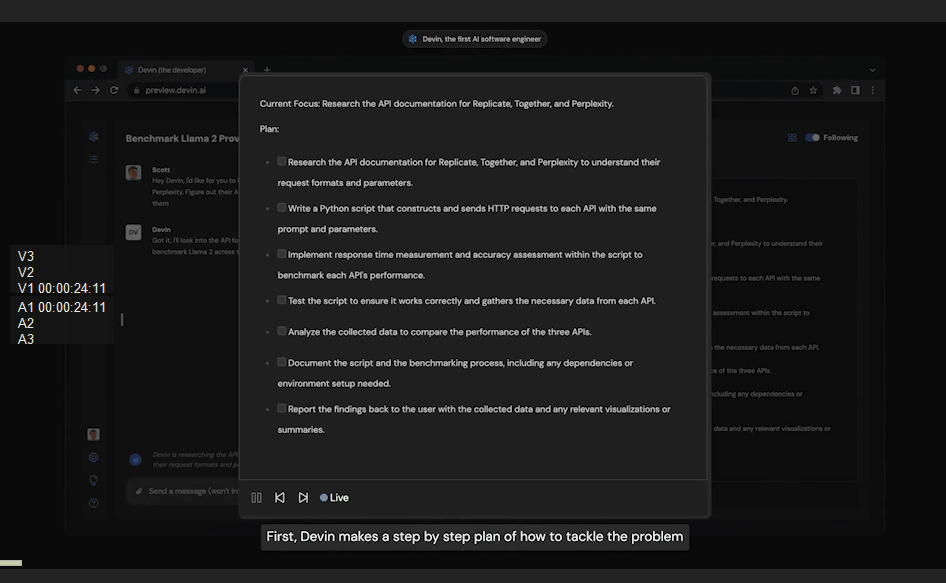
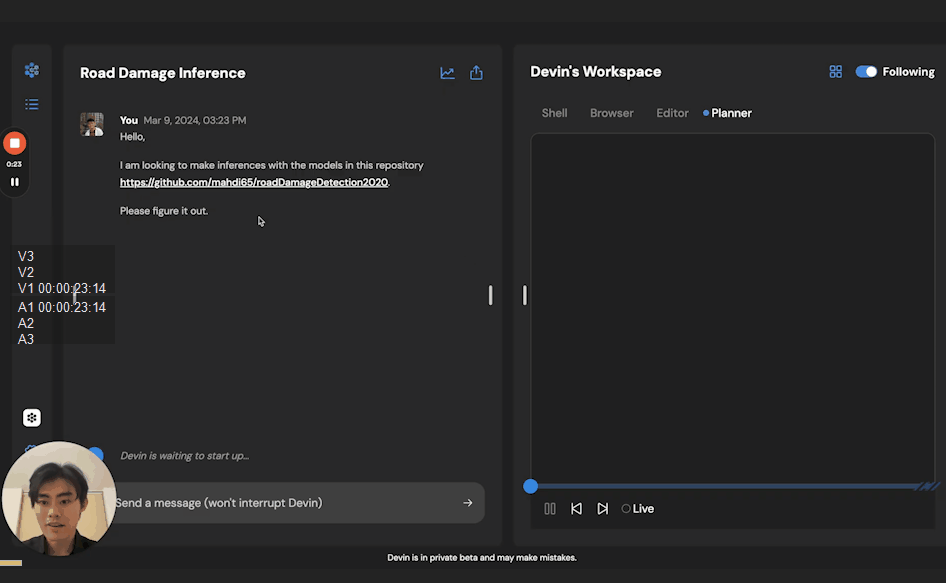
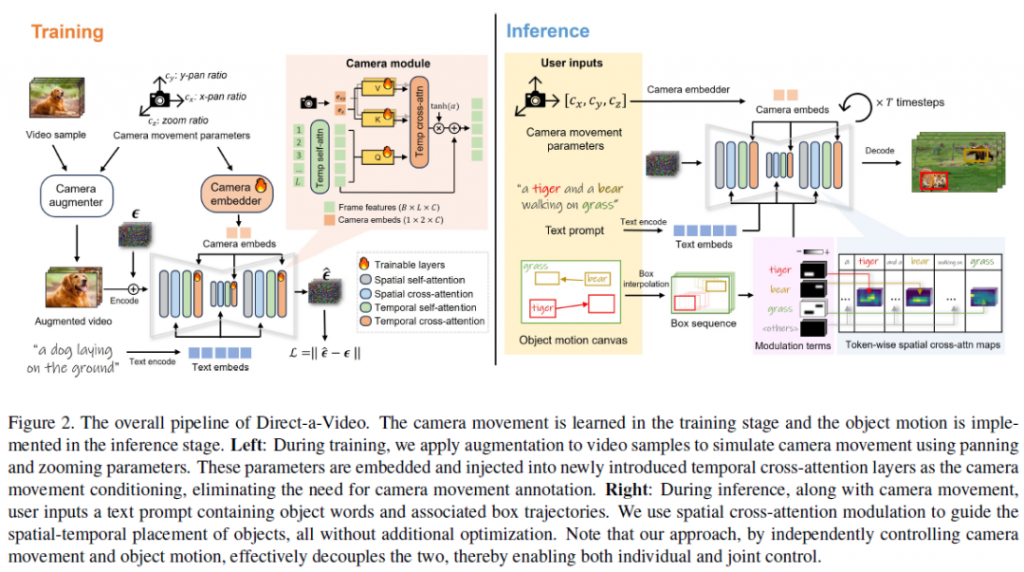
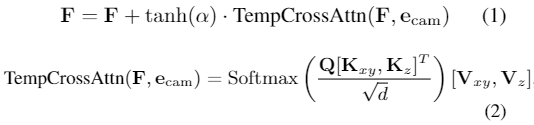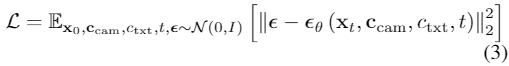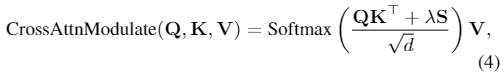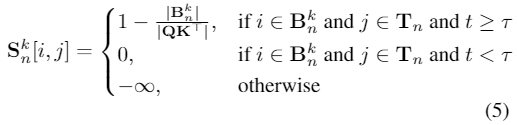ReALM(Real-time Analysis of Live Media)是苹果公司研究团队开发的一款设备端AI模型。这款模型的参数量达到了惊人的8亿,部分性能甚至超过了GPT-4,使其具备理解前后文关系的能力,从而提高反应效率。ReALM不仅适用于实际产品,如ChatGPT,而且可以与各大科技巨头如Google、微软、OpenAI和亚马逊展开竞争。目前尚无法确定苹果是否会将其应用于iPhone、iPad和Mac等设备,但考虑到苹果已多次暗示将在2024年推出AI产品,我们期待在今年WWDC 2024上看到更多相关信息。
此外,魅族21 PRO 3200万像素的超清前置摄像头和全新AI人像焕颜算法的结合,让每次自拍都成为一次美丽的绽放。配合硬件配置,魅族21 PRO在软件调教上也带来全新突破。通过智绘影调功能的引入,魅族21 PRO为摄影爱好者带来更多的创作体验,不仅支持多种滤镜效果和创意拍摄模式,还能根据用户的喜好和风格进行个性化设置。音质方面,魅族21 PRO采用第六代大师级“双”· 超线性扬声器。
通信方面,通过无界天线系统2.0和mSmart Net技术的加持,魅族21 PRO将为用户提供畅通无界的通信体验。在充电续航能力上,除了支持80W Super mCharge有线超充体验,魅族21 PRO还支持50W Super Wireless mCharge无线快充和10W无线反向充电功能,以及5050mAh高密度耐久电池。
上周,AI 界的一件大事是:微软宣布与总部位于巴黎的法国初创公司 Mistral AI 建立合作伙伴关系。后者成立时间仅 9 个月,而公司 CEO 是年仅 31 岁的亚瑟.门施。需要注意的是:
微软将向 Mistral AI 投资 1630 万美元,以换取该公司的少量股份。而 Mistral AI 也将在微软云上提供自己的 LLM,以便开发人员可以通过微软云 Azure 购买。如,该公司上周发布的最新 AI 模型 Mistral Large,就将首先通过微软的云平台 Azure 提供。
第二,这笔交易也凸显了微软可能想要做一个平台的野心。考虑到之前微软与 OpenAI 的交易,微软可以让企业在自己平台上访问由多个不同供应商创建的 AI 模型。
