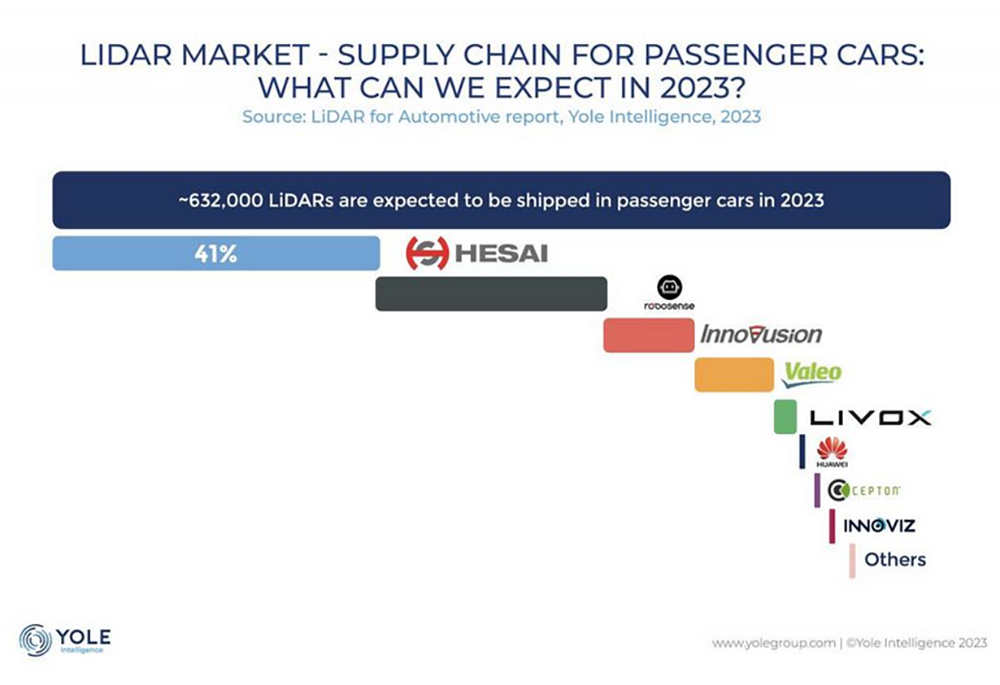
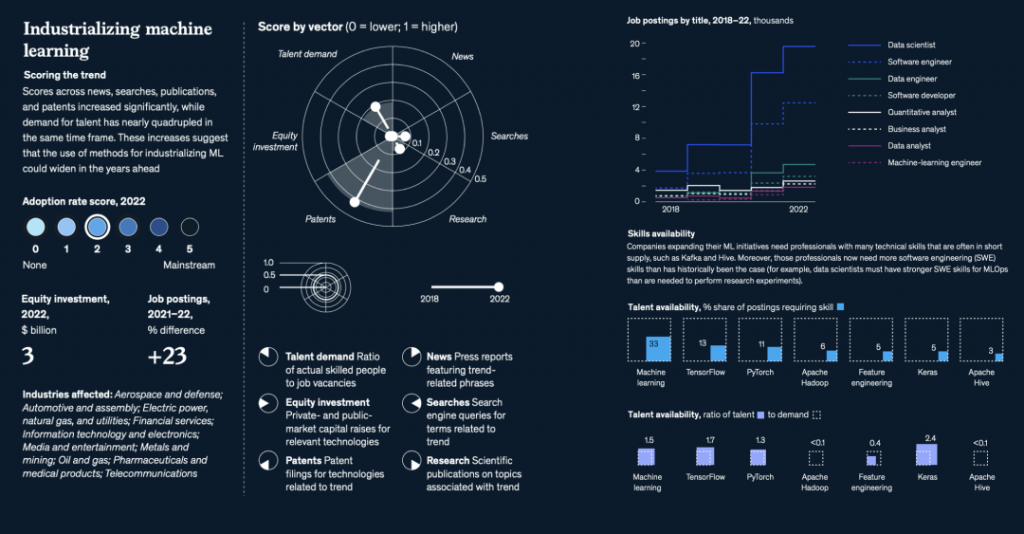
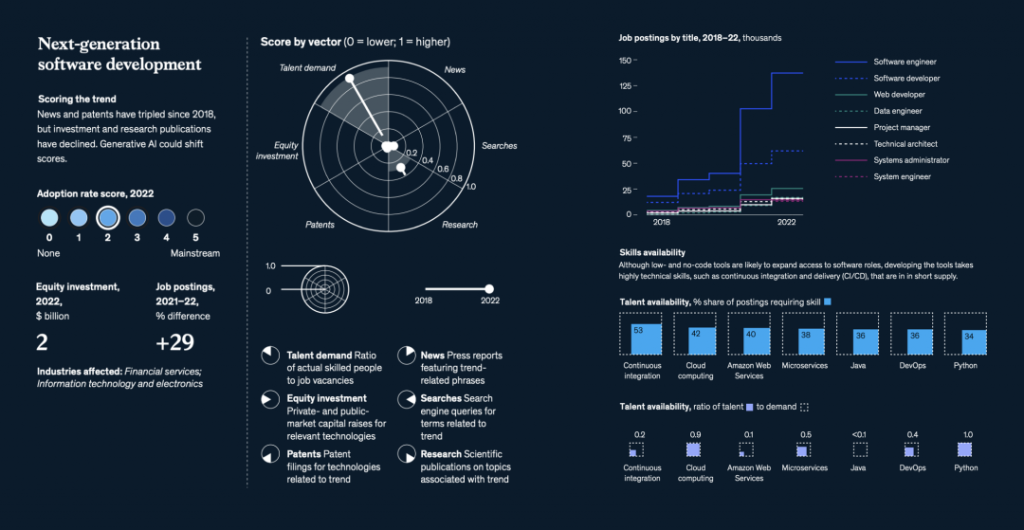
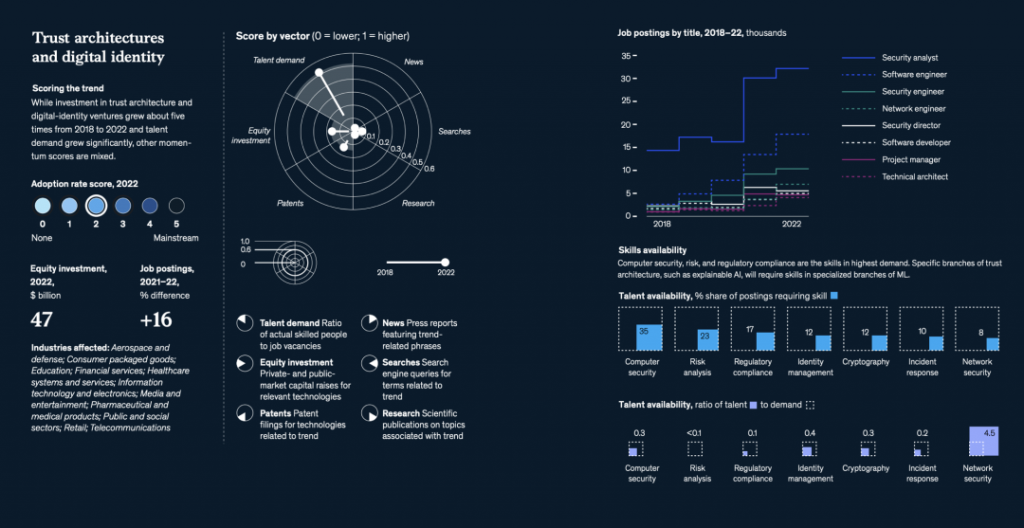
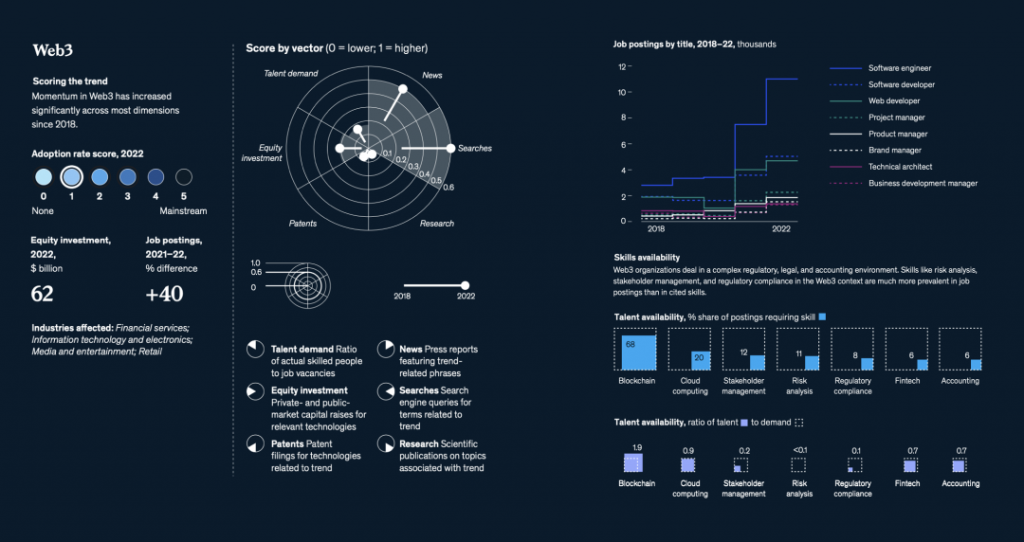
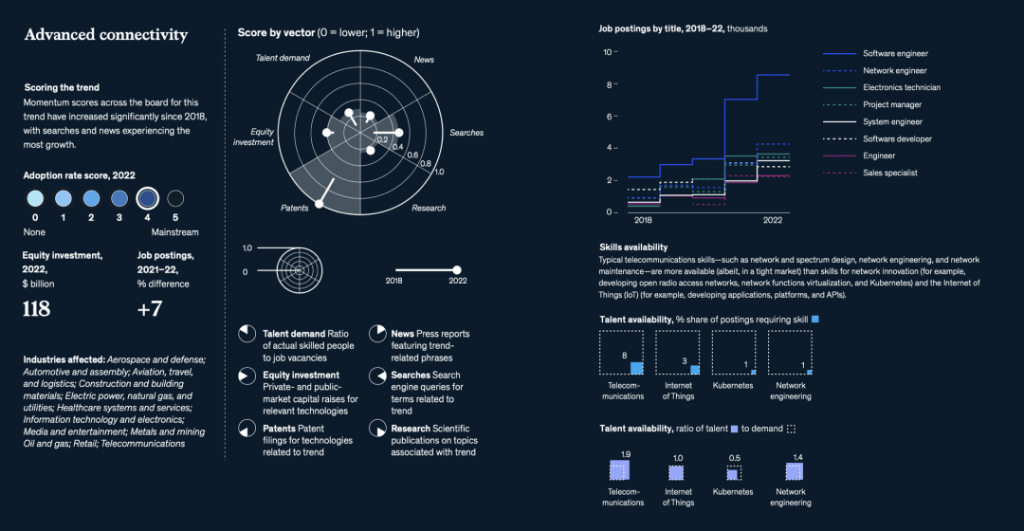
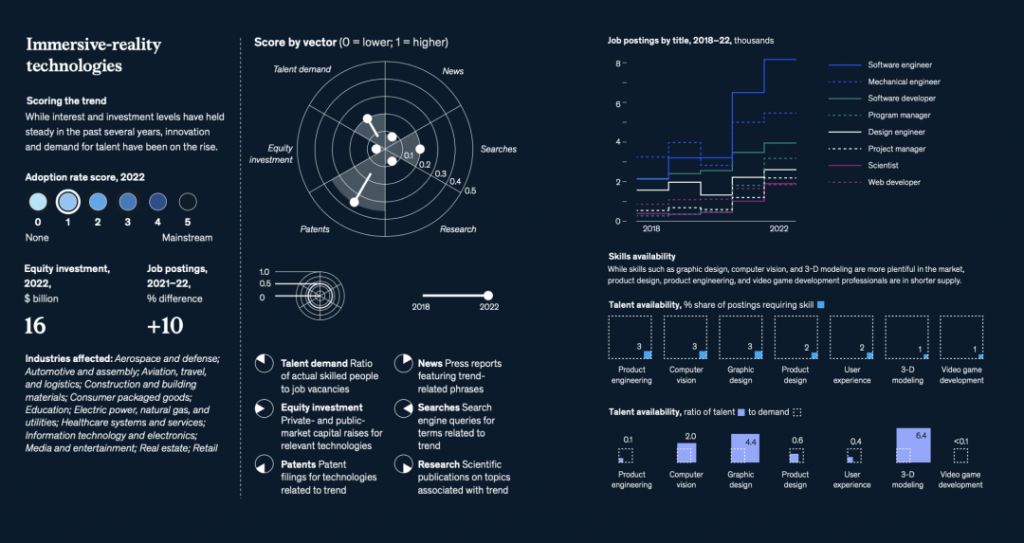
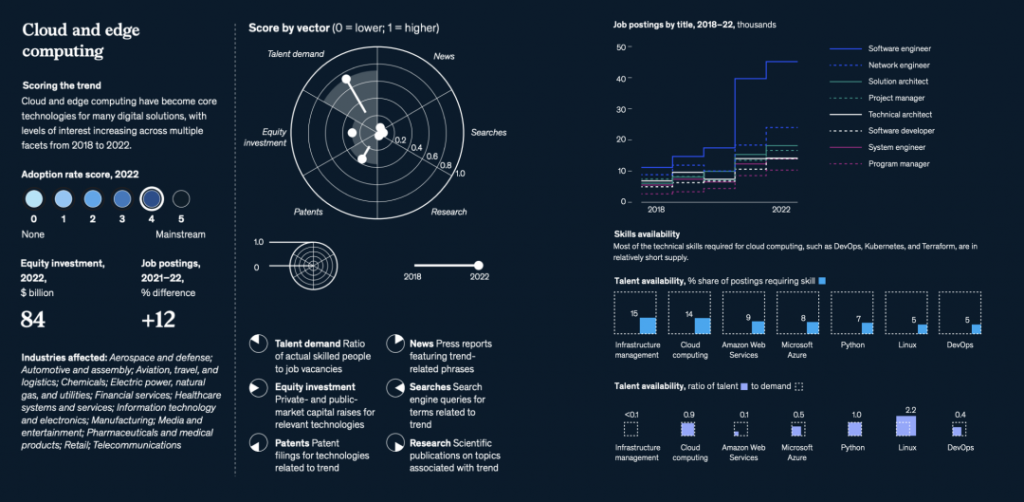
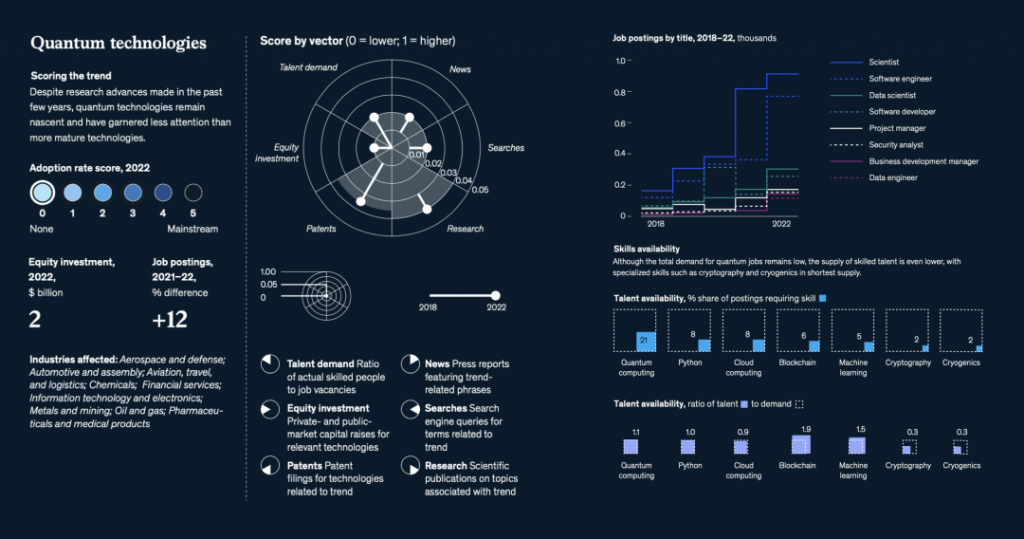
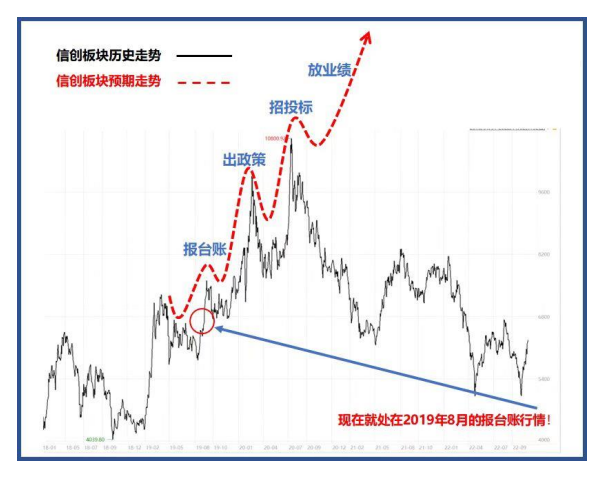
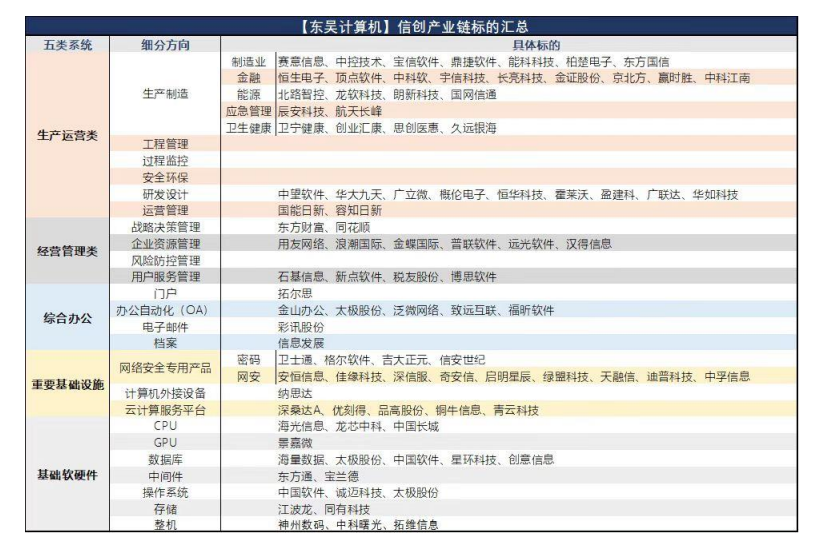
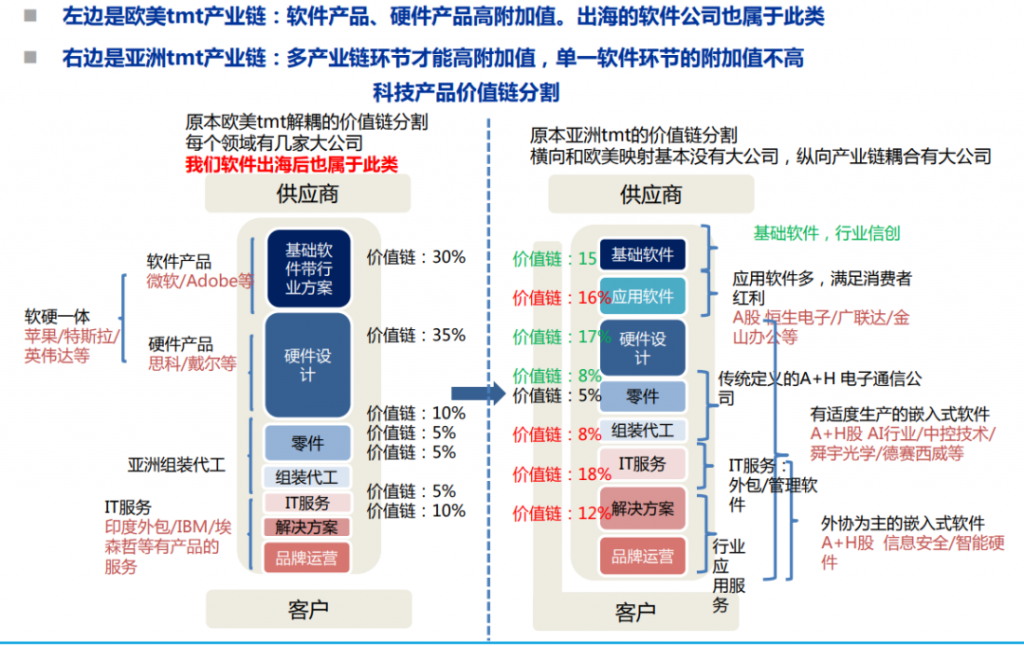
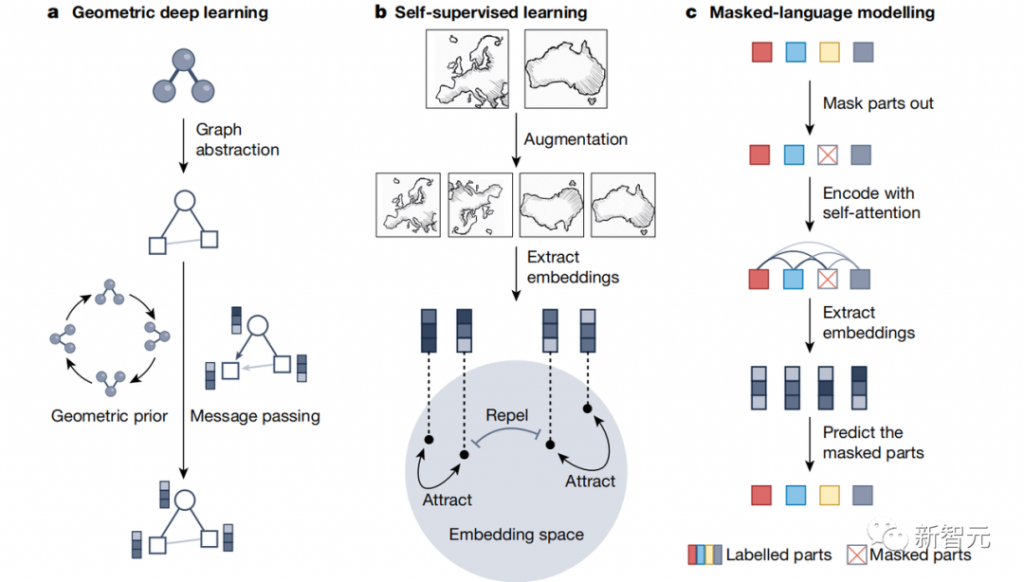
