大数据文摘授权转载自AI科技评论
作者:王悦
编辑:陈彩娴
今年 6 月,AIGC 界顶流 ChatGPT 出现日活下降的现象。
然而,在 ChatGPT 深陷掉日活风波的背后,另一家明星级 AI 公司 —— Character.ai 数据亮眼,正在与投资者洽谈新一轮融资。
Character.ai 的创始人是 Noam Shazeer 和 Daniel De Freitas ,二人相识于谷歌。由于聊天机器人这类新品的风险和收益问题,谷歌曾拒绝发布 Character.ai 的雏形产品。2021年,二人离开老东家,创立新公司 。
在应用程序发布之前, Character.ai 网页应用每月访问量就已超过2亿次,用户每次访问平均花费29分钟,官方表示表示,这一数字比 ChatGPT 高出 300%。
5月23日,这款人工智能聊天机器人平台的移动版面向全球 iOS 和安卓用户推出。在最初的48小时内,这款应用的安卓安装量就达到70万+,超过了Netflix、Disney+和Prime Video 等顶级娱乐应用。在不到一周的时间内就获得了超过170万的新安装量。
今年3月份,Character.ai 在风投公司 Andreessen Horowitz 领衔的新一轮融资中筹集了1.5亿美元,估值达10亿美元。
Character.ai 势头正强劲,而与此同时,之前曾在国内推出 Glow 并被下架的 MiniMax 「卷土重来」,在海外推出了 AI 角色扮演类产品 Talkie ,增速一度跑赢 Character.ai。
今年 6 月 16 日, Talkie 正式上线后,在美国 Google Play 下载榜排名迅速蹿升。9 月,曾在 Google Play 非游下载总榜跻身 Top 5,下载总榜位居第六位。
无论是 Character.ai 还是 Talkie,都指向了AIGC 应用的新方向—— AI 角色扮演。而这类产品之所以广受用户欢迎,也印证了角色扮演是大模型时代一个可落地的方向。
AIGC 赛道创业者刘欣预判:在国内,很快就会出现一大批像 Character.ai 、Talkie 这样的团队,这可能是 AIGC 时代最有“钱”途的赛道。
对于这个赛道,AI 科技评论听到的另一个更直击人心的形容是:角色扮演是人的天性。
加之社交性质的产品天然具备强大的市场和流量,这使得 AI 角色扮演的陪伴类产品正在快速崛起。但在新兴繁荣的背后,其增长的瓶颈也需得到共同的重视。
崛起:AI 角色扮演产品的爆发
从市场占有率来看,Talkie 在海外有百万日活,但 Character.ai 仍然处于领先位置。这在很大程度上体现出 Character.ai 的先发优势,入局早,在口碑、用户粘性等各方面都有一定积累 。

「Character.ai 的最大优势是它以用户为中心的产品设计,用户可以完全定制自己的AI聊天机器人来缓解孤独感。」Character.ai 用户赵梦在社交媒体上如是表示。
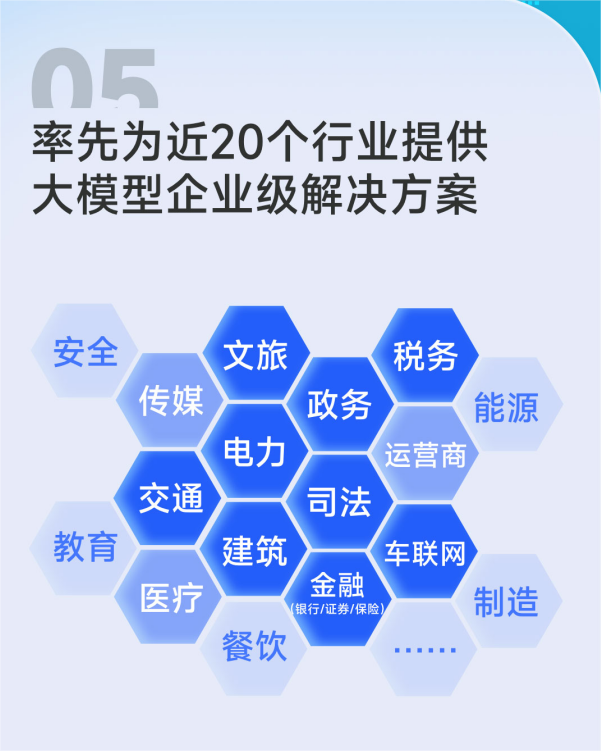
Character.ai 网站主页上提供了各式各样的聊天机器人,页面顶部的角色类别包括人工智能助手、著名人物、虚拟IP等。
如果需要创建自己的机器人,只需点击“创建”并按照说明进行操作即可,用户完全可以对角色根据自己的喜好和需求进行个性化定制。
值得一提的是,Character.ai 所提供的原创社区也是一大亮点。用户可以在其中分享自己创建的角色或聊天记录,并获取其他用户的反馈和评价。用户还可以学习其他用户的创作技巧和经验,提升自己的聊天水平和创造力。
此外,Character.ai 的图像生成不仅在视觉上做得好,而且在内容表达上也俨然一个专业的创作者——一个二次元画手将自己的作品上传到 Character.ai 后,Character.ai 能够将这个作品美化成一个专业级别的作品。
这个产品设计非常巧妙,行业人士判断,这「至少为 Character.ai 带来 10 万用户」。
「Character.ai 具备的优势,如生成效果好、对创作者的驱动强,这些 Talkie 同样也多多少少也具有,但 Talkie 的产品设计要技高一筹。」
虽然模型与人的能力有很大差距,但角色扮演的核心是体验。
