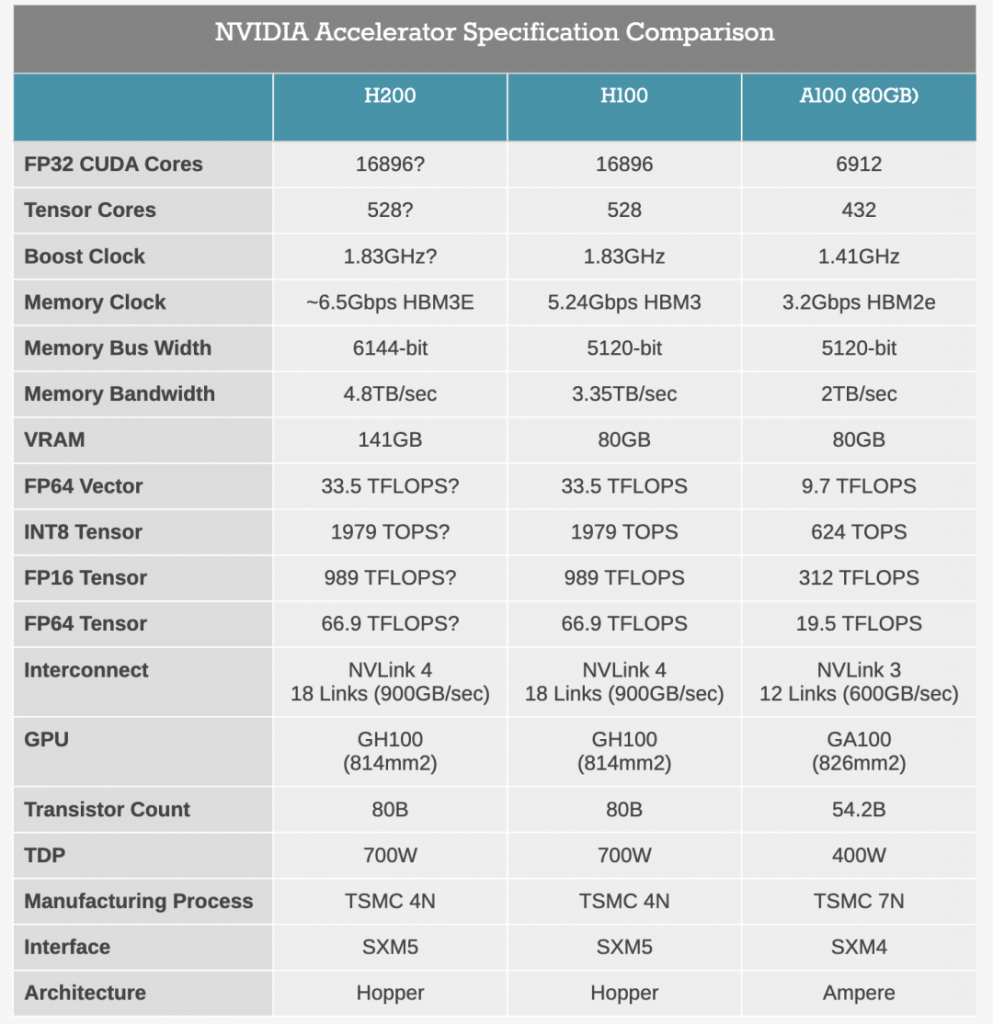
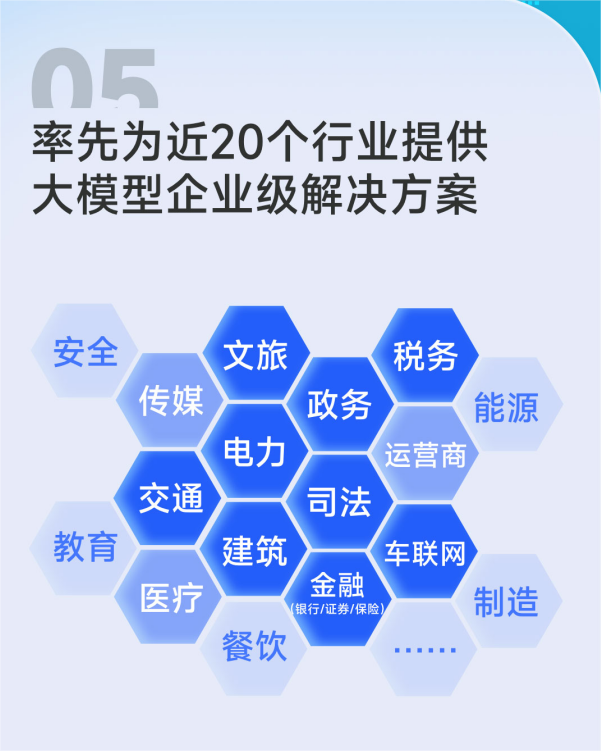
IETF的具体工作领域“above the wire and bellow the application”,即在线路(计算机网络中的通信基础设施,通常包括网络电缆、光纤、无线连接等物理传输媒介)之上,应用之下,意味着其有特定职责,并非包罗万象。IETF包括若干工作组,涵盖网络、路由、传输和应用等各种领域,同时还有一些跨层的通用工作组,涉足运行、安全和一般管理等多领域。
据列日大学网站11月13日消息,比利时列日大学(University of Liege)的研究人员开发出一种新的聚氨酯生产技术,可利用二氧化碳(CO2)来制造新型易于回收的塑料。研究人员将原材料放入充满CO2的加压反应器中,再将转化的CO2基化合物纯化后制备出单体以制造聚合物,生成的粉末状聚合物可以在模具中成形或与天然纤维一起压制生产复合材料。由于该塑料的化学结构类似于3D网络,在相对温和的反应条件下可通过化学键交换实现重塑,因此该塑料比长分子链制成的塑料更耐用,且可以通过多种方式回收利用。该技术可成为开发可持续塑料的潜在解决方案。相关研究成果发表在《美国化学会志》上。
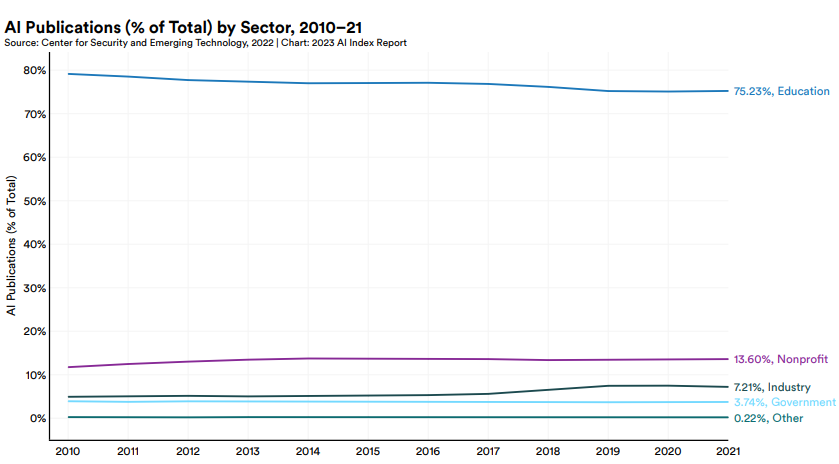
在第一章“研究与发展”中,本报告指出,当下人工智能领域内工业界呈现出领先于学术界的发展态势(industry races ahead of academia)。截至2014年,大部分重要的机器学习模型都是由学术界研创并发布的,然而自那年之后,工业界开始接手机器学习模型的制造。截至2022年,由工业界生产的机器学习模型数量高达32个,而学术界则只研发了3个。究其原因,这种现象的产生是因为构建先进的AI系统对于海量数据、计算机能力及资金支持的需求日益增大,与非营利组织和学术界相较,工业界天生具备这些优势。
在第二章“技术性能”中,本报告指出,传统基准上的性能趋于饱和(performance saturation on traditional benchmarks)。近年来,AI领域内持续产出了不少先进的成果,然而仍有很多基准的年同比改进微乎其微;除此以外,传统基准达到饱和的速度正在加快,不过,BIG-bench和HELM等崭新的、更全面的基准套件正处于发布过程中。
人工智能对环境&科学的影响