第三,作为一家成立仅 9 个月的初创公司,Mistral AI 在 AI 领域实际上备受关注,被誉为是“欧洲版的 OpenAI”。根据三位联合创始人的说法,Mistral AI 成立的部分原因是,他们认为 AI 领域的很多钱都被浪费掉了:“我们希望成为 AI 领域资本效率最高的公司,这就是我们存在的原因。
一,亚瑟.门施其人其事Mistral AI 由三位联合创始人成立,分别是:现年 31 岁的亚瑟.门施、32 岁的蒂莫西·拉克鲁瓦,以及 33 岁的纪尧姆·兰普尔。其中,CEO 亚瑟.门施来自谷歌旗下 DeepMind 的 Google AI 部门,他在团队中从事构建 LLM 的工作。后两位创始人,则在扎克伯格 Meta 的巴黎 AI 实验室工作。
根据我查阅的资料:Mistral AI 成立仅九个月,目前估值略高于 20 亿美元。在与微软公司合作前,其已经从硅谷顶级风投机构光速创投、A16z 等投资者那里筹集了 5 亿多美元。其中,光速创投是 Mistral AI 的种子轮领投者,而 A16z 则是 A 轮领投者。
该公司的 CEO 亚瑟.门施是备受关注的人物。根据《华尔街日报》的报道:31 岁的门施从学术界起步,一生中的大部分时间,都在研究如何提高 AI 以及机器学习系统的效率。长期以来,门施一直在学术追求与创业追求之间徘徊。他在巴黎西部的郊区长大,母亲是物理教师,父亲则经营一家小型科技企业。
生成式 AI 领域,又有重量级产品出现。 周一晚间,Mistral AI 正式发布了「旗舰级」大模型 Mistral Large。与此前的一系列模型不同,这次 Mistral AI 发布的版本性能更强,体量更大,直接对标 OpenAI 的 GPT-4。而新模型的出现,也伴随着公司大方向的一次转型。 随着 Mistral Large 上线,Mistral AI 推出了名为 Le Chat 的聊天助手(对标 ChatGPT),任何人都可以试试效果。
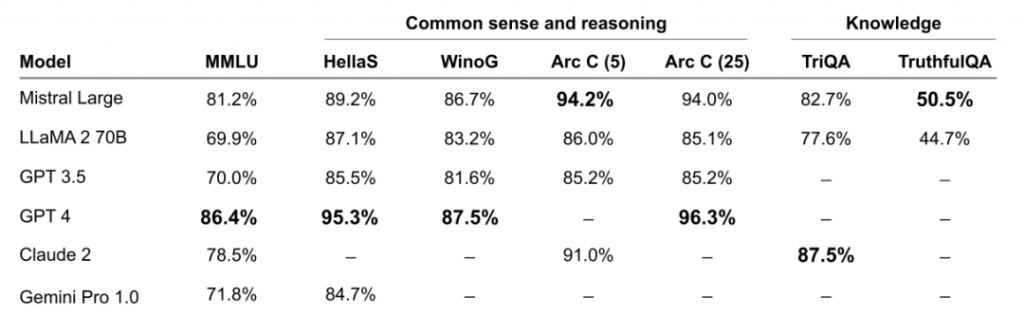
试用链接:https://chat.mistral.ai/ 此前,Mistral AI 提出的 Mistral-Medium 因为强大的性能、「意外」的开源而名噪一时,目前很多大模型初创企业都已不再对标 Llama 2,而是将 Mistral AI 旗下模型作为直接竞争对手。此次 Mistral Large 的出现,自然迅速吸引了众人关注。 人们首先关注的是性能,尽管在参数数量上不及 GPT-4,Mistral-Large 在关键性能方面却能与 GPT-4 媲美,可以说是当前业内的前三:
Mistral Large 的推理准确性优于 Claude 2、Gemini 1.0 Pro、GPT-3.5,支持 32k token 的上下文窗口,支持精确指令,自带函数调用能力。 人们也发现 Mistral Large 的推理速度超过了 GPT-4 和 Gemini Pro。然而优点到此为止。 模型除了增加体量,也需要有相应的数据。在模型发布后,人们发现它生成的文本有一种 ChatGPT 的既视感。