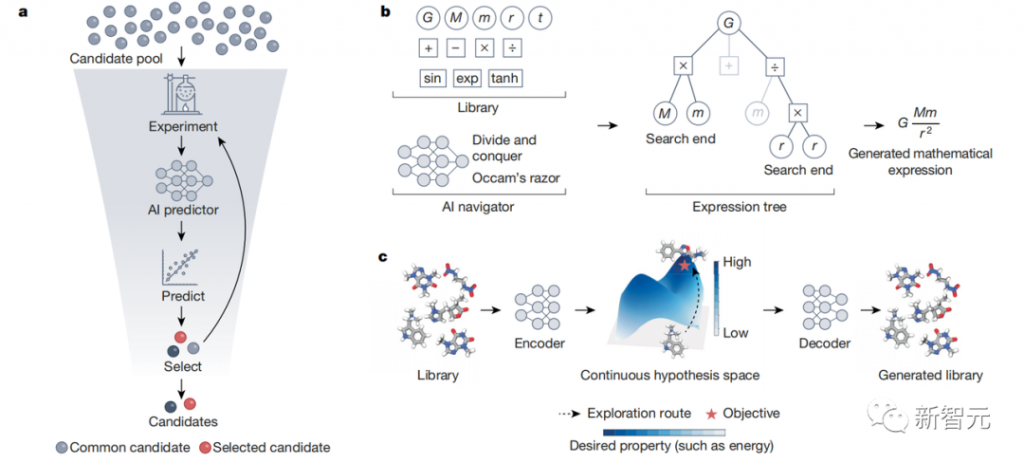
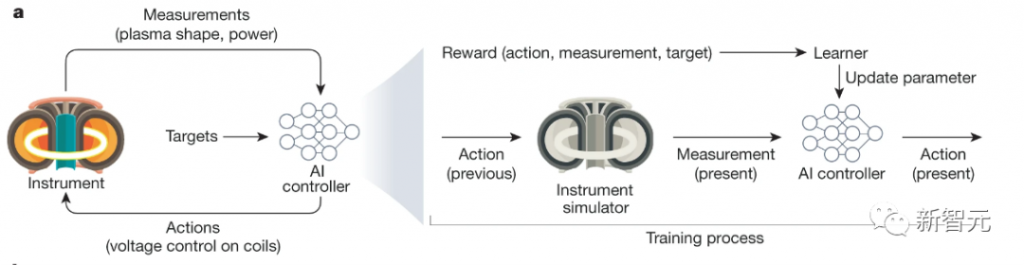
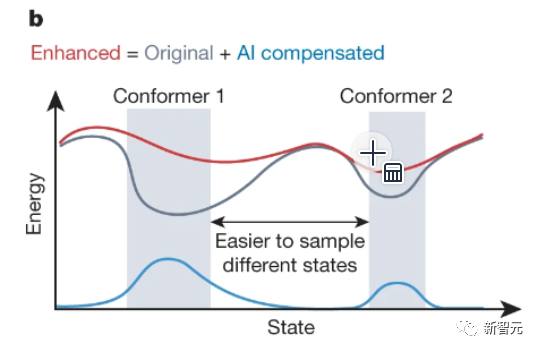
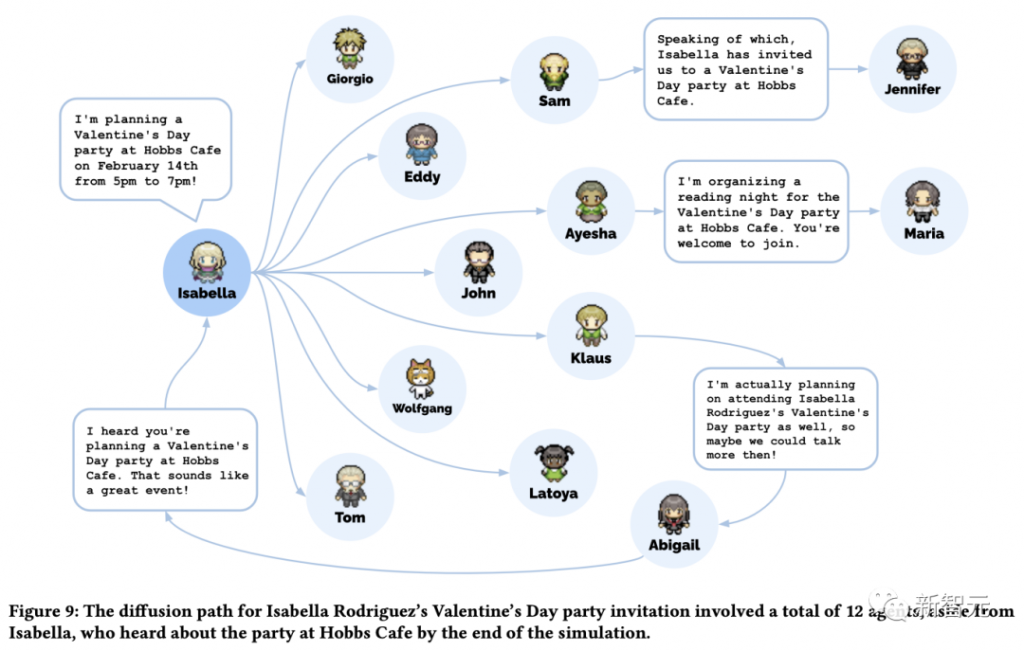
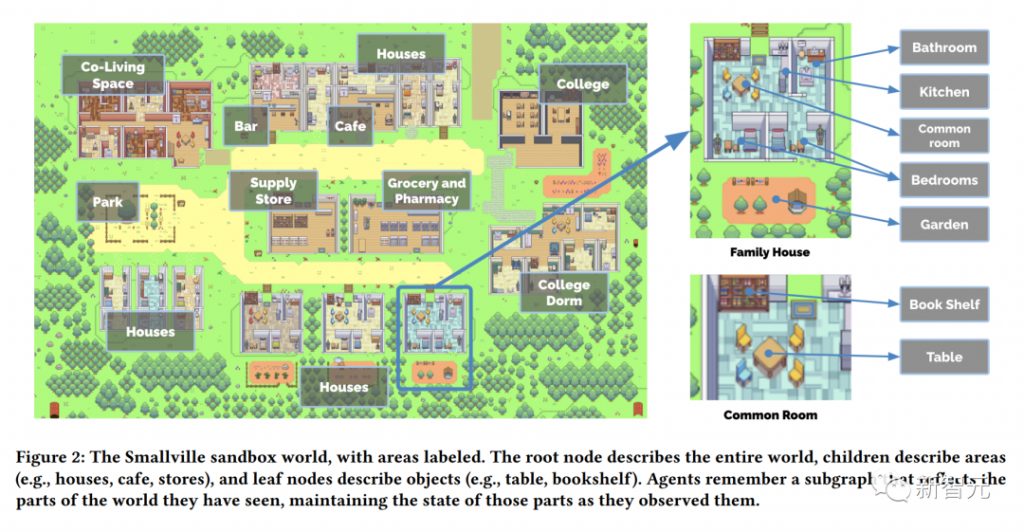
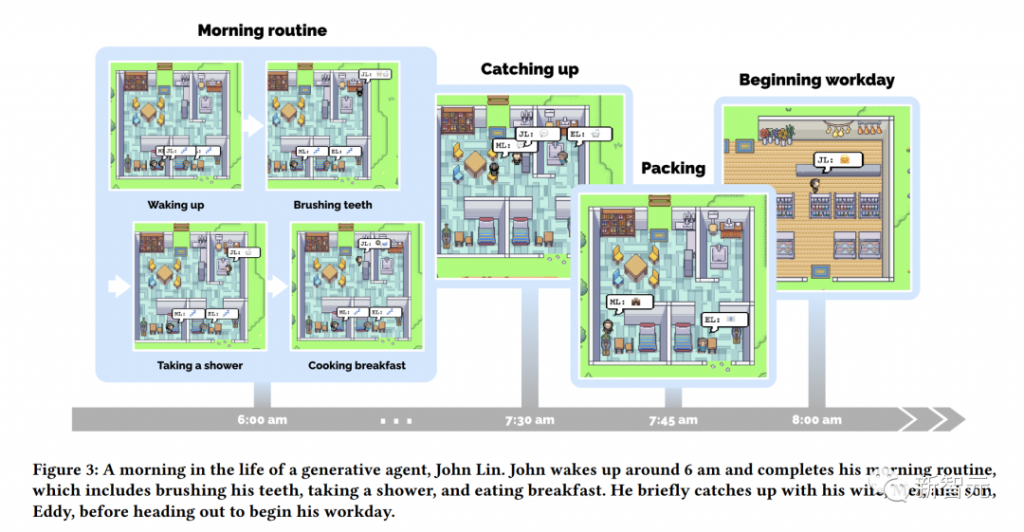
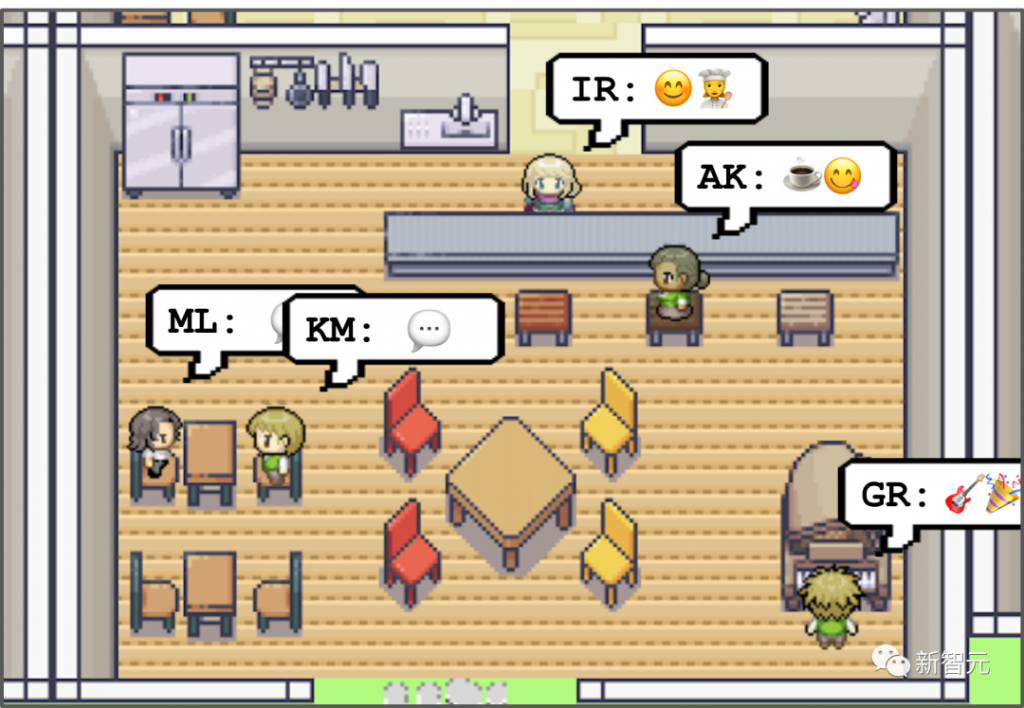
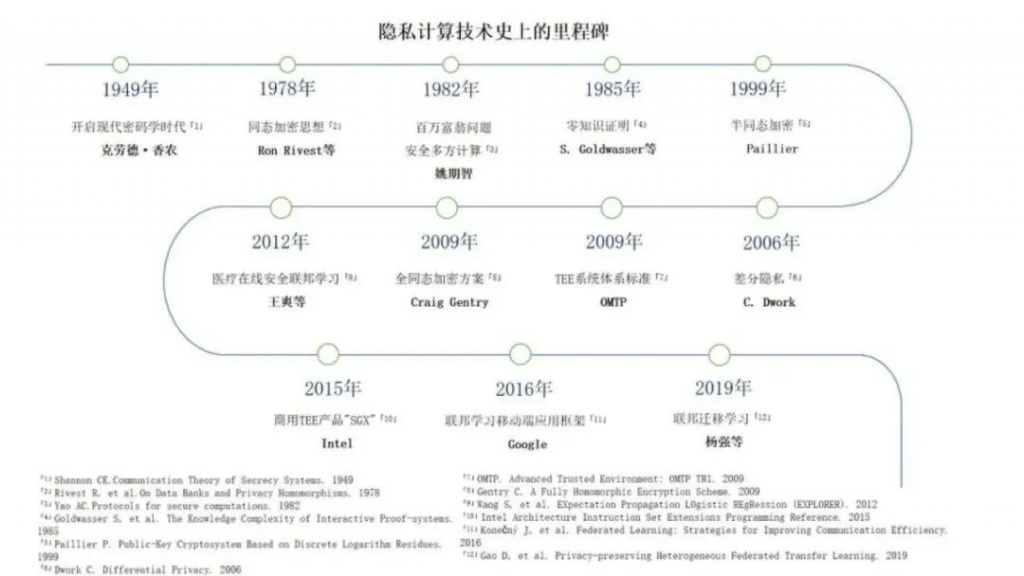
国际劳工组织(ILO)近日发布报告,表示生成式 AI 固然不会接管、替代所有人的工作,但对于以女性为主的文书岗位会产生较大影响。研究报告称尤其在发达国家,在文书相关岗位中女性员工的占比更高。在高收入国家,8.5% 的女性就业岗位可以实现高度自动化,而男性就业岗位占比为 3.9%。研究报告认为大多数工作岗位和行业开始朝着自动化方向发展,生成式 AI 是现有岗位的补充,而非替代。报告认为受生成式 AI 影响最大的岗位是文书工作,大约四分之一的工作可以通过自动化方式完成,交由生成式 AI 来生成文本、图像、声音、动画、3D 模型和其他数据。报告认为经理和销售人员等大多数其它职业受到生成式 AI 的影响并不会太大。