在第二章节中,本报告还指出,人工智能利弊共存,既能保护环境、促进科学进步,但也有可能损害环境(AI is both helping and harming the environment; AI is the world’s new scientist)。新的研究显示,人工智能系统可能会对人类所处的生态环境产生恶劣的影响,根据专业人士的调研,2022年BLOOM的训练运行排放的碳元素比一位从纽约到旧金山的单程航空旅客多出25倍。尽管如此,BCOOLER等新的强化学习模型表明,人工智能系统可以用于提高能源使用的效率;此外,人工智能模型也正迅速地推动科学的发展,并于2022年被使用于辅助氢聚变、提高矩阵操作效率、生成新抗体。
滥用人工智能事件数量正在迅速上升
在第三章“技术AI伦理”中,本报告指出,滥用人工智能的事件数量正逐步攀升(the number of incidents concerning the misuse of AI is rapidly rising)。根据专门追踪人工智能伦理相关事件的AIAAIC数据库提供的资料显示,自2012年以来,人工智能相关事件及争议量已增加了26倍。2022年,不少引人注目的国际事件印证了人工智能技术使用量的增长,也表明人们已经逐渐意识到了人工智能滥用的可能性。 人工智能专业技能需求增加
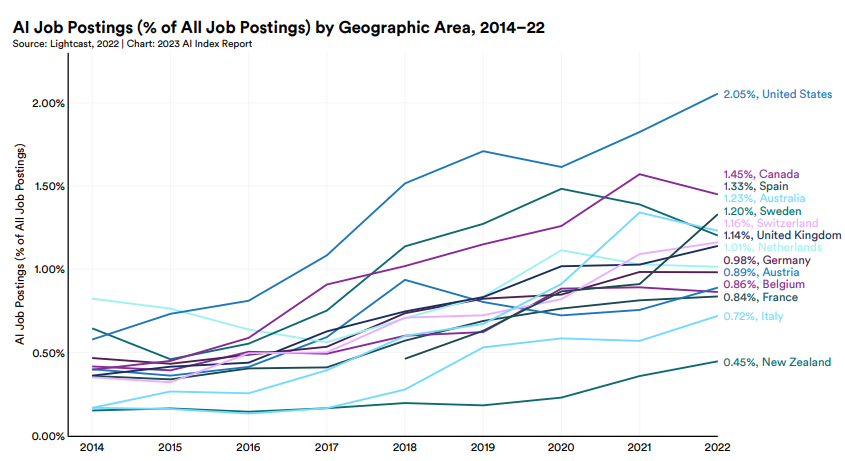
在第四章“经济”中,本报告指出,许多工业部门对于人工智能相关专业技能的需求都在不断地增加(the demand for AI-related professional skills is increasing)。在美国,需要使用数据的每一个部门(农业、林业、渔业和狩猎除外),人工智能相关的岗位招聘数量每年逐步增加,雇主们越来越倾向于寻找具备人工智能相关技能的员工。
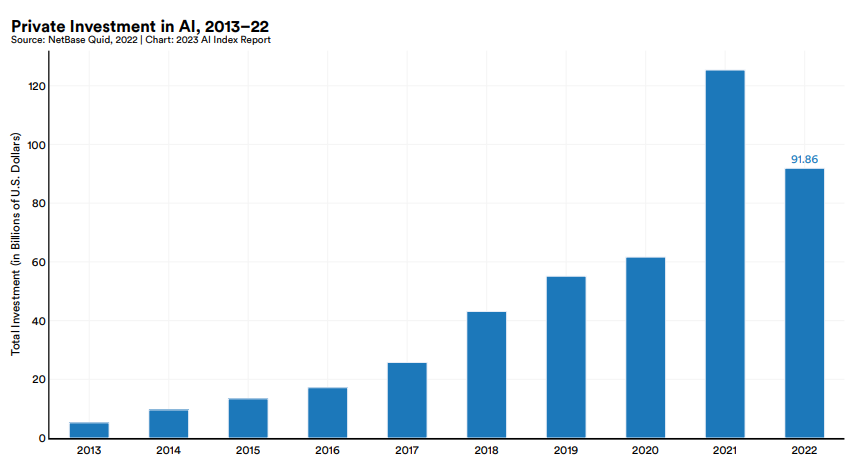
人工智能私人投资首次出现同比下降&助力企业增收
同时,人工智能在经济层面的另一个发展态势是,在过去的十年中,私人对人工智能的投资首次呈逐年减少的趋势(year-over-year private investment in AI is decreasing)。2022年,全球人工智能私人投资额为919亿美元,与2021年的水平相较下降26.7%。
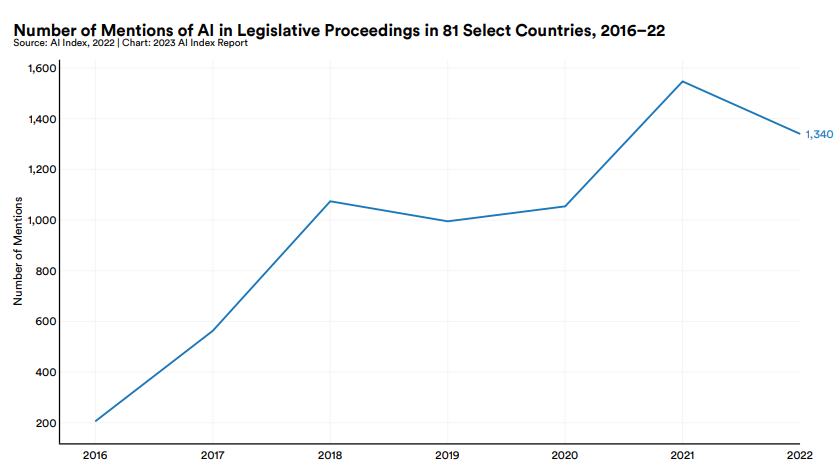
在第八章“政策与治理”中,本报告指出,政策制定者愈发重视对于人工智能的研究(policymaker interest in AI is on the rise)。针对127个国家立法记录的人工智能指数分析显示,与人工智能密切相关的法案正式获准成为法律的案例数量从2016年的1个快速增加至2022年的37个;关于81个国家人工智能会议记录的调查同样表明,近年来,人工智能在全球立法进程中出现的频率较高,已经增加了约6.5倍。