如果说为了能赶上业内最先进的 GPT-4,使用 AI 生成的内容进行训练或许并不是什么大问题。但 Mistral Large 的出现也给 AI 社区的人们带来了危机感:它并不是一个开源大模型。
这次发布的大模型有跑分,有 API 和应用,就是不像往常一样有 GitHub 或是下载链接。 有网友发现,新模型发布后,Mistral AI 官网还悄悄把所有有关开源社区义务的内容全部撤掉了:
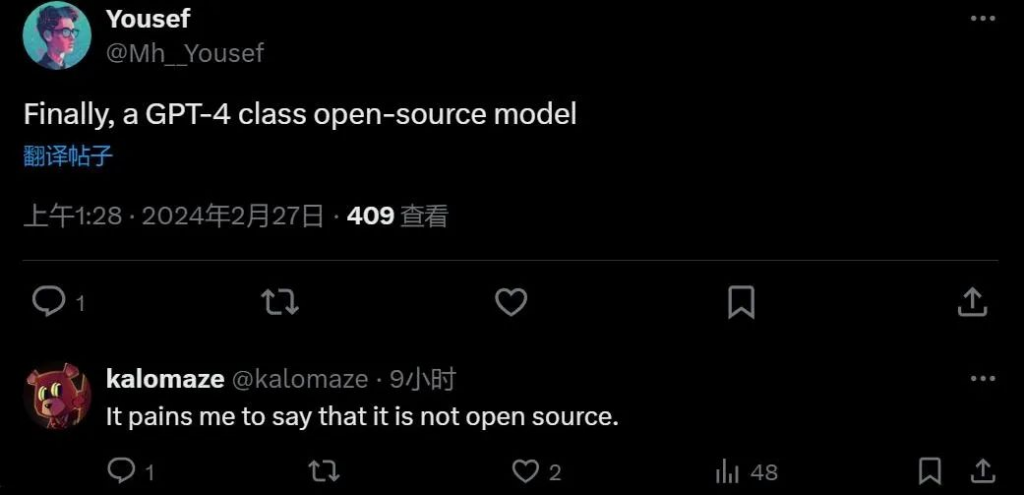
难道以开源起家的 Mistral AI,成立才不足一年,这就要转向了吗? Mistral Large 目前已经能在 Mistral AI 自有平台 La Plateforme 和微软 Azure 上使用。除了 Mistral Large 之外,Mistral AI 还发布了新模型 Mistral Small,针对延迟和成本进行了优化。Mistral Small 的性能优于 Mixtral 8x7B,并且推理延迟得到了降低,提供了一种开放权重模型和旗舰模型之间的中间方案。 但模型的定价也引发了一些质疑。比如 Mistral Small 的低延迟相比于 Mixtral 8x7B 的提升微乎其微,但输入贵了 2.8 倍,输出贵了 8.5 倍:
如果以商业大模型的标准来看待,Mistral Large 的定价和 GPT-4 相比并不具备优势,这又该如何吸引客户呢?
这位业内人士表示:「如果它的价格是 GPT-4 Turbo 的一半,我会更理解。」
新的 Mistral AI「大杯」模型,表现如何? 在官方博客中,Mistral AI 详细介绍了 Mistral Large 的功能和优势: Mistral Large 在多个常用基准测试中取得了优异的成绩,使其成为世界上排名第二的可通过 API 普遍使用的模型(仅次于 GPT-4):
与微软合作,行 OpenAI 故事 在发布 Mistral Large 等模型的同时,Mistral AI 还宣布了一个消息:将与微软合作,在 Azure 上提供自己的模型。 此次合作使 Mistral AI 成为第二家在微软 Azure 云计算平台上提供商业语言模型的公司。这有助于 Mistral AI 将自己的模型推向市场,也让 Mistral AI 有机会使用 Azure 的尖端 AI 基础设施,以加速其下一代大型语言模型的开发和部署。