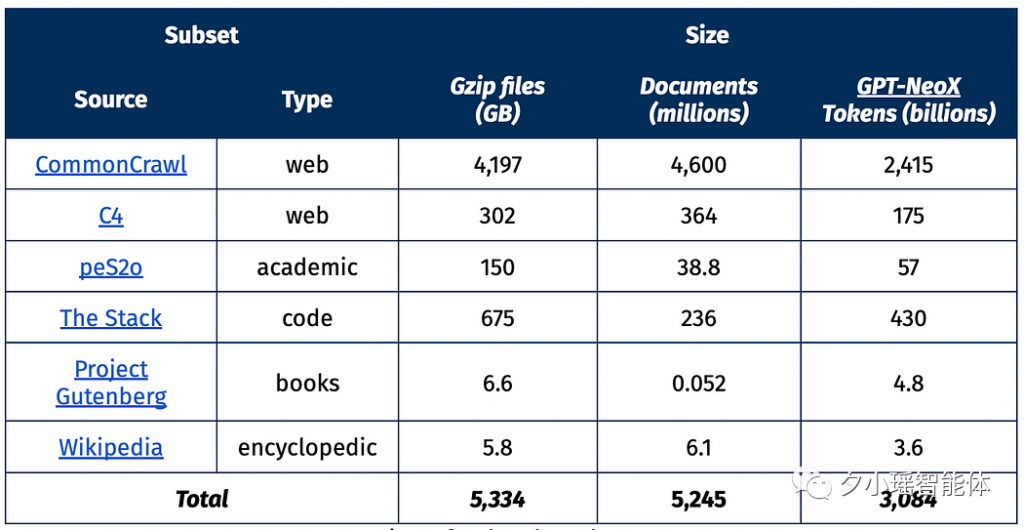
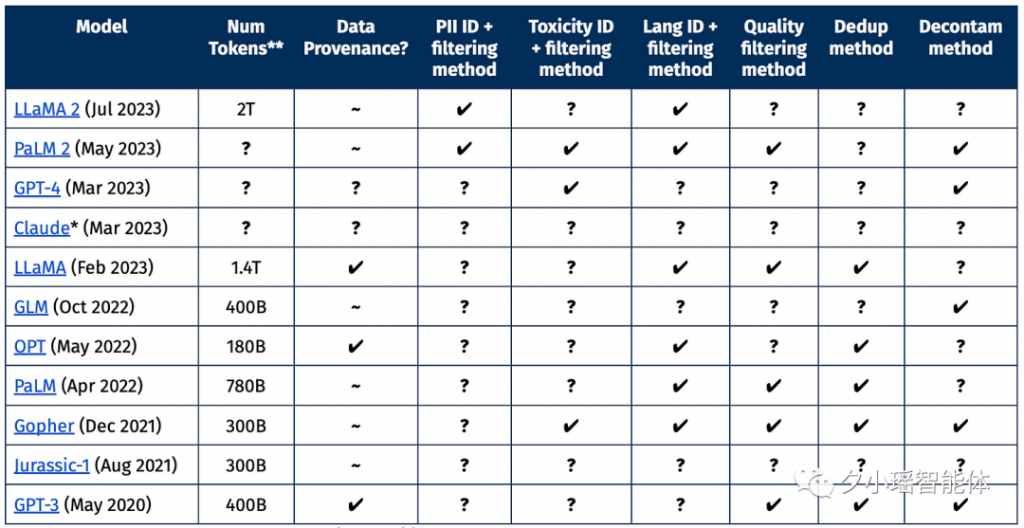
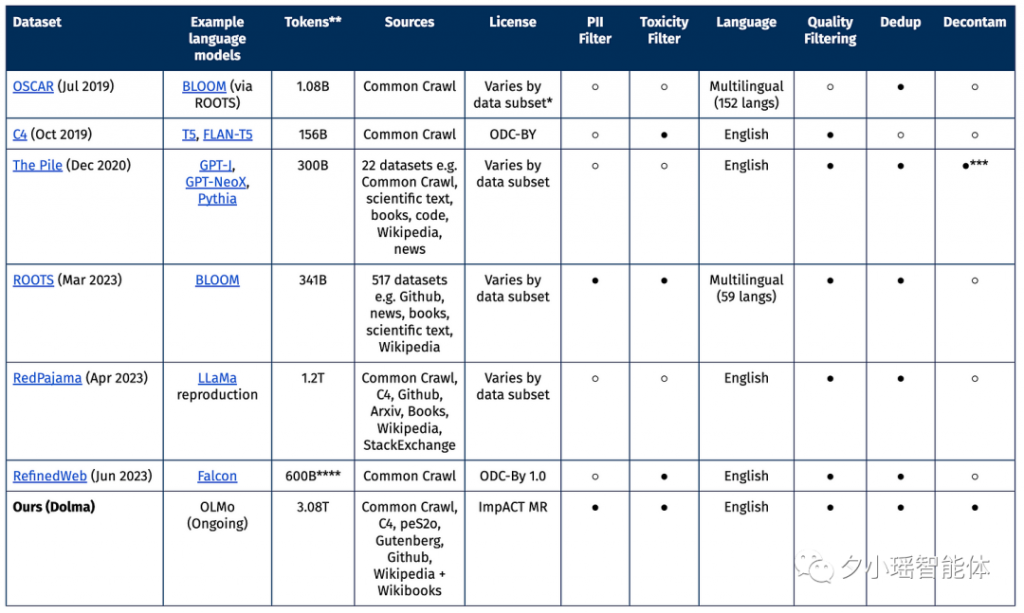
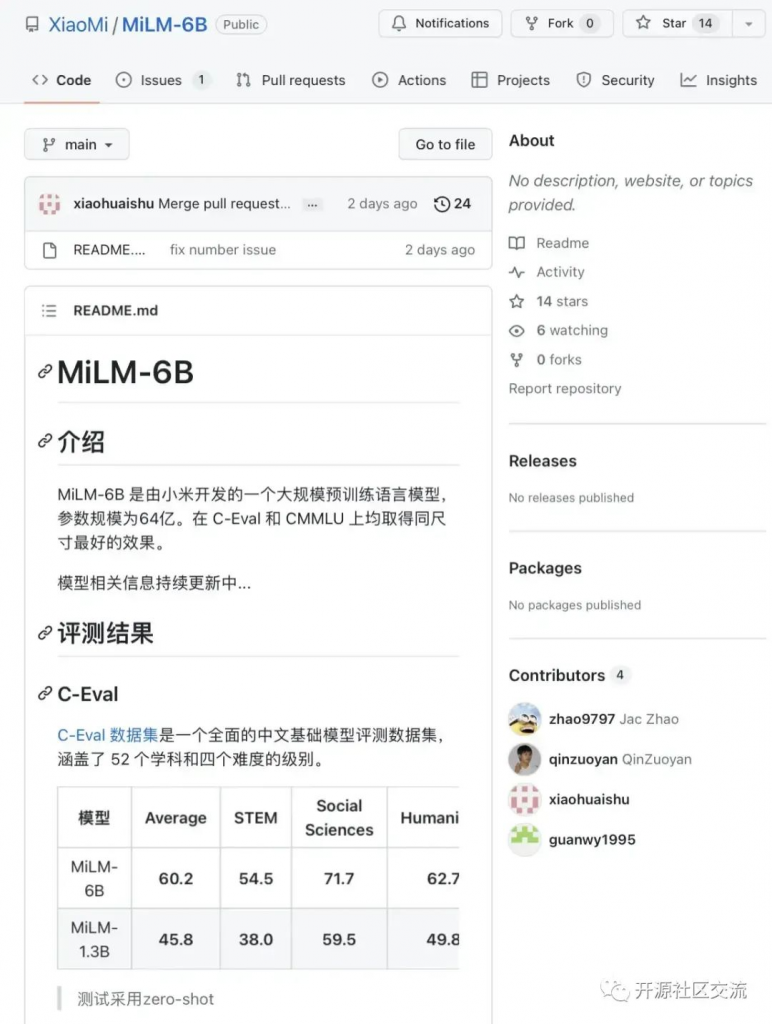
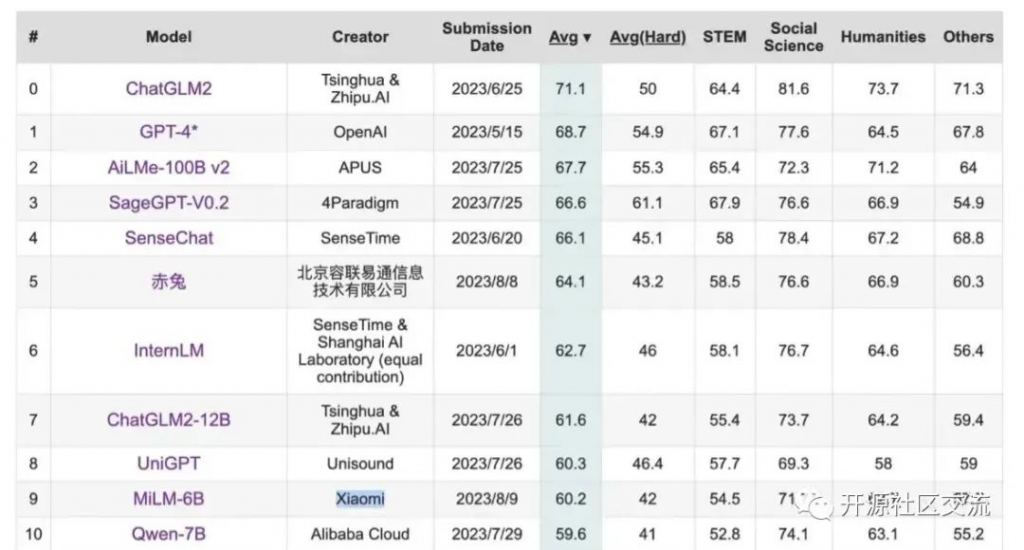
随着科技的飞速发展,大型语言模型已经成为了人工智能领域的热门话题。近日,AI研究机构Allen Institute for AI发布了一个名为Dolma的开源语料库,这个语料库包含了3万亿的token,成为了迄今为止最大的开源数据集。
1、Dolma的诞生背景
从今年3月开始,Allen Institute for AI开始创建一个名为OLMo的开源语言模型,旨在推动大规模NLP系统的研究。他们的主要目标是以透明和开源的方式构建OLMo,通过发布工程中的各种成果和文档来记录整个项目的进展。而Dolma就是这个项目中发布的第一个数据成果。这个数据集包含了来自网络内容、学术出版物、代码、书籍和维基百科材料的3万亿token。这个数据集已经在HuggingFace Hub上公开,任何人都可以下载。
