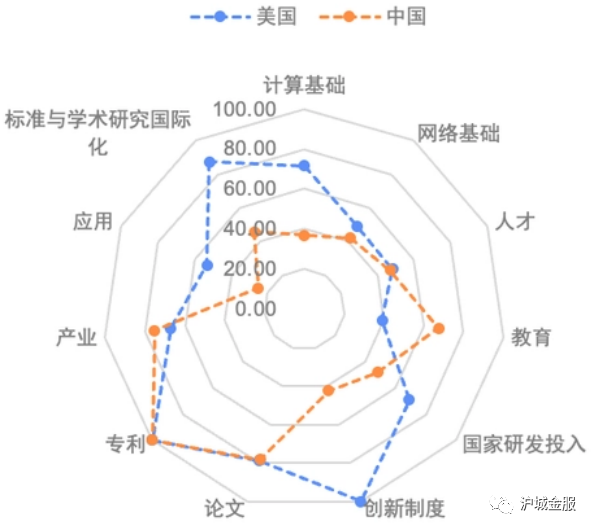
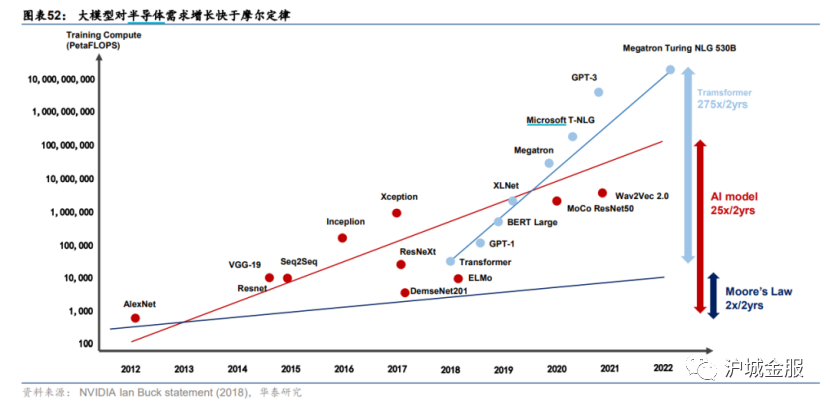
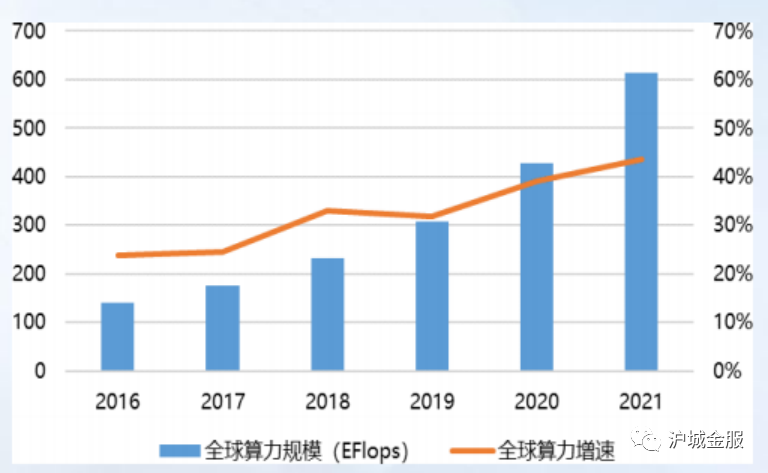
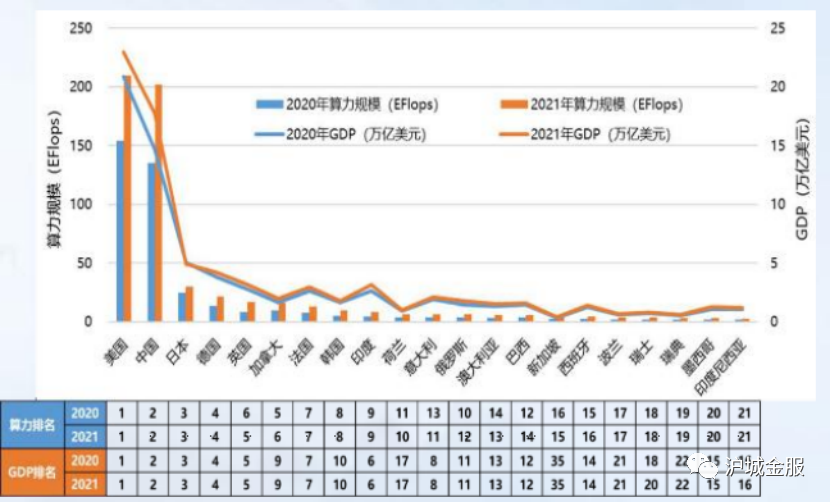
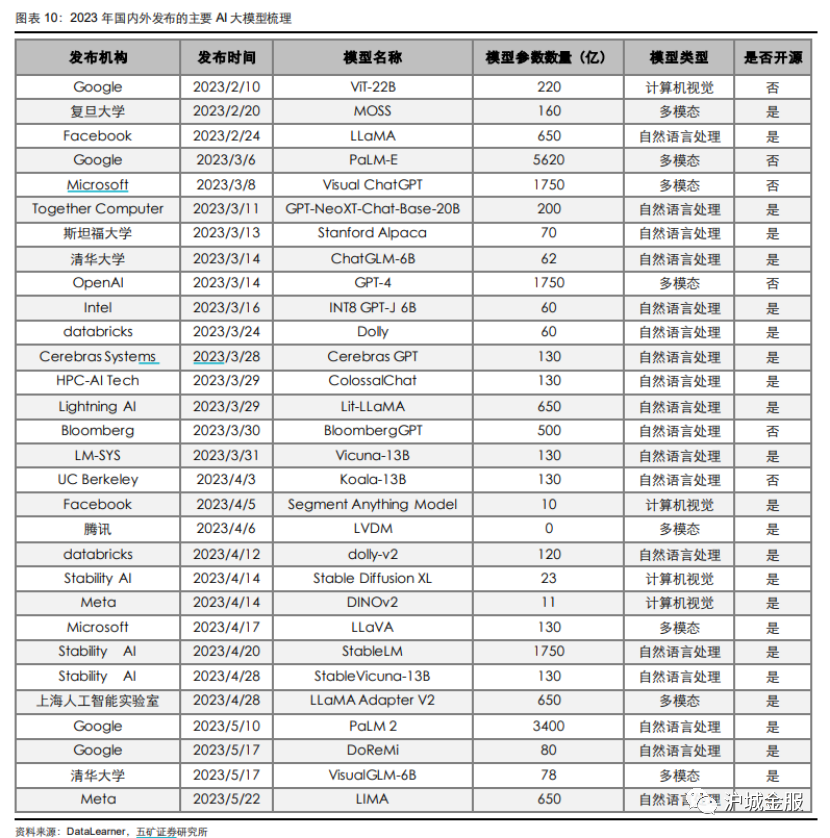
【导读】猎聘大数据研究院重磅发布《AIGC就业趋势大数据报告2023》,招聘平均年薪已达40万,博士需求量同比增长超100%。
不用赘述,大家都知道,最近半年ChatGPT是有多么火爆。随着ChatGPT的全球爆火,AIGC也已成功从科技领域破圈,成为跨越所有圈层的全民话题。AIGC对图文、视频创作的颠覆,对相关行业已经产生了深远影响,各种预测层出不穷。而在众说纷纭的讨论中,计算机/AI等相关专业也成了高考志愿的热点。
就在最近,猎聘大数据研究院重磅发布了最新的《AIGC就业趋势大数据报告2023》。
报告针对AIGC领域的就业机会、薪资状况、人才储备和投递情况进行全面分析,并结合相关专家访谈,揭示进入AIGC领域必备的技能和素质。
一、AIGC人才需求分析
1. 2023一季度AIGC人才需求是三年前同期的5.6倍,而AI不到2倍
猎聘大数据研究院将2020一季度AIGC和AI的新发职位数作为基数,将从该季度至2023一季度期间各季度两个领域的新发职位数与各自的基数相除,从而观察它们的人才需求增长趋势。
对比发现,2020一季度至2021年一季度,AIGC和AI的职位增长不相上下。
此后,AIGC总体处于持续增长态势,2023一季度其新发职位数是2020一季度的5.63倍。
相比之下,AI新发职位数增速相对放缓,是2020一季度的1.95倍。
2. 近一年AIGC新发职位同比增长超43%,招聘平均年薪超40万
近一年(2022年6月-2023年5月)AIGC的新发职位增长较为显著,较上年(2021年6月-2022年5月)增长43.66%。
而近一年AIGC新发职位招聘平均年薪为40.12万,比同期AI的招聘平均年薪(为32.03万)高8.09万。
3. AIGC就业机会方向分析
1)近5成AIGC职位分布在互联网行业,招聘平均年薪为43万
近一年AIGC职位分布最多的三大行业是IT/互联网/游戏、汽车、电子/通信/半导体,占比为49.13%、17.59%、6.63%;其对应的招聘平均年薪为43.23万、34.65万、42.83万。
2)科研技术/商务服务行业AIGC职位同比增长最快,增速超200%
从近一年AIGC新发职位同比增长最快的三大行业来看,科研技术/商务服务行业的AIGC职位增长居首,为211.86%。