这家公司表示,「在 Mistral AI,我们的使命是让前沿人工智能无处不在。这就是我们今天宣布将自己的开放和商业模型引入 Azure 的原因。微软对我们模型的信任让我们前进了一步!」 这项为期多年的协议标志着微软正在其最大的赌注 OpenAI 之外,努力提供各种人工智能模型,为其 Azure 云服务吸引更多客户。去年 11 月,OpenAI 经历了 CEO Altman 被解雇(后又重返)的风波。而作为最大的股东,微软在消息公布前 5 到 10 分钟才从 OpenAI 那里得到消息。在这次动荡后,微软设法在控制 OpenAI 的非营利性董事会中获得了一个无投票权的观察员席位。这让他们对 OpenAI 的内部运作有了更多了解,但在重大决策上,微软依然没有投票权。 Mistral AI 对路透社表示,作为交易的一部分,微软将持有该公司少数股权,但未透露细节。 微软证实了对 Mistral AI 的投资,但表示不持有该公司的股权。这家科技巨头因向 OpenAI 提供巨额资金而受到欧洲和美国监管机构的审查。 根据公告,微软与 Mistral AI 的合作主要集中在三个核心领域:
超算基础设施:微软将通过 Azure AI 超级计算基础设施支持 Mistral AI ,为 Mistral AI 旗舰模型的 AI 训练和推理工作负载提供一流的性能和规模;
市场推广:微软和 Mistral AI 将通过 Azure AI Studio 和 Azure 机器学习模型目录中的模型即服务(MaaS)向客户提供 Mistral AI 的高级模型。除 OpenAI 模型外,模型目录还提供了多种开源和商业模型。
人工智能研发:微软和 Mistral AI 将探索为特定客户训练特定目的模型的合作。
除了微软,MistralAI 还一直在与亚马逊和谷歌合作,分销自己的模型。一位发言人表示,该公司计划在未来几个月内将 Mistral Large 应用于其他云平台。 Mistral AI 成立于 2023 年 5 月,由来自 Meta Platforms 和 Alphabet 的几位前研究人员 ——Arthur Mensch(现任 CEO)、Guillaume Lample 和 Timothee Lacroix 共同创立。成立不到四周,Mistral AI 就获得了 1.13 亿美元 的种子轮融资,估值约为 2.6 亿美元。成立半年后,他们在 A 轮融资中筹集了 4.15 亿美元,估值飙升至 20 亿美元,涨了七倍多。而此时,他们仅有 22 名员工。
2 月 16 日 OpenAI 发布了一个新的 AI 视频生成模型 Sora,它可以根据文本生成 60s 的高质量视频,完全突破了之前 AI 文生视频存在的各种局限,所以一出现就引起广泛关注和热烈讨论,大家应该对它都有所了解。
今天就根据网上已公布的视频,对 Sora 的功能特性进行一个盘点总结,其中包含与 Runway、Pika 等 AI 视频工具的生成效果对比,让大家对 Sora 的能力有一个更直观全面的了解。
一、60s 超长视频
之前优设已经推荐过 AI 视频工具,比如 Runway、Pika、MoonVally、Domo AI、AnimateDiff、Stable Video 等,它们文生视频长度都在 3-7 秒之间(Aminatediff 和 Deforum 因形式不同,不列入此处的比较),而 Sora 直接将时长最高提升到 60s,是之前的 10 倍,这样的长度是放在之前大家可能觉得要好几年才能实现,但是 Sora 让其一夜之间成为现实。