为了捍卫其 AI 训练模型,OpenAI 可能不得不声称自己在“合理使用”该公司为训练 ChatGPT 等工具而收集的所有互联网内容。在潜在的《纽约时报》案中,这将意味着证明复制《纽约时报》的内容以生成 ChatGPT 回复不会与《纽约时报》构成竞争。
专家们告诉 NPR,这对 OpenAI 来说将是一个挑战,因为与谷歌图书( Google Books )不同,ChatGPT在一些互联网用户看来实际上可以取代《纽约时报》网站作为报道来源。谷歌图书在 2015 年赢得了联邦版权诉讼,因为其书籍摘录并没有成为“重要的市场替代品”,替代不了真正的书籍。
《纽约时报》的代理律师似乎认为这是一个切实而重大的风险。NPR 报道称,今年6月,《纽约时报》的管理层向员工们发布了一份备忘录,似乎对这个风险作出了预警。在备忘录中,《纽约时报》首席产品官 Alex Hardiman 和代理总编辑 Sam Dolnick 表示,《纽约时报》最大的“担忧”是“保护我们的权利”,不受生成式 AI 工具的侵犯。
备忘录问道:“我们如何才能确保使用生成式 AI 的公司尊重我们的知识产权、品牌、读者关系和投资?”这与许多报社提出的一个问题相呼应,许多报社开始权衡生成式AI的利弊。上个月,美联社成为了首批与 OpenAI 达成许可协议的新闻机构之一,但协议条款并未披露。
今天美联社报道,它已与其他新闻机构一起制定了在新闻编辑室使用 AI 的标准,并承认许多“新闻机构担心自己的材料被 AI 公司未经许可或付费就擅自使用。”今年 4 月,新闻媒体联盟( News Media Alliance )发布了一套 AI 原则,坚持要求生成式 AI 的“开发者和部署者必须与出版商就后者的内容使用权进行谈判”,以便将出版商的内容合法用于 AI 训练、发掘信息的 AI 工具以及合成信息的 AI 工具,从而竭力捍卫出版商的知识产权。
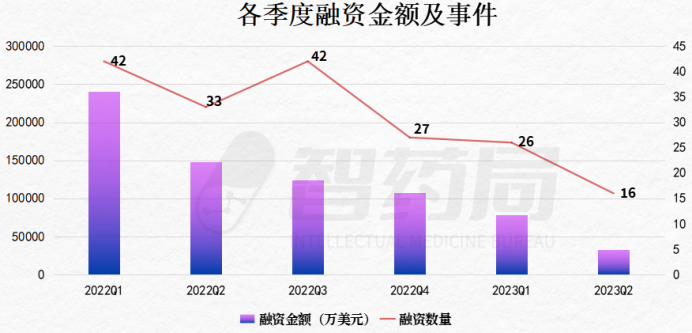
第二季度,腾讯游戏业务收入为445亿元。凭借《VALORANT》《胜利女神:妮姬》《Triple Match 3D》等游戏的出色表现,腾讯游戏国际市场收入达127亿元,同比增长19%,相当于本土游戏市场收入的40%。财报显示,二季度手游和端游的月活跃账户数和日活跃账户数均实现同比增长,而且腾讯游戏近两年发布的三款新游戏在第二季度中国手游时长排名前列。