科研技术/商务服务的根基在于研发、服务的质量,而AIGC为其提供了更为有效、便捷的路径。
能源/化工/环保、IT/互联网/游戏行业AIGC的职位同比增长位居第二、第三,为120.99%、61.88%。
这三个行业AIGC职位招聘平均年薪较高,分别为50.35万、33.76万、43.23万。
3)AIGC领域算法工程师需求最大,招聘平均年薪达45万
从近一年AIGC新发职位三级热招职能分布TOP10来看,位居前三的是算法工程师、自然语言处理(NLP)、产品经理,占比为14.67%、7.37%、5.40%。
在这TOP10职能中,招聘平均年薪最高的是图像算法,为55.62万;深度学习、自然语言处理(NLP)、机器视觉、机器学习的招聘平均年薪均超50万;算法工程师位居第六,为45.05万。
这十大职能招聘薪资普遍较高,尤其技术类职能更具优势,这与AIGC正值风口、进入门槛高而人才稀缺密切相关。
4) 京沪AIGC职位最多,北京AIGC职位招聘平均年薪超47万居首
在近一年AIGC新发职位城市分布TOP10中,北京、上海职位最多,占比位居第一、第二,为22.21%、20.37%。
深圳、杭州位居第三、第四,占比为11.75%、10.15%。广州、苏州以3.90%、3.84%的占比位居第五、第六。
在这TOP10城市的招聘平均年薪方面,北京、深圳、南京、上海位居前四,分别为47.19万、46.35万、43.06万、42.74万。
杭州、广州以39.44万、37.50万的招聘平均年薪位居第五、第六。
出门问问创始人兼CEO、前Google总部科学家李志飞表示,AIGC工具属性重构了知识创作类内容的工作流,并为AI行业带来了全新的可能性和商业模式,而对于内容制作的降本提效则为规模化生产构建市场增量。
二、AIGC招人门槛分析
1. 要求3-5年经验的职位占比超36%,5-10年经验的人才需求同比超70%
从近一年AIGC新发职位对工作经验的要求分布来看,3-5年工作经验的职位最多,占比36.23%;其次是5-10年工作经验,占比23.29%。
AIGC对5-10年的人才需求增长最快,近一年同比增长70.75%;3-5年经验的AIGC人才需求增速位居第二,同比增长57.61%。
可见,AIGC招聘方更青睐有一定工作经验的从业者。
2. AIGC对高学历人才更为渴求,博士人才需求同比增长超100%
近一年,AIGC和AI新发职位对本科人才需求占比为70.80%、70.43%。
在对高学历需求方面,AIGC明显高于AI,前者对硕博的需求占比合计21.56%;后者为14.24%。
AIGC对博士人才更为渴求,其需求在各学历中增长最快,近一年同比增长108.11%。