二、超高的文生视频质量
接触过 AI 视频生成的小伙伴肯定清楚,文本生成的视频效果最难控制,很容易出现画面扭曲、元素丢失情况,或者视频根本看不出动态。所以不少 AI 视频工具都转向在图生视频或者视频转绘上发力,比如 Runway 的 Motion Brush 笔刷,通过在图像上涂抹指定区域添加动效;以及 Domo AI,可以将真实视频转为多种不同的风格,这些方式让 AI 视频更可控,因此质量更好。
而 Sora 的出现则完全颠覆了人们对文生视频的认知,不仅直接能通过文本生成各种风格的高清的视频,还支持多样化的视频时长、分辨率和画幅比,并且能始终保持画面主体位于视频中央,呈现出最佳构图。
三、连贯一致的视频内容
Sora 生成的视频中,随时长增加人物及场景元素依旧能保持自己原有原有的状态,不会扭曲变形,所以视频前后连贯性非常好。即使元素被遮挡或者短暂离开画面,Sora 依旧能在后续准确呈现这一对象的相关特征。
Sora 能针对一个场景或者一个主题进行多视角呈现,比如针对“下雪天的街道”主体,可以同时生成手部玩雪特写、街道元素特写、行人走动中景、街道全景等分镜。
下面是从 Sora 视频中截取一段,可以看到随着镜头旋转,新视角中无论是机器人还是背后环境的细节都能稳定呈现,如同 CG 建模一样精准。之前为大家介绍过 Stable zero 123,一种可以生成多视角图像的 AI 模型,但效果远比不上在视频中的呈现,也许 Sora 能为我们提供一种生成角色三视图的新方法。
五、自然流畅的动态
推特网友 @Poonam Soni 制作的了几组 Sora 与 Runway 的效果对比。无论是小狗打闹、云朵的飘动还是袋鼠跳舞,Sora 的动态都非常自然,就像我们在现实中看到的那样;相比之下 Runway 生成的动作总有一种 “慢放”的感觉,不够自然。
2024年,AI落地的重点是如何与用户一起成长。”一个通过找对场景,顺利在模型层占有一席之地的典型案例,是估值达5.2亿美元的AI公司Perplexity。Perplexity通过将大模型和搜索引擎结合,开发出了类似于New Bing的对话式搜索引擎。不过,Perplexity的模型,最初是基于一些规模更小、推理更快的模型进行微调而来。直到最近,他们才开始训练自己的模型。对于前期“套壳”的决定,Perplexity CEO Aravind Srinivas在播客节目中锐评:“成为一个拥有十万用户的套壳产品,显然比拥有自有模型却没有用户更有价值。”
同一天,魅族也官宣重磅消息。据“魅族科技”官微消息,魅族今日决定,将All in AI,停止传统“智能手机”新项目,全力投入明日设备AI For New Generations。2024年魅族面向AI时代全新打造的手机端操作系统将进行系统更新。此外,魅族首款AI Device硬件产品也将在今年内正式发布。