在第八章“舆论”中,本报告指出,中国公民是对人工智能产品及服务感受最为积极的群体之一(Chinese citizens are among those who feel the most positively about AI products and services)。在2022年的益普索调查中,约有78%的中国受访者赞同使用人工智能的产品及服务“利大于弊”,这一比例在所有受调查国家中位居最高;然而,美国受访者认同人工智能使用利大于弊这一观点的人数在所有受调查人群中仅占35%。报告认为,大部分美国受访者之所以认为人工智能弊大于利,主要原因有他们担心人工智能带来的失业问题(19%);监视风险、黑客攻击和数字隐私风险(16%);以及人工智能带来的人际关系缺失(12%)。 其他要点
新加坡国立大学政治学教授 Chong Ja Ian 表示,人工智能是各国在制定法规方面有共同利益的领域,与气候问题和跨国犯罪类似,人工智能可能是美国和中国必须合作的领域。因为中美人工智能合作符合两国利益,合作有助于防止新兴技术滥用和失控。北京人民大学国际关系学院教授王义桅表示,虽然中美将继续进行战略竞争,但它们共同面对着人工智能等人类共同的挑战,并建议中美交换意见,共同制定全球规则和标准。
11月2日,人工智能巨头同意与政府合作,在新的前沿人工智能模型发布之前对其进行测试,以监管技术快速发展的风险。英国首相苏纳克在AI安全峰会上表示,美国、欧盟与其他“志同道合”的国家已经与一些从事人工智能前沿研究的公司达成一项里程碑式的协议,根据该协议,科技巨头在部署前沿模型前后都要进行严格的评估和测试。被誉为人工智能教父的Yoshua Bengio将提交一份“科学现状(State of the Science)”的报告,帮助各国增进对未来能力和风险的理解。
当地时间 10 月 26 日美股盘后,英特尔公布了三季度财报。 虽然英特尔的营收和调整后的每股收益,都远高于预期,但从财务指标来看,英特尔在报告期内的表现较去年同期相比表现不佳,主营业务的收入也出现下降。对此,英特尔也坦言,「PC 处理器的整体市场规模正在不断缩小,公司在本季面临着强大的竞争压力。」但更可怕的是,英特尔的竞争对手们,都在向其腹地——CPU 处理器市场展开猛攻。根据消息,英伟达、AMD 正在悄悄研发基于 Arm 架构的 CPU 芯片、苹果公司连夜发布了 M3 系列芯片、高通更是不甘落后,推出了骁龙 X Elite PC 处理器,搭载的全新 Oryon CPU 号称在单线程上吊打 i9-13980HX。
此外,微软、荣耀、联想、戴尔和惠普等科技巨头,也都宣布将于明年推出搭载 Arm 架构芯片的电脑。为什么明明 AI 处理器看起来是更有潜力的市场,但是所有芯片巨头却都要杀进 PC CPU 这个看似已经是「夕阳行业」的市场?