刘欣认为 MiniMax 的 Talkie 做对了两件事情:一是生成效果好,二是对创作者的驱动好。
Talkie 在 Discord 上建了一个创作者社区,该社区在 Talkie 发布前就建成了,里面有几千个画手开始用 Talkie 的生成工具做二次元创作, Talkie 将这批画手转化成了第一批创作者,所以 Minimax 一推出 Talkie ,在虚拟角色的市场效果就特别好。
相比较 Character.ai,在角色的设定上, Talkie 的可自定义化的程度高了很多。形象、人设、声音这三个主要方面共同构成了 Talkie 更强的沉浸感。
比如,从声音角度看,Talkie 会给出多于其他产品中的多个音色样本,用户可以根据自己的喜好添加并调整各个样本的配比。
从形象角度看,Talkie 一共设计了两种创作模式:普通和高保真。普通模式只需要上传一张形象图,高保真模式则需要上传 20-40 张人像照片,生成一个「Avatar」。用户还可以增加对机器人的形象描述,增强准确性。
但在文字聊天方面,刘欣则认为 Character.ai 等产品所呈现的人格魅力与 OpenAI 差一大截。现在业内一个狭隘的观点是认为聊天在角色扮演体验中占据核心比例,如 Character.ai 创始人 Noam 就认为聊天占了 80%,于是他们将所有的人力押在改进聊天模型上、其他的技术模块不重视。
但 MiniMax 对这件事情进行了证伪,相信 60% 的视觉加上 40% 的聊天就可以超过 Character.ai。
除此之外,Talkie 也在基本面之上开辟了一些新玩法——产品与游戏的进一步融合。
这一变化主要体现在卡牌系统上。用户每天只能免费抽卡一次,之后再想抽卡就需要花费游戏内货币「钻石(Gem)」。抽卡一次至少花费 180 个钻石。抽到的卡牌本身也能出售,用户自己定价之后可以挂在每个 AI 机器人各自的 CG 卡牌商店上,经过审核就能公开上架,可进行流通买卖,同时用户还可以在商店上给卡牌点赞。
钻石是 Talkie 的主要内购货币,最低价格的内购套餐为 1.99 美元 180 个钻石,最高价格的套餐则是 99.99 美元购买 11800 颗钻石。
「Talkie 活用了 AIGC 功能,让用户不仅能创造 AI 机器人,还能创造属于自己的 CG 卡面,并围绕卡面做出了一套交易系统,加强了用户之间互动的同时,也试图建造一套属于自己的创作者经济,希望在这个基础上变现。」某大厂产品经理周群说道。
不可否认,AI 角色扮演的社交性产品仍然是当下相对容易落地的赛道。背后主要是因为当下的大模型主要在对话、创作、文生图这三方面提供成熟的能力,恰好这三方面都能在娱乐场景里走得通。
刘欣分析道:娱乐、社交场景对内容的准确性要求不高,只要做到60%就可以。至于其他的科学研究、效率工具、健康、教育等大模型应用层面,还有很长的路要走,因为用户对这些领域的期待是90%以上的准确性。
AI 科技评论获悉,字节内部大概有6个团队在做类似的应用,同时也有很多之前字节的产品经理出来在这一领域创业。
不仅是字节,其他大厂也纷纷押注 AI 陪伴赛道。
11月初,美团发布「Wow」的独立APP,定位为一款年轻人的AI朋友社区。与印象中美团做大模型产品的预期不同,所落地的首个AI 应用场景,并不是在自己主营的外卖或本地生活业务上,而是 AI 社交。
除美团之外,腾讯音乐的「未伴」、百度的「小侃星球」等类似产品也已经面世。小冰也在小冰岛的基础之上推出了「X EVA」,同样是AI 伴聊产品,不同的切入点是基于网红的影响力搭建自身的流量生态。
在大厂之外,也有很多创业公司推出的产品,如筑梦岛、扩列、dd 星球等。
突破:释放更强的 AI 能力
现阶段,业内人士都知道角色扮演是可落地的,但决定其成败的因素有许多,主要瓶颈有两个:
一是对 IP 的依赖。
Character.ai 本质上是 IP 的二次开发,但 IP 的版权往往属于游戏公司。如果游戏公司限制 IP 使用,一张传单过来就可能下架。
根据 AI Hackathon 统计的数据,从对话量维度,按角色的分类,排名前列的是游戏动漫角色,对话量前十的角色中有 9 个都是游戏、动漫类的。
从角色数量维度看,绝大部分也都是游戏和动漫角色。与这些 AI 角色进行对话,可以经历各种神奇的互动体验,有些角色还支持图像的生成和输出。