魅族称,经过两年的团队磨合、资源配置、产品布局以及相关技术的充分预研,魅族目前已具备向AI领域全面转型的能力。作为一家全面发展的科技生态公司,魅族拥有完善的研发和供应链等硬件团队,同时还拥有体系化开发、设计、交互的软件团队,这将为魅族All in AI提供坚实的技术支持和服务保障。
在本次AI发布会上,魅族同时公布了AI战略规划的详细内容,包括打造AI Device产品、重构Flyme系统和建设AI生态。魅族将通过三年的生态布局和技术沉淀,逐步完成All in AI愿景。按照规划,2024年魅族面向AI时代全新打造的手机端操作系统将进行系统更新,构建起AI时代操作系统的基建能力;此外,魅族首款AI Device硬件产品也将在今年内正式发布,并与全球顶尖的AI Device厂商展开正面竞争。
考虑到新老用户的过渡需求,在魅族All In AI过渡期内,原魅族Flyme、Flyme Auto、Flyme AR、MYVU、PANDAER以及无界智行业务的用户体验及服务将不会受到影响。另外,现有在售的魅族手机产品将继续为用户提供正常的软硬件维护服务。已购买的魅族20系列、魅族21旗舰手机的用户,仍将享受原有的售后及相关服务保障。
随着人工智能技术的不断发展,聊天机器人已经成为我们生活中的一部分。而英伟达近日推出的Chat With RTX,给这个领域注入了新的活力。与传统的网页或APP聊天机器人不同,Chat With RTX需要安装到个人电脑中,并且采用本地运行模式。这种创新不仅提高了运行效率,还可能意味着对聊天内容没有那么多限制。
借助开源LLM支持本地运行
Chat With RTX并非是英伟达自己搞了个大语言模型,而是基于两款开源LLM,即Mistral和Llama 2。这两款模型提供了强大的语言理解和生成能力,用户可以根据自己的喜好选择使用。
上传本地文件提问,支持视频回答
Chat With RTX的功能也相当丰富。用户可以上传本地文件提问,支持的文件类型包括txt,.pdf,.doc/.docx和.xml。而且,它还具备根据在线视频回答问题的能力。这些功能的实现得益于GPU加速,使得答案生成速度飞快。
功能强大,但也存在一些问题
然而,即使Chat With RTX功能强大,也并非没有短板。在处理大量文件时,它可能会出现崩溃的情况。而且,它似乎无法很好地记住上下文,导致后续问题不能基于前面的对话进行。
优异的本地文档搜索与文件安全性
尽管存在一些问题,但Chat With RTX在搜索本地文档方面表现优异。其速度和精准度让人印象深刻。此外,由于是本地运行,用户的文件安全性也得到了保障。
结语
总的来说,英伟达Chat With RTX的推出为聊天机器人领域带来了新的可能性。虽然存在一些问题,但其本地运行模式和强大的功能仍然值得期待。随着技术的不断进步,相信Chat With RTX在未来会有更加出色的表现。