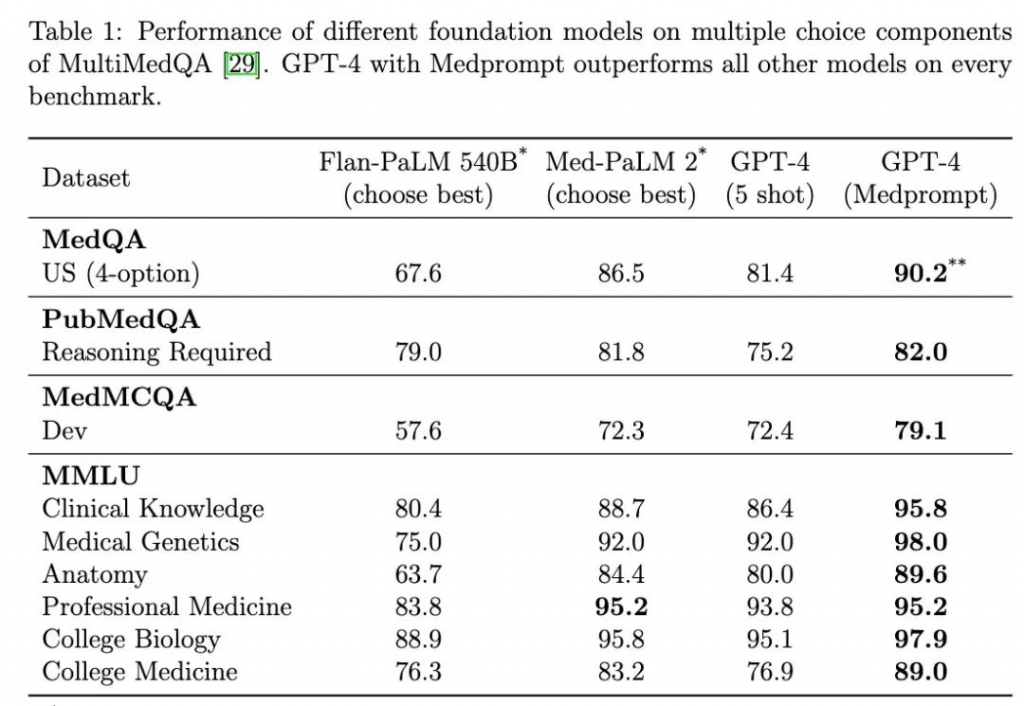
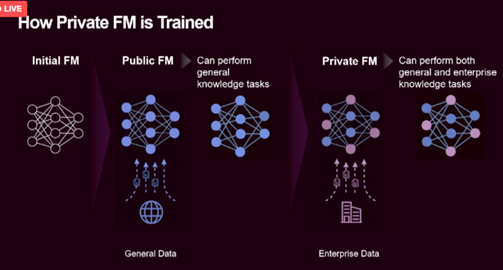
Liquid AI 是一家基于所谓的液体神经网络设计开发人工智能模型的初创公司,旨在构建一种全新类型的人工智能,被称为液态神经网络。这一创新性的技术基于液态神经网络架构,相较传统模型更小巧、可解释,且具有动态适应性。今天宣布已筹集 3760 万美元的种子资金。本轮融资由 OSS Capital 和 PagsGroup 领投,估值达 3.03 亿美元。该公司由 MIT 计算机科学与人工智能实验室主任 Daniela Rus 联合创立,致力于将其对液体神经网络的研究商业化,这是一种新型人工智能,可以比传统模型更可靠地执行某些任务,并且功耗显著降低。
值得注意的是,此次成立人工智能联盟,并没有包含OpenAI、英伟达,以及中国的企业和研究机构等 AI 行业关键的参与方。
官网显示,AI 联盟是一个由技术创造者、开发者和采用者组成的社区,合作推进植根于开放创新的安全、负责任的AI。AI 联盟以行动为导向,具有明显的国际性,致力于在 AI 技术领域加速和传播开放式创新,以提高 AI 的基础能力、安全性和信任度,并负责任地为世界各地的人民和社会带来最大利益。该联盟汇集了大量的计算、数据、工具和人才,以加速 AI 的开放创新。
具体来说,AI 联盟重点领域包括四部分:一是开发和部署基准和评估标准、工具和其他资源,以便在全球范围内负责任、可扩展地开发和使用 AI 系统等;二是开放基础模型,启用具有多种模式的开放基础模型生态系统;三是培育充满活力的 AI 加速硬件生态系统;四是支持全球 AI 技能建设、教育和探索性研究。
数据显示,截至目前,AI 联盟所有成员的年度研发经费总额超过800亿元,员工人员总数超过100万人。同时,学术机构资助的学生和 AI 从业者超过40万人。
针对 AI 联盟的成立,IBM 董事长兼首席执行官 Arvind Krishna表示:“我们在人工智能领域不断见证的进步证明了创作者、科学家、学者和商界领袖社区之间的开放式创新与协作。这是定义人工智能未来的关键时刻。IBM很荣幸能够通过 Ai 联盟与志同道合的组织合作,确保这个开放的生态系统推动以安全、问责和科学严谨为基础的创新 AI 进程。”
AMD 首席执行官兼董事长苏姿丰 (Lisa Su)则表示:“在 AMD,我们致力于通过合作推动技术进步。我们行业的历史凸显了开放的、基于标准的开发如何利用整个行业的能力来加速创新并确保技术进步产生最大的积极影响。通过在快速发展的 AI 生态系统的各个方面采用开放标准和透明度,我们可以帮助确保负责任的 AI的变革效益得到广泛利用。”
苏姿丰强调,AMD很荣幸能与其他行业领导者一起成为 AI 联盟的创始成员,并期待共同努力,确保 AI 的快速发展成为积极变革的力量。