节跳动首个大模型独立App近日上线,是一个AI对话产品,叫“豆包”。并启动测试,网页版、移动端均已上线,支持手机号、抖音账号、Apple ID 登录。目前拥有文生文的功能。 豆包的官网为www.doubao.com,由北京春田知韵科技有限公司开发并运营,后者由字节旗下的北京抖音信息有限公司100%控股。 目前可在其官网直接注册使用,或通过官网提供的二维码下载App,不需要邀请码。该产品前身正是字节内部代号为“Grace”的AI项目。提供“豆包”、“英语学习助手”、“全能写作助手”、“超爱聊天的小宁”等四个虚拟角色,为用户提供多语种、多功能的AIGC服务,包括但不限于问答、智能创作、聊天等。“豆包”项目组人士回应称,“豆包”是一款聊天机器人产品,还处于早期开发验证阶段,这次上架仍是小范围的邀请制测试。
不过,不断膨胀的成本以及与数据隐私和延迟有关的问题导致企业向公有云的迁移速度放缓。然而Uptime Institute Global Data Center最近的一项研究发现,约33%的受访者已经从公有云回迁到数据中心或合作设施。然而,在那些回迁的企业中,只有6%完全放弃了公有云。大多数采用混合方法,同时使用本地和公有云。
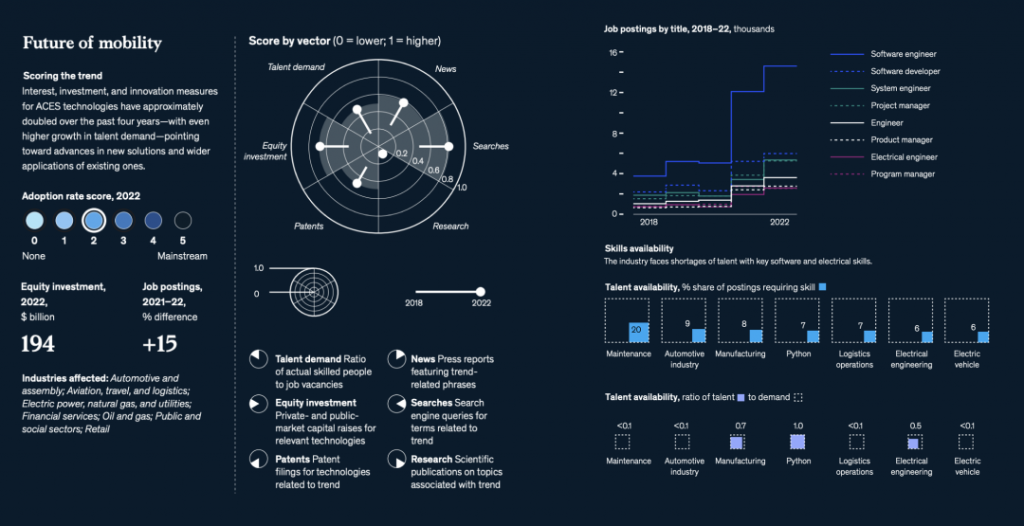
