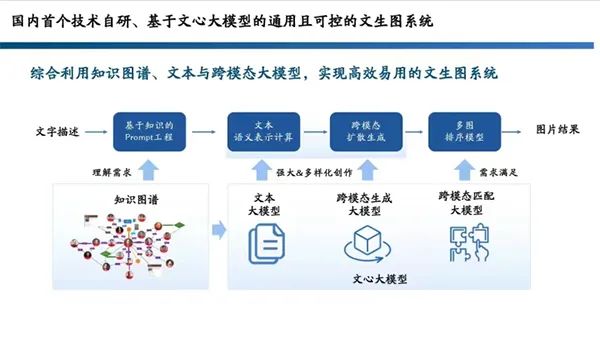
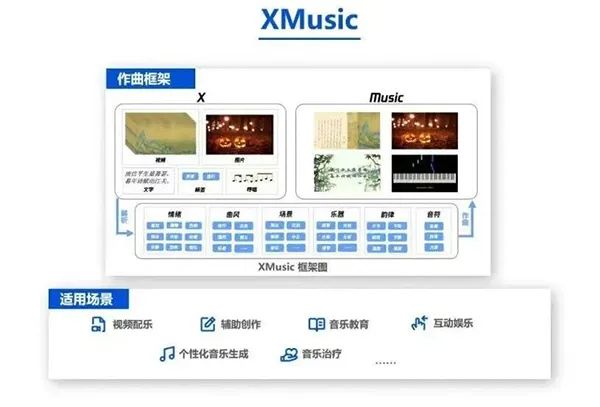
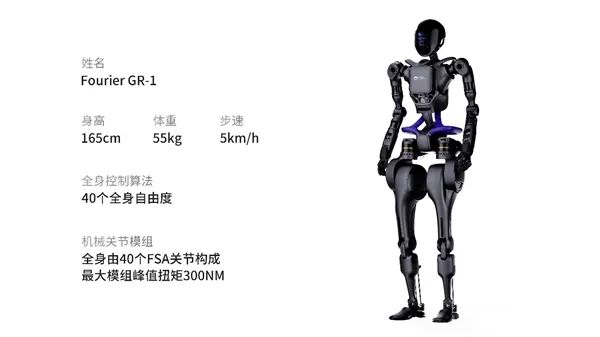
7月20日,讯飞【AI+智能家居】行业创新Workshop在深圳成功举办。本次会议,讯飞聚焦“AI赋能数字人居空间”,展示了在以场景为导向,全面布局家居空间交互AI技术下现阶段的三大成果:星火大模型已成功落地赋能地产销售助手,之后将持续推动家庭助手升级;联合生态完成“MORFEI新一代语音面板技术方案”开发落地;与中海携手研发的“离线自由说”、“方言自由说”课题实现产品批量化落地。
然而面对当今寒意阵阵的市场环境和日益内卷的行业现状,讯飞深知独木难成林,只有上下游产业方开放融合,才能破局发展。
在AIGC带来的变革浪潮中,智能家居行业也迎来了前所未有的发展机遇。在以“话行业机遇,探共生之道”为主题的圆桌论坛上,来自产业各界的大咖们共同探讨AIGC时代下智能家居行业“智变”的影响,洞见智能空间的未来发展脉络。如何把握行业趋势?如何应对风口和挑战?如何聚合生态力量探索一条共生共赢的发展路径共创未来?让我们在本次圆桌论坛中寻找答案:

主题:话行业机遇,探共生之道
主持人:王胜阳(CSHIA执行秘书长)
对话嘉宾:陈佳明——招商蛇口城市研究院院长助理、智能化研究所所长;陈立敬——星宸科技副总经理;尤中海——智引擎创始人;彭永坚——广州视声智能股份有限公司总裁;付佳毅——普华永道思略特( 上海)战略咨询执行总监。
01.AIGC带来技术革新,将给智能家居行业带来怎样的新变化?陈立敬:“AIGC将大幅提升行业效率。”
作为上游的芯片厂商,近半年来最直观的感受就是不断有客户来讨论未来大模型如何落地,云边端如何协同与算力调度,AIGC在千行百业的应用倒逼我们进行芯片的创新升级,同时谷歌等国外大厂已经开始用Chatgpt进行芯片设计,AIGC正在迅速拓宽其应用边界,无疑这将带来行业效率的大幅提升。
近几年来,我们始终和讯飞一起致力于提高行业效率,降低行业成本。自18年开始,我们和讯飞一样,也一直在思考,如何通过我们的努力,做好一款家庭中控面板,人机交互体验始终是智能家居的重点,因此我们第一款中控面板的芯片集成多核cpu,融合语音&视觉多传感器,为用户提供更自然的交互形式,通过降低NRE费用和授权费用,实现用户开发门槛的降低和成本管理的极致,而AIGC的发展将会成为行业降本提效的新引擎,助力我们在这条路上走得更稳更远。
02.面对家居空间内不同群体的受众,如何精准把握用户的需求点?付佳毅:“AIGC的自主学习能力能让住宅拥有大脑,精准把脉用户需求。”
智能家居行业向来是技术驱动型的,AIGC是个很好的转型点,但仍需过程。正如移动互动网时代的发展路径,3G到4G的跨越是源于pc端app转移至手机端,用户开始习惯用手机上网;4G到5G的跃升是源于短视频等行业的内容井喷,用户需要更低廉的上网流量和更快的上网速度。可以看到技术创新伊始,无法预料到未来的应用场景会发展成怎么样。
正如现在智能家居的语音技术,虽然比其他按键、触屏等交互方式先进,但仍然存在要站到屏面前进行对话的机械之处。因此我们需要挖掘客户需求,探索更便捷的应用场景,用户对于应用场景的喜好改变才能倒逼技术普及。例如中控屏的陪伴式场景,老人并不是需要触摸屏和语音交互,他们需要的是子女的陪伴。如果我们通过AIGC技术创造出子女形象的数字人,并且在设备中录入子女声音的声纹,以这样的形式做交互,或许能比普通的智能语音屏更能切中用户需求。