01
科技巨头「抢滩」CPU 长期以来,PC 芯片主要有两大阵营,分别是 x86 架构和 Arm 架构。前者主要由英特尔和 AMD 两家公司主导,后者则是苹果的天下。但最近,芯片领域出现了不少「混战。」不久前,相继有新闻称,英伟达和 AMD 正在微软的助力下,利用 Arm 架构开发 Windows 操作系统的 PC CPU 芯片,最快可能在 2025 年就向市场推出,直接对标打击英特尔基于 x86 架构的 CPU 基本盘。该消息释出后,英特尔的股价随即下跌。
另一边,英伟达股价收盘上涨 3.84%,AMD 股价收盘上涨 4.89%。虽然有关英伟达打算造芯片的消息尚未得到证实,但据报道,这家已经在 AI、高性能计算和消费显卡行业占据主导地位的公司,确实计划将基于 Arm 的处理器纳入客户端 Windows PC,以扩大其产品组合。事实上,多年以来,不止英伟达、AMD,许多公司都曾尝试进军 PC 处理器领域,但均未能撼动英特尔的「霸主」地位,可能只有苹果公司对英特尔真正构成了一定的「威胁」。
三年前,苹果「抛弃」了使用长达 15 年的英特尔芯片,自主研发了以 Arm 为基础的 M1 芯片,一举打破了英特尔的 PC「垄断」局面。而且,苹果的自研芯片,更是为 Mac 电脑系列提供了更长的电池寿命和更快的性能,远超英特尔处理器。因此,也就不难理解,自苹果为其 Mac 电脑发布自研 M1 芯片以来,苹果的市场份额在三年内几乎翻了一番。对此,英特尔首席执行官 Pat Gelsinger 在英特尔敲响了「警钟」,他在员工大会上毫不避讳地提到了苹果当时新推出的 M1 芯片,并表示,「未来,我们必须做到这么好。」
两周前,苹果又在「来势迅猛 (Scary Fast)」主题发布会上,正式发布了最新的 M3 系列芯片,包括 M3、M3 Pro 和 M3 Max 三款芯片,还同时发布了搭载 M3 系列芯片的新款 MacBook Pro 和新款 iMac,苹果还称其速度将是搭载 M1 芯片的 24 寸 iMac 的两倍。
此外,半导体巨头高通,也在加紧进军 PC 芯片市场,试图和英特尔、苹果抢夺市场份额。前不久的骁龙峰会期间,高通发布了适用于 Windows 笔记本电脑、基于 Arm 架构的骁龙 X Elite 芯片,这款芯片在游戏方面,优于英特尔的 i9,以及苹果基于 Arm 架构的高端自研芯片 M2,还能用于 AI 操作,处理多达 130 亿参数的大语言模型。
高通首席执行官 Cristiano Amon 还表示,未来笔记本电脑处理器将逐渐转入 Arm 架构,这也是对英特尔 X86 架构「垄断」地位的直接「宣战。」此外,微软、荣耀、联想、戴尔和惠普等「科技巨头」也加入了「混战」,宣布在明年推出搭载 Arm 架构芯片的电脑。虽然,到目前为止,只有苹果公司的专有设计取得了「实质性」进展——在行业出货量中所占的份额已超过 10%,但正如美股研投网站 The Motley Fool 所言,「如果这些新的 Arm 架构芯片取得成功,即使是中等程度的成功,对英特尔来说也将是毁灭性的打击。」
而对于多家「对手」发起的「CPU 混战」,英特尔首席执行官 Pat Gelsinger 则呼吁市场保持「冷静。」他认为,「从历史上来看,ARM 的芯片在市场上并没有获得过多大关注。虽然在过去几个季度,在 CPU 和加速器领域,市场份额已经发生了一些变化,但是,进入第四季度,市场迹象已经逐步正常化。」他还表示,「就目前而言,无论是 ARM 也好,还是 Windows 客户端的替代产品,在 PC 行业中,它们都已经被降级为了相当微不足道的角色。
从战略上来看,英特尔将认真对待所有竞争。但是,从战术上来看,我们认为这些挑战并没有那么重要。」Gelsinger 还透露,英特尔制定了一项名为「四年五个节点」的计划,旨在改进芯片制造工艺,从而「抗衡」竞争对手。该计划主要包括在位于爱尔兰莱克斯利普的 Fab 34 工厂,使用 EUV 极紫外光刻(市场上最先进的半导体制造技术)大规模生产芯片,而且在本季度已经取得进展,还有望在 2025 年赶上台积电的芯片制造技术。
Arm,能挑战 x86 吗? 其实,Arm PC 并不是什么新生威胁,从上世纪开始,Arm 与 x86 的竞争就开始了。 1978 年,英特尔 x86 架构,伴随着 8086 处理器问世,x86 架构也逐渐成为个人电脑 CPU 的代名词,更为英特尔开创出了一个庞大的「商业帝国。」由于种种历史原因,AMD 成为了唯一获得英特尔授权可以生产 x86 架构芯片的公司,这也造就了这两家公司长时间内在 PC 芯片行业的「主导」地位。
到了 80 年代,英国公司 Acorn(Arm 公司的前身)设计出了与 x86 相比,更低功耗 Arm 架构的芯片,并尝试在 PC 端运行,但那时难以对抗 x86 架构的「霸主」地位。但是,直到智能手机的兴起,Arm 架构才找到了它的「舒适区」。
此后很长时间内,x86 被普遍认为适用于 PC 和服务器,而 Arm 架构则更适合移动设备,两者「和平共处」。直到苹果公司自主研发了以 Arm 为基础的 M1 芯片,才打破了这种「平衡。」有趣的是,微软高管也注意到了苹果基于 Arm 的芯片的处理效率,并希望获得类似的性能。而且,微软似乎也相信,Arm PC 在未来将占据相当大的市场份额,上个月,还宣布推出了「面向开发人员的 Arm 咨询服务」。
其实,早在 2016 年,微软就委托高通公司,牵头将 Windows 操作系统,转移到 Arm 的底层处理器架构上。在那之后,高通就获得了「独家」为 Windows 笔记本电脑生产芯片的权利。但高通与微软关于 Windows 芯片设计的「排他性」协议将在 2024 年到期,而微软似乎鼓励其他公司进入基于 Arm 的系统市场。
其实,微软的想法一直都很「简单」:不想依赖某一个单一的芯片供应商,高通如此,更早之前的英特尔也是如此。对此,金融与战略咨询公司 D2D Advisory 的首席执行官 Jay Goldberg 表示,「微软吸取了上世纪 90 年代的经验,他们不想再次依赖英特尔了,不想再依赖任何单一的供应商。」「如果 Arm 真的在 PC 芯片领域获得成功,他们绝不会让高通成为唯一的供应商。」而对微软来说,Arm 芯片制造商必须面对的一个障碍是 Windows 的软件兼容性。这是因为,软件开发人员花费了数十年时间和数十亿美元,专门为 Windows 编写代码,因此,传统的 x86 应用程序必须经过模拟,才能在 Arm 上运行,这就导致在原生版本推出之前,应用性能会受到影响。