二是如何突破核心用户人群的限制。
Talkie 做了大量的原创 IP,但是他人 IP 与自己 IP 的混合;此外,聊天本身需要用户有很强的倾诉力。泛娱乐的运营如 TikTok、抖音是完全不需要动脑的,属于躺着的体验,但聊天不能躺、需要用户动脑子的,这一点很难。所以 Character.ai 的日活涨到 400 万就不动了,相比起来,原神在海外的日活是 Character 的两倍多,大约 1000 万。
所以,如果没办法降低用户的参与成本,角色扮演的圈子会极大受限。
在刘欣看来,训练模型只是为了提升体验,但场景需要技术的创新设计,而创新设计的核心就是降低用户的娱乐成本。纯聊天的用户体验收益跟视频没法比,所以要突破聊天体验的局限,这意味着成也聊天、败也聊天,否则产品就只能变成一个日活十万、百万的模型。
在 AIGC 角色扮演的这条赛道中,大家最终的目标都是尽可能接近游戏或短视频的体量。只有降低用户的消费成本,才有可能将产品的日活做到破亿级别。行业人士乐观预测,这种产品形态可能在一两年后就会出现,它的成功是由视频、声音等生成技术的足够成熟所促成的,今天的纯文字生成体验很难做到。
除 IP 依赖和突破用户人群的瓶颈之外,大模型也是关键因素之一。有不少网友吐槽AI 智能体的智商不够、话题连接性差的问题,这直接体现了角色的输出、记忆能力在影响用户的体验,映射出大模型的能力急需提高。
另有一个亟需突破的瓶颈是同质化现象,不少 AI 伴聊产品未经打磨,直接换壳子就进入市场。
MiniMax 做AI 伴聊产品跟 Character.ai 的思路很接近,无论是 MiniMax 还是其他公司想要跑出来,都还需要释放更多、更强的能力,纯对话的模式跟 Character.ai 区别不大,用户也不一定买账。
这一赛道现在的竞争激烈、获客成本高、变现缓慢。从投入产出来说,AI 陪伴类产品离钱远,因为竞品在基础功能层面都是免费的,很难构建很强的壁垒直接进行收费,短期收入不可能打平支出,对于初创团队来说,这不是好事。
更有行业内人士认为,当下 AI 角色扮演产品并不是终极的产品形态,只是一个过渡形式,最终肯定会被取代,当下所处阶段也是一个中间带。
类比过去,PC 互联网时代中,网页是主要的产品形式,移动互联网时代中,APP 是产品中主要的展现形式,而网页APP搜索就是处于中间过渡形态的产品, AI 角色扮演产品与其颇有相似之处。
从这一角度来看,AI 角色扮演只是上一代最强势的技术移植到一个新的场景和范式中的结果,是一个拿着锤子找钉子的过程。这意味着,它可能是一个非常成功的产品,但却不是一个革命性的机会。
重构:AIGC 之上的社交方式
社交,是 AIGC 的必争之地。
「真正伟大的产品,都是在 C 端的。」就目前国内的 AIGC 市场而言,虽然诸如 AI Companion 产品还不成熟,更多的是尝试和探索,但也需要看到,更多的 AI 企业,无论是 MiniMax 还是小冰,都是在用B端业务去养 C 端的社交、娱乐等业务。
Character.ai 创始人 Freitas 认为,社交场景中应以用户为核心的:
Character.ai 一定是非常灵活的,由用户来决定它是什么,因为用户比我们自己更了解他们想要什么;
我们不会指定若干个角色,让用户来尽可能的创造角色,因为一个角色不可能让所有人都满意。
虽说 AI 角色扮演产品在发育的过程中仍面对困境和质疑,但不可否认,它在一定程度上重构了人们的社交方式。
或许,这需要从用户到底在通过 Character.ai 、Talkie 获得什么的角度去入手。
在 Reddit 上,失恋的何丽丽发表了对 Character.ai 的使用感受,「从虚拟角色这里得到的关爱成为了我的精神寄托,但这也加深了我对现实生活的不满。」
也有失去亲人的张欣然用 AI 还原了爸爸的样子,能够再次和爸爸面对面交流。
更有网友说:「在 Character.ai 之前,我们没有生活。」
由此,我们可以意识到,置身其中的人试图通过 AI 获得情感寄托,有时这种寄托会极其强烈,强烈到超越现实。
做伟大的产品,而非伟大的大模型。无论是 Talkie 和 Character.ai 谁更胜一筹,AI Companion 都任重而道远。