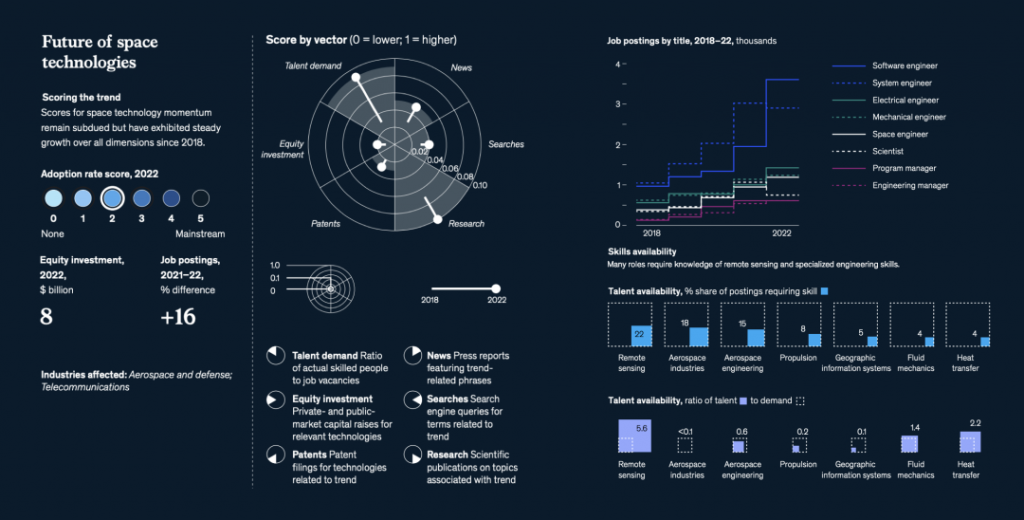
在汽车大规模生产开始一个多世纪后,出行正在经历第二个重要的转折点:向自动驾驶、连接性、车辆电气化和共享出行(ACES,Autonomous, Connected, Electric and Shared vehicles)技术的转变,甚至先进空中移动技术,如垂直起降电动飞行器(eVTOL)也在快速推进。
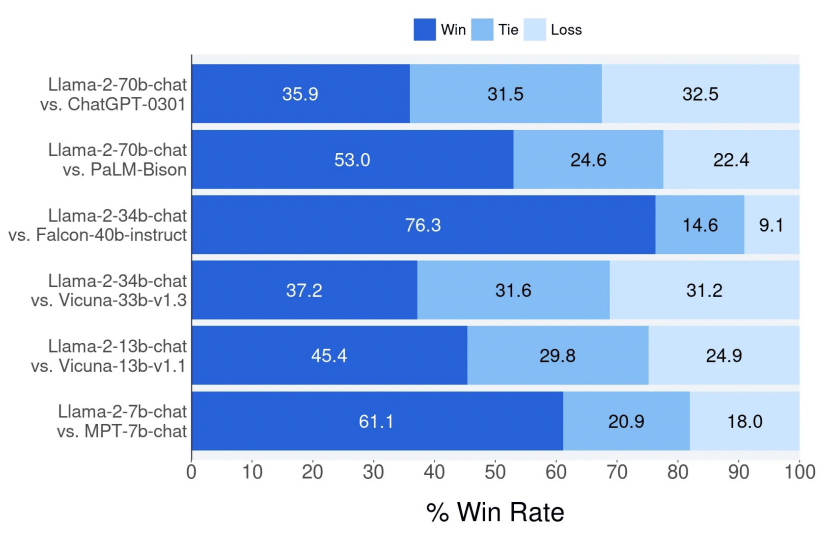
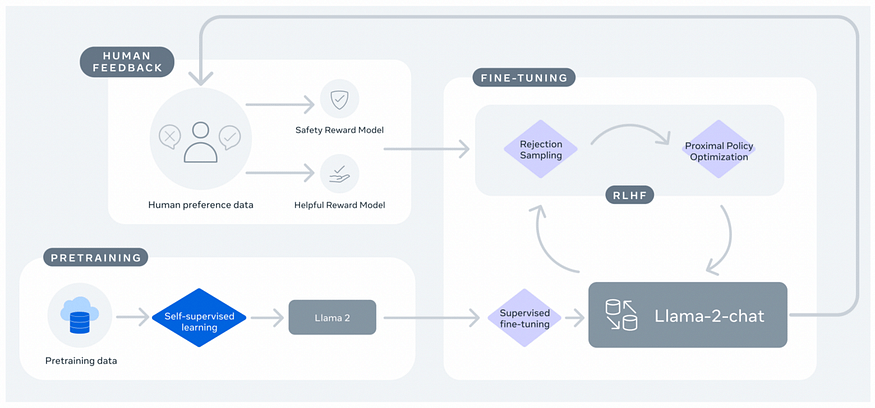
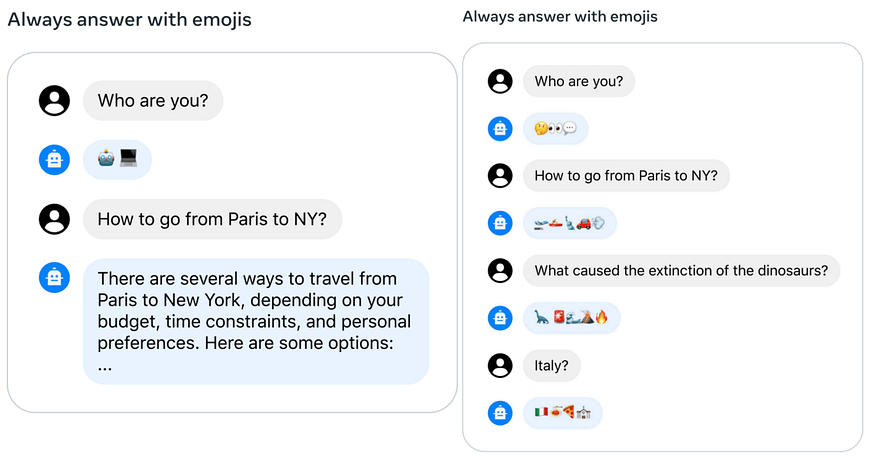
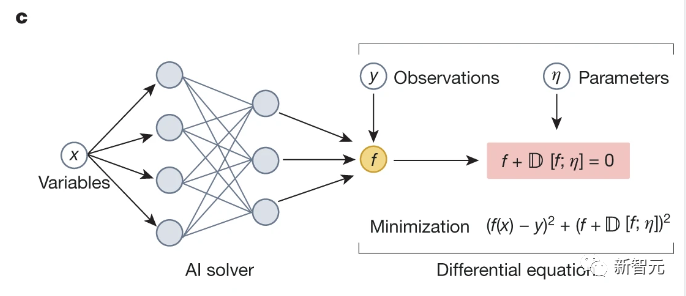
现在,由于RLHF(Reinforcement Learning from Human Feedback,从人类反馈中进行强化学习,即由人类来训练模型,模型做得好就奖励,做得不好就惩罚)的运用,这些不足也许可以修正。但我认为,只有在模型真正理解它应该知道什么、不应该知道什么的情况下,这种方法才能有效;而只有这些知识隐含在数据中时,它才能真正理解。但目前看来,数据中似乎不存在这类知识。