1、流程自动化:AI Ag ents 可以自动执行以前需要手动完成的任务,从而简化和加速工作流程,提高效率。
2、任务优先级确定:通过机器学习算法, AI Ag ents 可以分析和评估任务,确定其优先级,使得工作可以更有组织性和高效性。
3、自然语言处理:AI Ag ents 利用自然语言处理技术,能够理解和解释用户的意图和需求,从而更好地与人进行交互和沟通。
4、减少人为错误:AI Ag ents 可以通过自动化和智能决策减少人为错误的发生,提高工作的准确性和可靠性。
5、数据处理能力:AI Ag ents 可以轻松处理大量数据,并从中提取有用的信息和洞察,以支持决策制定和问题解决。
尽管 AI Agents 具有众多优势,但同时也带来了一系列值得关注的挑战。一些主要问题包括道德考虑、数据隐私问题和潜在的滥用。具体如下:
1、 道德考虑:A I Agents 在做出决策和执行任务时,可能面临道德困境。例如,在自动驾驶汽车中,当发生不可避免的事故时, AI Agents 需要做出选择,这引发了道德优先级和生命价值的问题。
2、数据隐私问题:A I Agents 需要大量数据来进行学习和推断,这可能涉及个人隐私的问题。收集、存储和处理大量个人数据可能导致隐私泄露和滥用的风险,需要制定合适的隐私保护措施和法规。
3、潜在的滥用:A I Agents 的潜在滥用是一个重要的问题。例如,人工智能可以被用于制造假新闻、进行网络欺诈或进行个人监控。防止人工智能技术被恶意利用需要加强监管、教育和技术安全措施。除了上述的核心问题之外,所面临的其他挑战包括安全风险、法规、任务复杂度、数据可用性和质量、定义成功标准以及其他层面等等。
如何更好地提高 AI Agents 性能?
为了提高 AI Agents 的性能,可以采用多种技术和策略,其中包括机器学习、搜索算法和优化等。这些技术在增强各个领域的 AI Agents 性能方面具有广泛的应用,并且不断发展和演进。
1、机器学习技术
AI A gents 通过学习过去的经验、适应新情况并接收反馈,可以持续改进并提高其性能。为此,使用各种流行的机器学习技术是至关重要的。这些技术包括监督学习、无监督学习、回归、分类、聚类和异常检测等。
Google MusicLMGoogle MusicLM 是一个由 Google AI 开发的人工智能音乐生成工具。它使用一种名为“Transformer”的深度学习模型,该模型可以学习大量音乐数据中的模式和规律。然后,该模型可以使用这些知识生成新的音乐。Google MusicLM 目前仍在开发中,但已经用于生成各种目的的音乐,包括:
根据mistral.ai官网,在2023年9月27日,Mistral AI 团队发布Mistral 7B。
Mistral 7B 是一个 7.3B 参数模型:
在所有基准测试中优于 Llama 2 13B