苹果公司在转用自研芯片时也面临着同样的挑战。然而,X86 长期统治 PC 市场,已经形成了丰富的软件生态,使用 x86 芯片的电脑基本不会遇到兼容性问题。对此,技术研究公司 Counterpoint Research 高级分析师 William Li 认为,「过去 20 年 PC 行业在软件和应用上的开发都以 x86 架构为主,调整到 Arm 架构上会涉及到适配和转译的问题。因此过去虽然有基于 Arm 开发的 PC 芯片,但一直不温不火。」的确,2022 年全球 PC 电脑总出货的 80% 以上仍是 X86 架构的 CPU,尽管如此,市场研究机构 Counterpoint 仍预测,
「随着更多芯片厂商推出 Arm 架构的 PC 芯片,Arm 架构的市场份额有望上升」「到 2027 年,Arm 架构芯片在 PC 市场的份额预计为 25.3%,较 2022 年增长近一倍。」未来,Arm 能在多大程度上挑战 x86 的统治地位,或许还要取决于其他芯片厂商对 Arm 架构的支持程度。
AI,所有人的新希望? 现在,一场新的「竞赛」又拉开帷幕——随着 AI 大模型的发展,科芯片巨头纷纷开始陆续布局 PC 端 AI 芯片。 这是因为,微软和大部分科技企业,都将其未来押注于在 AI 相关技术上,但随着需求激增,芯片售价高达数万美元,于是亚马逊、谷歌、Meta、微软、特斯拉等公司,就开始打造自己的 ASIC 芯片来实现其 AI 目标。
与 GPU 不同,ASIC 专为特定任务(如 AI 处理)而设计。虽然它们的开发成本很高,但从长远来看,它可以降低功耗,让公司能够更好地控制用于为 AI 软件提供动力的硬件,从而带来收益。对此,业内人士认为,「部署 AI 功能的 PC 操作系统,将带来全新交互模式,或将激发新的市场需求,同时生成式 AI 也为软件及操作系统应用,开启创新空间。」
目前,英伟达虽然在 AI 芯片市场仍占据主导地位,但它的领先地位现在已经受到挑战。据 The Information 报道,微软自 2019 年以来一直在开发自己的 AI 芯片,并一直鼓励相关芯片制造商,在他们正在设计的 CPU 中内置先进的 AI 功能。
预计,随着智能办公助手 Copilot 等 AI 增强软件,在 Windows 使用中的重要性越来越大,Nvidia、AMD 和其他公司即将推出的芯片将需要投入更多资源以实现这一目标。今年 5 月份,Meta 也宣布正在开发自己的 AI 硬件。
8 月,谷歌首次发布了其最新的 AI 基础设施,与此同时,特斯拉也在打造基于自己芯片的超级计算机。近日,PC 龙头联想也发布了首款 AI PC,其执行副总裁 Luca Rossi 还在发布会上表示,「得益于基于个人体验的定制化升级,AI PC 将和传统 PC 将存在明显的分水岭。」「作为上游最重要的产业链伙伴,芯片厂商肯定要跟上潮流,甚至走在 PC 厂商前面。」英特尔公司首席执行官 Pat Gelsinger 也同样认为「AI 个人电脑的到来代表着个人电脑行业的一个拐点」。
这些科技巨头的行为和观点,也与 Canalys 等研究机构的数据「不谋而合」。数据显示,「从 2025 年起,支持 AI 的个人电脑的采用速度将加快,到 2027 年将占个人电脑总出货量的 60% 左右。」另一方面,英特尔也没有「坐以待毙」,也在 AI+CPU 这条道路上积极布局。近期,英特尔宣布与联想「合作」,将 AI 带给所有人,并表示「AI 将从根本上改变、重塑 PC 体验。」「英特尔正为新时代的到来布局,将推出代号 Meteor Lake 的英特尔酷睿 Ultra 处理器。这是英特尔首款内置神经网络处理器(NPU),能为 PC 带来高能效的 AI 加速和本地推理体验。」
「计划今年 12 月 14 日发布首款第五代英特尔至强处理器和酷睿 Ultra 处理器,在客户端、边缘、网络和云端的所有工作负载上携手推进 AI 的规模化应用。」在短暂的和平之后,芯片巨头们又进入到「战国」时期,而一直被认为逐渐走低的 PC CPU 市场,重新热闹起来。而在 CPU 之战背后,正在快速推进的 AI 技术的落地,其实才是巨头们瞄准的「暗标」。
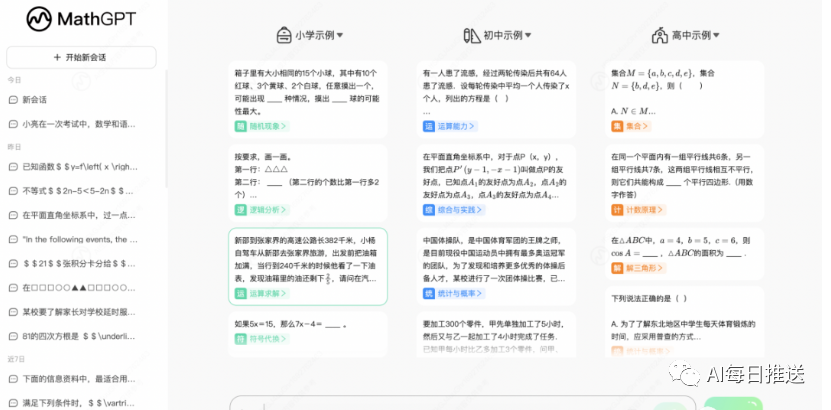
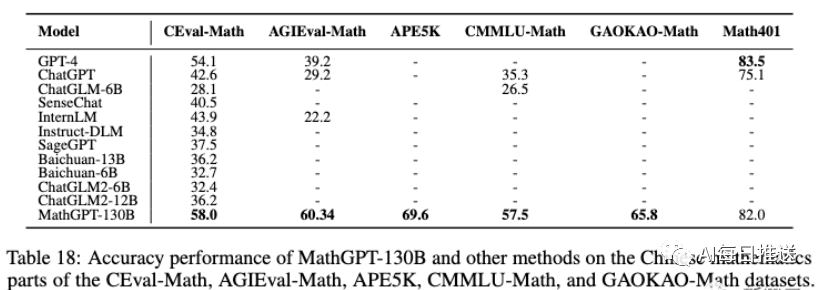
CG-Eval是一个由甲骨易AI研究院与LanguageX AI Lab联合发布的针对中文大模型生成能力的评测基准。包含了科技与工程、人文与社会科学、数学计算、医师资格考试、司法考试、注册会计师考试等六个大科目类别下的55个子科目的11000道不同类型问题。CG-Eval包含一套复合的打分系统:对于非计算题,每一道名词解释题和简答题都有标准参考答案,采用多个标准打分然后加权求和;对于计算题目,会提取最终计算结果和解题过程,然后综合打分。 CBLUE [paper]
Yongxin Shi Transcript English Version: “Zen Buddhism Encounters AI” Respected guests and friends:Greetings to all! Today, I am truly honored to share the topic “Zen Buddhism Encounters AI” with all of you. With the continuous advancement of artificial intelligence technology, it is gradually permeating every area of our lives. At the same time, the widespread adoption of this technology has significantly impacted traditional beliefs. When the ancient Eastern Zen thought encounters the cutting-edge AI technology of the 21st century, the intersection of humanities and technology is bound to offer new insights for people today. Buddhism has a development history spanning over 2,500 years. Zen Buddhism is the most influential, widely spread, and mature school within Chinese Buddhism. Its core philosophy can be summarized as “not reliant on scriptures, teachings passed beyond words, directly pointing to the human heart, and achieving enlightenment upon