数字化可以重新定义家居场景,就像特斯拉用一个统一的控制单元重新定义了智能汽车,颠覆了仍旧坚持传统逻辑的老牌汽车;住宅也可以以统一的数字化生命体做反应,将方方面面的数字化结构做整合,在能耗管理、环境管理、需求关切上,通过AIGC做人性层面的升级,这将远超传统数字化控制能解决的问题,AIGC的自主学习能力能让住宅拥有大脑,面对家居空间内不同群体的受众,始终在思考如何与用户更好地进行互动,精准把脉用户需求。
03.与传统家居相比,AIGC赋能的智能家居如何在用户的全生命周期中提供更好的保障和服务?彭永坚:“AIGC将推动研发转型,低成本高效率实现用户体验升级。”
面对AIGC带来的新机遇如何做好产品定义是我们一直在思考的问题。过去很多年,智能语音是个很火的窗口,尽管智能汽车的语音已经发展得非常成熟,但地产始终没有成功案例。一个原因是地产对于智能家居装配的费用投入不足;另一个是如果要为了提升用户体验替换技术服务商,背后将是一系列产品设计、产品结构、声音美学、软件的替换,带来成本的增加和研发的难度,而AIGC的出现能大幅提升研发效率,推动研发转型做更专业更聚焦的工作,低成本高效率地实现用户的体验升级。尤中海:“在变化的环境中,找到用户体验的确定性。”
现在所有的技术方向,都是让21亿人生活得更爽,让60亿人过上体面的生活,如何打造更懂用户需求的数字空间,需要产业链的共同努力,也需要不受缚于固有技术。
就像我们针对亚非拉无法建立有效的网络体系的现状,提出了一项全新的服务方案:基于新型能源结构打造全新的通信底层架构,并以全屋直流电满足低压需求。不同于网络这个虚拟的世界,数字空间是固定的,我们要在不断变化的市场环境和不断更迭的技术发展中,找到用户体验的确定性,真正让技术被获得。
04.下一个行业千万级出货量的品类集中在哪几个方向?
陈佳明:“绿色、健康、科技是未来的产品需求方向。”
16年我们就提出了“云管家“概念,尽管上层营销推广得非常好,但落地应用层面还是积累了非常多的经验教训。就像智能汽车颠覆传统汽车的价值点是无人驾驶一样,我认为未来住宅颠覆传统住宅的价值点,一定是“管家”。不同于我们现在的“家庭管家”,在设定、唤醒前还是需要输入命令词、场景模式等,AIGC的赋能将大大降低使用者的门槛。
今年我们做了项调研,统计了居住空间中最令消费者记忆深刻的产品TOP3,它们分别是Wi-Fi、集成控制面板和中控屏。中控屏作为智能品类中用户互动最多的产品,同时也能作为家和小区的连接器,我十分期待它与AIGC融合后的可延展性。
“绿色”、“健康”、“科技”是行业未来的三个关键词。绿色是全人类的需求,能节约能源的事是优先的事;健康是客户的强需求,除了安全需求,健康是所有人的共识问题;日新月异的科技迭代速度,大家都在观察AIGC能为行业带来什么变化。因此如果未来有一款搭载了大模型的产品能结合绿色、健康,同时配合低廉成本做成普适性的东西,极大可能就是新的产品方向,但具体是什么样的产品形式,需要大家共同思考和努力。
技术创新的脚步不会停止,用户对美好生活的向往亦不会停止。MORFEI作为讯飞全屋智能细分赛道下的专业选手,坚持致力于用人工智能推动智能家居行业高质量发展,联合产业链合作伙伴,以技术赋能提升用户体验,共生共赢共襄未来。
想要做大模型训练、AIGC落地应用、使用最新AI工具和学习AI课程的朋友,扫下方二维码加入我们人工智能交流群