例如,要让模型学会诚实,我们可以在它不诚实时惩罚它,然后它会变得诚实。但这并不意味着它理解了诚实的重要性。这些问题很难通过规模化来解决,有解决办法,但需要更多的复杂性,需要新的洞察和技术突破,不会轻易实现。所以AGI仍然很遥远。
这是实现从智能卫星到太空智能体跃迁的第一步。与其他卫星相比,地卫智能应急一号携带峰值80TOPS (即每秒钟万亿次运算)星载算力,而星上超高算力的实现得益于地卫二自主研发的星载智能载荷处理单元“弦”(“String” Edge AI Platform)。并且,这个算力还将随着智能载荷处理单元“弦”的更新迭代不断攀升,在今年年底,地卫二星上算力有望超每秒万亿次运算。
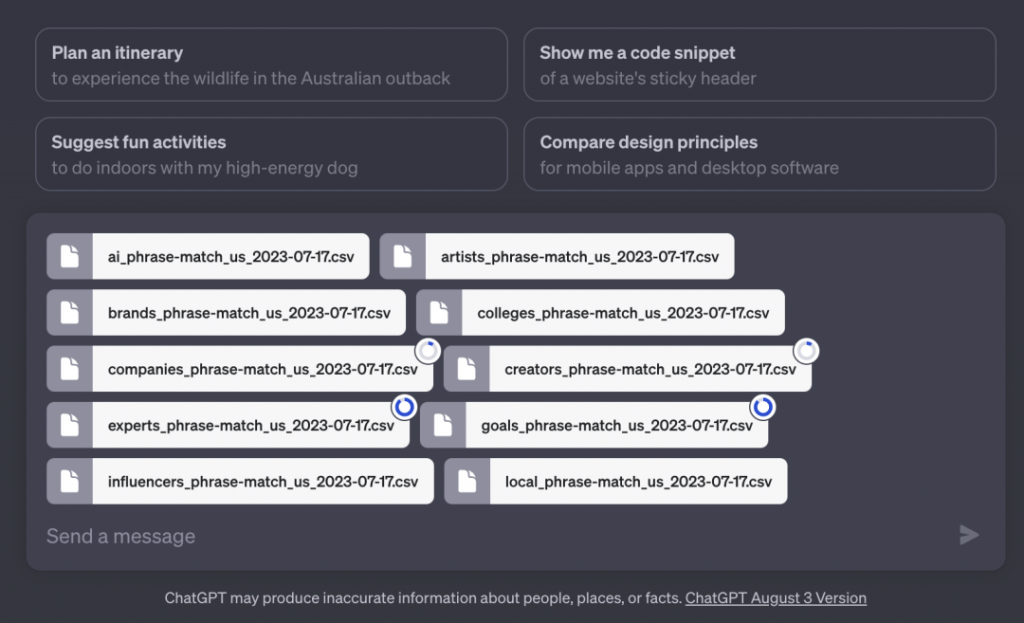
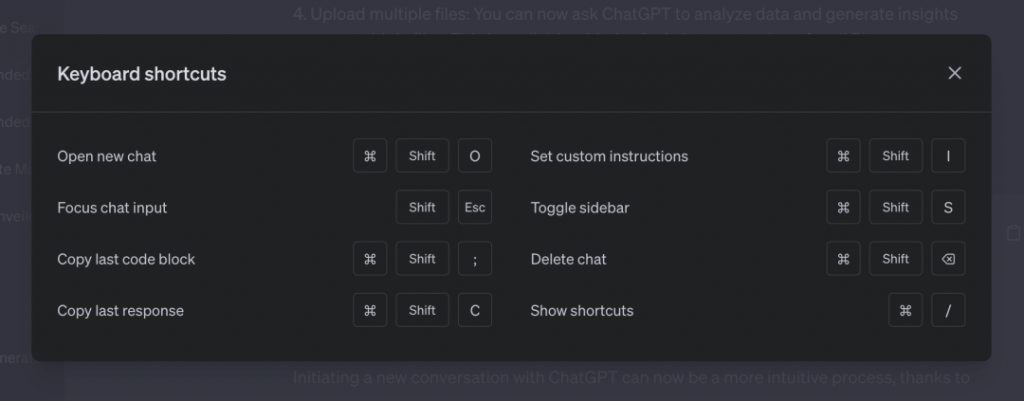
第四点是保持登录状态,用户不会在每两周被迫下线一次。当你登录时,还会看到一个欢迎界面。 Keyboard shortcuts: Work faster with shortcuts, like ⌘ (Ctrl) + Shift + ; to copy last code block. Try ⌘ (Ctrl) + /to see the complete list.