recognizing one’s nature.” Zen seeks spiritual awakening. It inherits and innovates upon the teachings of the Buddha and integrates with traditional Chinese Confucian and Taoist philosophies. Its practice primarily emphasizes genuine cultivation and validation, unbounded by any knowledge, logic, thinking, or even consciousness, and is a manifestation of enlightenment wisdom. Zen thought profoundly influences Chinese philosophy, literature, and art, actively contributing to societal service, purifying the heart, and enlightening the mind. The Shaolin Temple, founded in AD 495, is where the first Zen patriarch, Bodhidharma, founded Zen after meditating facing a wall for nine years. As the cradle of Zen Buddhism, the Shaolin Temple has been continuously passing down its teachings for over 1,500 years, with its core being Zen, and expressed in forms of health preservation, martial arts, medicine, and Zen arts. The health preservation methods of Shaolin primarily involve practicing qigong exercises like “Yijin Jing,” supplemented with vegetarianism, meditation, and sutra recitation to nurture the essence, energy, and spirit. Shaolin Kung Fu, one of China’s first intangible cultural heritages, is based on Buddhist beliefs and Zen wisdom. It possesses a complete theoretical system of combat techniques, consisting of grappling, fighting, bone-breaking, pressure point strikes, and various weapon techniques, all structured into a standardized system of progression. The ultimate realm of Shaolin martial arts is the unification of “Zen and Martial Arts.” Shaolin medicine derives from the Buddhist concept of “Understanding Medicinal Properties,” integrated with traditional Chinese medicine, advocating for healing the mind through Buddhist teachings and the body through herbal remedies. Shaolin Zen arts encompass painting, calligraphy, sculpture, chanting, tea ceremonies, and Go (the board game), serving as vehicles to promote Zen culture. Shaolin culture, through continuous inheritance and exchange, has been widely disseminated in regions like South Korea, Japan, and Southeast Asia. In recent decades, many enthusiasts of Shaolin culture have also emerged in European and American countries. The Shaolin Temple actively participates in international exchanges, making positive contributions to human health. Currently, there are Shaolin cultural exchange centers in over 200 regions across 150 countries worldwide. The Shaolin Temple has experienced highs and lows throughout its history, but its enduring legacy is due to the inner vitality of Shaolin culture. It emphasizes harmony between humans and nature, society, and oneself. Moreover, Shaolin culture plays a pivotal role in fostering international relations and promoting world peace. In the future, the temple will continue to propagate the universal Buddhist values of equality, compassion, purity, and integration, better