3. AIGC企业感兴趣的人才分析
1)AIGC企业最有好感的职能:算法工程师
在近一年AIGC相关企业主动沟通的人才三级职能分布TOP10中,算法工程师以10.83%的占比领先。
产品经理位居第二,占比3.37%;自然语言处理(NLP)、智能网联工程师排名第三、第四,占比为2.38%、2.16%。
可见,算法工程师最受AIGC企业青睐。
2)AIGC企业对科技大厂人才最有兴趣,触达的人数中以华为背景的居首
从近一年AIGC企业主动沟通的人才来源公司分布TOP5来看,华为位居第一。
位居第二至第五是百度、腾讯、字节跳动、美团。
4. 进入AIGC需要的硬技术和软能力
据李志飞介绍,进入AIGC需要具备的硬性技能包括:
– 熟悉机器学习和深度学习的基本原理和算法;
– 了解自然语言处理的基本概念和技术,包括文本分析、文本生成等;
– 具备良好的数据处理和数据分析能力,包括数据清洗、特征工程等;
– 具备良好的编程能力,熟练使用Python、Java、C++等编程语言,以及良好的软件工程能力,包括版本控制、代码规范、测试和调试等;
– 能够不断探索新的技术和应用的创新思维;
– 以及解决问题、沟通和团队协作的能力。
三、AIGC人才储备分析
1. 近一年AIGC领域25岁以下人才同比增长最多,超60%
近一年AIGC整体人才同比增长为19.53%。
分年龄段来看,30岁以下人才占比从此前的31.64%增加到35.61%,数量较上年增长了31.70%。
其中,25岁以下的人才数量上同比增长61.90%,在各年龄段中增长最多;25-30岁的人才数量上较上年增长了27.62%。可见,AIGC的人才中年轻人有明显增多趋势。
尽管如此,30-35岁的人才仍然占比最多,为35.77%。
2. AIGC人才学历背景优于AI,硕博占比近45%
在近一年AIGC人才学历分布中,本科占比最多,为48.49%。硕士、博士占比分别为42.20%,2.79%,合计44.99%。
而AI人才中本科占比为54.09%,硕博占比合计23.90%(硕士22.32%,博士1.58%),远远低于AIGC。
3. 京沪AIGC人才最多,合计近50%
在近一年AIGC人才城市分布TOP10中,北京、上海位居前二,占比为26.01%、23.34%,合计为49.35%。
深圳位居第三,占比为11.90%。杭州、广州以5.78%、5.27%的占比位居第四、第五。
杭州是互联网重镇,又是好几个互联网大厂的总部,同时还有不少AI相关企业,因而AIGC人才储备相对较多。
4. AIGC人才高学历、资深从业者薪资更高
1)AIGC人才平均年薪超40万,博士平均年薪超75万