在许多基准测试中优于 Llama 1 34B
接近 CodeLlama 7B 的代码性能,同时在代码之外在英语任务上表现良好
使用分组查询注意力 (GQA) 加快推理速度
使用滑动窗口注意力 (SWA) 以更低的成本处理更长的序列
Mistral 7B 易于对任何任务进行微调。作为演示,Mistral AI 团队提供了一个针对聊天进行微调的模型,其性能优于 Llama 2 13B 聊天。
Mistral AI 团队将Mistral 7B 与 Llama 2 系列进行了比较,对于所有模型的所有指标,都使用Mistral AI 团队的评估流程进行了重新评估,以便进行准确比较。Mistral 7B 在所有指标上都明显优于 Llama 2 13B,与 Llama 34B 相当(由于 Llama 2 34B 未发布,Mistral AI 团队报告了 Llama 34B 的结果)。它在代码和推理基准方面也非常出色。
基准测试按其主题分类:常识推理:Hellaswag、Winogrande、PIQA、SIQA、OpenbookQA、ARC-Easy、ARC-Challenge和CommonsenseQA的0-shot。世界知识:NaturalQuestions和TriviaQA的5-shot。阅读理解:BoolQ和QuAC的0-shot。数学:8-shot GSM8K with maj@8和4-shot MATH with maj@4代码:Humaneval的0-shot和3-shot MBPP热门汇总结果:5-shot MMLU,3-shot BBH以及3-5-shot AGI Eval(仅包含英语多项选择问题)
论文中对prompt的每一条为啥要这样写都给出了理由,比如AI助手agent的prompt中有一条是“Always end your solution with: Next request”,这个是和AI用户agent要新一轮的指令,这样可以确保对话自动聊下去,这才是是非常关键的一点!!!是整个机制能自动run起来的关键。
Pika Labs是一家成立仅6个月、总融资额达5500万美元、估值达到2亿美元的初创公司。他们开发了一款名为Pika 1.0的AI视频生成工具,可以轻松生成和编辑3D动画、动漫、卡通和电影等各种类型的视频。这项创新技术迅速在硅谷引起轰动,吸引了大量投资者的追捧。
Pika 1.0不仅可以根据已有素材扩展视频,生成不同高宽比的内容,还可以实时精确编辑视频内容。你只需简单地用鼠标框选、输入关键词,就能在视频中添加所需的素材,例如给视频中的狒狒带上一个帅气的太阳镜。此外,你还可以通过框选人物范围并输入文字实现换装效果。根据用户提供的视频素材和提示词,Pika 1.0能够制作出各种不同风格的动画,涵盖了现有电影和动画的大部分风格。