serving humanity. So, what happens when Zen meets AI? Can technological progress replace moral and ethical advancement? AI possesses a tremendous capability for data processing and analysis, and through programming and algorithms, it might exhibit human-like perceptions. However, AI cannot possess the awakening and consciousness preached by Zen. In the face of AI, humans should maintain clarity of mind and seek inner enlightenment and transcendental wisdom, as advocated by Zen. Zen emphasizes that practitioners elevate their state of enlightenment through dedication and effort. In this process, they often encounter various confusions and troubles. AI, as a tool, can assist by searching relevant scriptures, thereby addressing doubts and providing support and convenience for practitioners. Technological advancement has granted people more leisure time. We hope that this won’t make the masses lax and indulgent. In the future, I wish for more interactions between Zen wisdom and AI, especially in the context of Shaolin culture. Together, they can build a platform for communication, allowing the public to immerse themselves in experiencing the culture of Shaolin’s Zen, martial arts, medicine, and arts. This will enable them to feel the unique charm of Shaolin culture more vividly, pursuing spiritual fulfillment and allowing Shaolin culture to better serve the physical and mental well-being of all humanity. In conclusion, I wish everyone all the best and happiness! Amitabha Buddha.
今天的人工智能ETF基金还远没有那么先进。BTD Capital 对股票采取“逢低买入”的策略。帕内尔表示,挑战在于“找出真正的“低”——一种本质上是人为导致的价格回调。因此,如果你买入,价格将从低位平均回升至高位,你将从价格小幅上涨中受益。”
问题在于,一些股票可能会因行业或公司的具体情况而下跌,但不会反弹。今年3月,硅谷银行(Silicon Valley Bank)破产,加州其它银行倒闭,就是这种情况。“区域性银行的崩溃是人工智能以前从未见过的模式,”帕内尔表示。这种缺乏理解的情况影响了ETF基金的表现,今年的业绩也不尽如人意。但是 ETF基金的人工智能现在已经“了解了这种模式是什么样的,”帕内尔说,所以它可以减轻未来的损失。
另一种更偏创意类0-1的视频生产,比如我们和某新消费雪糕品牌合作过一个风格化广告片,包含大量的视频特效,我们用的是video to video的形式去生成,整个广告片的质感和效果非常好,但制作周期只用了三四天。还有一块是我们文生商品视频技术,给到我们一个商品之后,我们可以通过AI结合3D建模把产品应用到不同场景、组成类似广告片的内容。
来自苏黎世大学机器人与感知研究组(Robotics and Perception Group)的 Elia Kaufmann 博士团队及其英特尔团队联合设计了一种自动驾驶系统——Swift,该系统驾驶无人机的能力可在一对一冠军赛中战胜人类对手。
这一重磅研究成果,刚刚以封面文章的形式发表在了最新一期的 Nature 杂志上。
图|最新一期 Nature 封面。(来源:Nature)
在一篇同期发表在 Nature 上的新闻与观点文章中,荷兰代尔夫特理工大学的研究院 Guido de Croon 教授写道,“Kaufmann 等人的研究是机器人学家克服现实差距的一个很好的案例。尽管 Swift 使用 AI 学习技术和传统工程算法的巧妙组合进行训练,但该系统应该在一个更真实多变的环境中进一步开发,从而充分释放这项技术的潜力。”
OpenAI公司的代表和作者没有立即回应置评请求。今年夏季早些时候,两个独立的作者团体对OpenAI公司提起了集体诉讼,指控它非法将他们的书籍纳入用于训练ChatGPT对人类文本提示做出反应的数据集中。喜剧演员Silverman的组织还对Meta Platforms提起了相关的诉讼。其他一些公司也对谷歌、微软和 Stability AI 等公司的人工智能训练提起了类似诉讼。
Human error and uncertainty are concepts that many artificial intelligence systems fail to grasp, particularly in systems where a human provides feedback to a machine learning model. Many of these systems are programmed to assume that humans are always certain and correct, but real-world decision-making includes occasional mistakes and uncertainty.