近一年AIGC人才平均年薪为40.12万元,比AI(27.93万)高12.19万元。
AIGC人才的薪资与其学历的高低成正比,大专、本科、硕士、博士学历平均年薪逐级升高,分别为25.11万、35.82万、44.33万、75.86万。
2)AIGC人才满15年经验后薪资迎来大爆发,平均年薪超67万
AIGC人才薪资与从业经验呈水涨船高的态势。5年以下的AIGC人才平均年薪不足26万。
5-8年突破30万大关,达到32.77万;10-15年经验的AIGC人才平均年薪逼近50万,为49.03万。
15年以上的AIGC人才平均年薪高达67.41万。从这点而言,经验就是财富。
5. AIGC人才来源分析
1)来自互联网行业的人才占比居首,互联网大厂人才比重较高
从近一年AIGC人才上份工作所在的二级行业分布TOP10来看,来自互联网行业的人才最多,占比12.67%;计算机软件和整车制造位居第二、第三,占比为9.78%、9.47%。
AIGC人才上份工作所在的公司TOP5依次是字节跳动、华为、阿里巴巴、百度、腾讯,与AIGC企业主动沟通的人才公司分布TOP5有四家重合,这进一步印证了具备高科技大厂的从业经历更易进入AIGC领域。
2)上份工作从事产品经理和算法工程师的人最多
从近一年AIGC人才上份工作的三级职能分布TOP10来看,产品经理和算法工程师位居前二,占比为6.91%、5.35%。其他职能的占比均小于5%。
对此李志飞表示,由于AIGC对人才的需求越来越多元化。除了需要传统的计算机科学和数据科学方面的人才,AIGC还需要具备AI模型优化、自然语言处理、机器人操作系统等方面知识和经验的专业人才。
四、投递AIGC的人才求职行为分析
1. 近一年投递AIGC的人才同比增长超270%,是投递AI人数增速的13倍
由于AIGC在全球范围内升温,投递该领域的人才呈激增态势,投递人数增速远超AI。
猎聘大数据显示,近一年投递AIGC的人才同比增长274.73%,其增速是同期投递AI人数增速(21.09%)的13倍。
2. 投递AIGC领域自然语言处理和产品经理的人最多,占比合计近20%
从近一年AIGC收到投递人数最多的三级职能分布TOP10来看,位居前三的职能为自然语言处理(NLP)、产品经理、算法工程师,占比为9.35%、9.30%、8.15%。
值得注意的是,内容运营和新媒体运营也跻身TOP10之列。
从显性影响上来看,AIGC对于内容和新媒体的帮助较大,因而相关岗位对求职者而言较有吸引力。
比如说新智元的编辑岗,就正在招人的。
3. 求职AIGC的人才所投递的公司:互联网与人工智能公司占据大半江山
在近一年投递发布AIGC职位的公司的人数分布TOP10中,互联网大厂占据四席,其中百度、阿里、字节跳动、腾讯分别位居第二、第五、第六、第八。