对此,AI Agent的作者表示,「很高兴与大家分享一项不朽的成就,我们的 Web AI 代理刚刚通过在线加州驾驶考试创造了历史,成为第一个在加州获得驾驶执照的虚拟 AI!」「这标志着一个开创性的时刻:人工智能首次完全自主地完成现实世界的人类知识任务,这是人工智能的一小步,也是人类的一大步。」虽然多少有点夸张,但不得不说,还是挺神奇的。
AI Agent完全靠自己审题、作答、并点击下一道题。对于这样成功的表现,Jim Fan也是表达了祝贺:从去年开始,一些加州居民可以在网上参加驾驶考试的笔试部分,免去了他们需要花时间去考试机构所在地的麻烦。
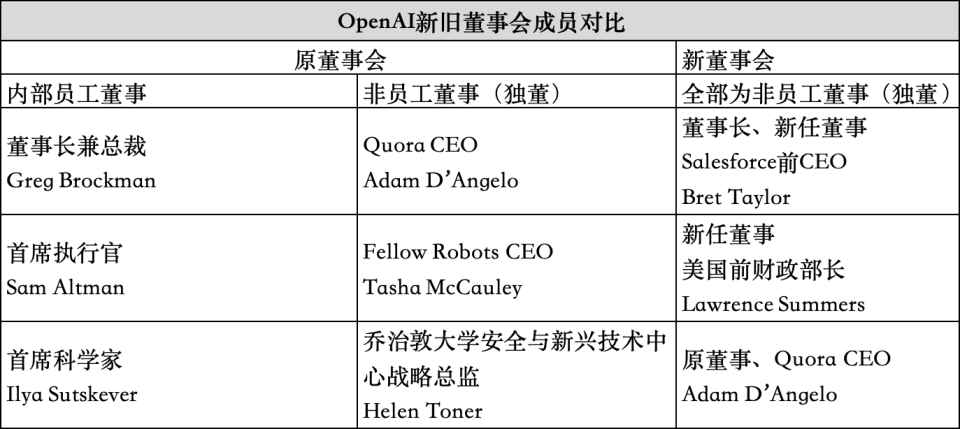
The Information的报道指出,OpenAI即将设立一个由9人组成的董事会,其中新董事会的三位初始成员——主席Bret Taylor、前财政部长Larry Summers和Quora CEO Adam D’Angelo——预计将于本周得到正式确认。目前来看,D’Angelo将是唯一从解雇Altman的六人旧董事会中保留下来的成员。在关于OpenAI董事会的问题上,微软发言人表示“我们将等待董事会正式宣布”。截至目前,OpenAI、Thrive和Khosla尚未回应置评请求。
OpenAI CEO 山姆·阿尔特曼认为,AI的大模型技术将成为继移动互联网之后最大的技术平台。而以聊天机器人为界面,加上图像、音乐、文本等多模态模型的发展,将诞生许多新一代的大型企业。在此背景下,我们现在能够看到的ChatGPT等应用只是冰山一角,隐藏在背后的是更加丰富的应用场景。当大量科学研究和技术研发都将能够通过AI来加速推进,算力(芯片)必将成为产生算法突破的基石。产业竞争不断升级,那么不可避免地,大资本也将成为影响算力竞争的基础。大模型的实现有赖于海量数据的获得和积累,计算机的算力,甚至包括芯片的竞争,都可能成为未来行业,甚至是全世界技术竞争的核心问题。
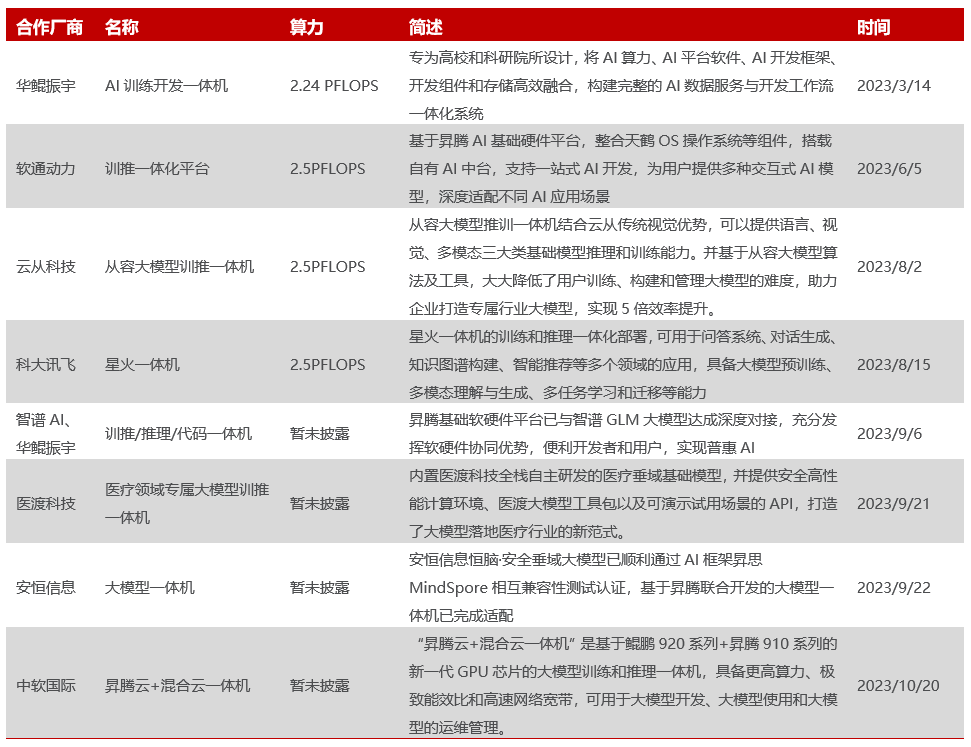
参赛队伍基于公网部署的电力行业人工智能创新平台开展模型的训练和评估。赛前签订数据保密协议,比赛过程不得将数据拷贝至私人存储介质,一经发现取消参赛资格,并追究责任。本次大赛采用的深度学习框架及算力包括华为MindSpore+昇腾910 Pro B,百度PaddlePaddle+昆仑R200,商汤SenseParrots+寒武纪MLU290。
公开资料显示,暂时接替奥特曼的CTO米拉·穆拉蒂曾先后在特斯拉、VR公司Leap Motion任职,于2018年加入OpenAI,至2022年才晋升为CTO。根据OpenAI声明,董事会认为米拉在OpenAI 发展成为全球 AI 领导者的过程中发挥了关键作用,考虑到长期任职、与公司各方面密切接触,以及在人工智能治理和政策方面的经验等因素,米拉被视作唯一胜任这一职位的人。