Researchers from the University of Cambridge, along with The Alan Turing Institute, Princeton, and Google DeepMind, have been attempting to bridge the gap between human behaviour and machine learning, so that uncertainty can be more fully accounted for in AI applications where humans and machines are working together. This could help reduce risk and improve trust and reliability of these applications, especially where safety is critical, such as medical diagnosis.
The team adapted a well-known image classification dataset so that humans could provide feedback and indicate their level of uncertainty when labelling a particular image. The researchers found that training with uncertain labels can improve these systems’ performance in handling uncertain feedback, although humans also cause the overall performance of these hybrid systems to drop.
该研究结果将发布于2023年人工智能、伦理和社会会议(AIES 2023),该会议由国际先进人工智能协会(AAAI)和美国计算机协会(ACM)联合举办,今年在蒙特利尔召开。 Their results will be reported at the AAAI/ACM Conference on Artificial Intelligence, Ethics and Society (AIES 2023) in Montréal.
‘Human-in-the-loop’ machine learning systems – a type of AI system that enables human feedback – are often framed as a promising way to reduce risks in settings where automated models cannot be relied upon to make decisions alone. But what if the humans are unsure?
“Uncertainty is central in how humans reason about the world but many AI models fail to take this into account,” said first author Katherine Collins from Cambridge’s Department of Engineering. “A lot of developers are working to address model uncertainty, but less work has been done on addressing uncertainty from the person’s point of view.”
We are constantly making decisions based on the balance of probabilities, often without really thinking about it. Most of the time – for example, if we wave at someone who looks just like a friend but turns out to be a total stranger – there’s no harm if we get things wrong. However, in certain applications, uncertainty comes with real safety risks.
“Many human-AI systems assume that humans are always certain of their decisions, which isn’t how humans work – we all make mistakes,” said Collins. “We wanted to look at what happens when people express uncertainty, which is especially important in safety-critical settings, like a clinician working with a medical AI system.”
“We need better tools to recalibrate these models, so that the people working with them are empowered to say when they’re uncertain,” said co-author Matthew Barker, who recently completed his MEng degree at Gonville & Caius College, Cambridge. “Although machines can be trained with complete confidence, humans often can’t provide this, and machine learning models struggle with that uncertainty.”
这项研究还引入了三个机器学习基准数据集,分别用于数字分类、胸部X射线分类和鸟类图像分类。
For their study, the researchers used some of the benchmark machine learning datasets: one was for digit classification, another for classifying chest X-rays, and one for classifying images of birds. 研究人员对前两个数据集进行了不确定性模拟,但对于鸟类数据集,他们让人类参与者表明对所看图像的确定程度:例如,鸟是红色还是橙色。这些由人类参与者提供的注释“软标签”让研究人员能够修改并确定最终结果。然而他们发现,当机器被人类取代时,性能会迅速下降。
For their study, the researchers used some of the benchmark machine learning datasets: one was for digit classification, another for classifying chest X-rays, and one for classifying images of birds. For the first two datasets, the researchers simulated uncertainty, but for the bird dataset, they had human participants indicate how certain they were of the images they were looking at: whether a bird was red or orange, for example. These annotated ‘soft labels’ provided by the human participants allowed the researchers to determine how the final output was changed. However, they found that performance degraded rapidly when machines were replaced with humans.
“We know from decades of behavioural research that humans are almost never 100% certain, but it’s a challenge to incorporate this into machine learning,” said Barker. “We’re trying to bridge the two fields so that machine learning can start to deal with human uncertainty where humans are part of the system.”
The researchers say their results have identified several open challenges when incorporating humans into machine learning models. They are releasing their datasets so that further research can be carried out and uncertainty might be built into machine learning systems.
“As some of our colleagues so brilliantly put it, uncertainty is a form of transparency, and that’s hugely important,” said Collins. “We need to figure out when we can trust a model and when to trust a human and why. In certain applications, we’re looking at probability over possibilities. Especially with the rise of chatbots, for example, we need models that better incorporate the language of possibility, which may lead to a more natural, safe experience.”
“In some ways, this work raised more questions than it answered,” said Barker. “But even though humans may be miscalibrated in their uncertainty, we can improve the trustworthiness and reliability of these human-in-the-loop systems by accounting for human behaviour.”
The research was supported in part by the Cambridge Trust, the Marshall Commission, the Leverhulme Trust, the Gates Cambridge Trust and the Engineering and Physical Sciences Research Council (EPSRC), part of UK Research and Innovation (UKRI).
然而,如果 OpenAI 无法扭转局面,面对每日高额的成本及其无法快速实现盈利的情况,Analytics India Magazine 认为 OpenAI 甚至可能在不久将来就要宣布破产。
而在 AI 芯片这个赛道英伟达更是遥遥领先,目前还没有哪家科技公司能望其项背。研究公司 Omdia 的数据显示,虽然 Google 、亚马逊、Meta、IBM 等公司也在生产 AI 芯片,但英伟达已占据了超过 70% AI 芯片销售额,并且在训练生成式 AI 模型方面有着更显著的优势。
Futurum Group 分析师 Daniel Newman 表示,很多客户宁愿等待 18 个月向英伟达采购芯片,也不从初创公司或其他竞争对手那里购买现成的芯片。即便是十多年前就开始布局 AI 芯片的 Google,有些工作也不得不依赖英伟达的 GPU 来完成。尽管芯片的价格高昂且缺货,但反而英伟达芯片可能是目前世界上成本最低的解决方案。