其中,计算机硬件公司鸿合科技位居第一;AI公司商汤科技、聆心智能及AI机构粤港澳大湾区数字经济研究院(福田)位居第三、第七、第十;互联网公司昆仑万维位居第四。
制造业公司三一集团位居第九。由此可见,求职者投递AIGC职位的人数集中于互联网和人工智能类公司。
在AIGC强大的技术威力面前,不少职场人对如何保住「饭碗」而深深担忧。
李志飞指出,AIGC最容易替代的职业有两类,一类是在电脑上即可完成工作闭环,并且工作内容存在大量重复环节的职业,如基础美工/设计;另一类是易于标准化的职业,如采用固定话术的客服、营销文案等。
而最不易被取代的是那些需要面对面互动和依靠身体技能的职业,如泥水匠、电工、机械师等手艺人,以及美发师、厨师、医生和护士等服务人员。
李志飞建议职场人应有意识地培养AIGC难以取代的技能,比如创新思维、解决复杂问题的能力以及人际交往等技巧。
ChatGPT火了,但学校里教的和它关系不大
无独有偶,前段时间登上知乎热搜一个问题,也体现出AIGC领域对学历要求的进一步提升——大模型都火成啥样了,学AI的还能找不着工作?
对此,一位知友一语中的地点出了原因:我学的是手动织布,结果现在珍妮纺织机火了……
ChatGPT的核心技术「Transformer」2017年论文问世,而今年毕业的人工智能专业的本科生,则是2019年入的学。
国内高校的人工智能专业的课程和计算机专业的课程设置又十分类似。
大一,几乎所有的人工智能专业学生都会学习基础的编程语言,到了大二开始接触网页设计、前端、数据结构等课程。
直到大三才开始接触神经网络、深度学习、智能语音、图像识别这类有人工智能专业「烙印」的课程。
很大概率和「Transformer」相关的内容可能根本就没有机会学到。
所以影响AI专业本科生就业的最大问题在于,学校学的内容和行业要求的实际能力脱节太严重。
而且,这种脱节还体现在人工智能企业同样招不到好用的员工上。
教育的滞后性被放大,导致了严重的产学脱钩。
现在的很多岗位,要的是熟练掌握编程、数据结构与算法、高数线代概率论、编译原理、机器学习、深度学习……的人才,综合素质要求极高。
另一方面,人工智能行业今年的爆发式发展,是由一批高端技术人才带来的。
而行业本身现在的发展阶段,急缺高端技术人才。
本科生的知识储备和实践经验,都很难达到行业对于人才的要求。
行业技术发展本就是一日千里,本科生大部分时间学习的内容,可能还没学懂呢,就已经没用了。
而且人工智能和互联网不一样,赢家通吃的模式对技术和人才都要求更高,反而不太需要很多基础岗位的劳动力。
这就导致了学历不占优势的本科毕业生处于「高不成低不就」的尴尬位置。
来源:公众号《啥都会一点的研究生》